Uptime é o período de tempo em que um sistema, serviço, dispositivo, aplicação, rede ou plataforma permanece disponível e operacional. De forma simples, informa aos usuários por quanto tempo algo funcionou sem interrupção. Quando um site está acessível, um servidor está em execução, uma plataforma de comunicação está online ou um dispositivo de rede continua funcionando normalmente, esse período de funcionamento é contabilizado como uptime.
O uptime é um dos indicadores de confiabilidade mais importantes em ambientes de TI, redes, telecomunicações, serviços em nuvem, sistemas industriais, sites, data centers, plataformas de segurança e comunicação empresarial. Ele ajuda as organizações a entender se seus sistemas são confiáveis o suficiente para suportar as operações diárias. Um serviço com alto uptime fica disponível na maior parte do tempo. Um serviço com baixo uptime pode sofrer interrupções frequentes, quedas, reinicializações ou períodos de indisponibilidade.
Na operação real, o uptime não é apenas um número técnico. Ele afeta a experiência do cliente, a continuidade dos negócios, a reputação do serviço, a resposta a emergências, a produtividade e a confiança operacional. Se um sistema fica indisponível quando as pessoas precisam dele, até mesmo um conjunto poderoso de recursos pode perder seu valor prático. É por isso que o uptime costuma ser discutido em conjunto com monitoramento, redundância, planejamento de manutenção, acordos de nível de serviço e recuperação de desastres.
O que é uptime?
Definição e significado central
Uptime se refere ao período durante o qual um sistema ou serviço está funcionando e disponível para uso. Pode se aplicar a um servidor, roteador, switch, site, aplicação, banco de dados, plataforma em nuvem, IP PBX, sistema de segurança, controlador industrial ou qualquer dispositivo conectado do qual os usuários dependam. Se o sistema está acessível e funcionando conforme esperado, ele é considerado ativo.
O significado central do uptime é a disponibilidade ao longo do tempo. Não significa simplesmente que um dispositivo está ligado. Um servidor pode estar ligado, mas incapaz de responder aos usuários. Um dispositivo de rede pode estar funcionando, mas sem conseguir encaminhar o tráfego corretamente. Um site pode carregar parcialmente, mas falhar em suas funções principais. Para uma medição prática de uptime, o sistema geralmente precisa estar disponível de uma forma que suporte o serviço pretendido.
É por isso que o uptime deve ser definido de acordo com o propósito real do sistema. Uma verificação de uptime de um site pode se concentrar na resposta da página. Um serviço de comunicação pode se concentrar no registro, sinalização e conclusão de chamadas. Uma plataforma de banco de dados pode focar na resposta a consultas. Um sistema de monitoramento pode focar na coleta de dados e na disponibilidade de alertas.
Uptime não se trata apenas de saber se o equipamento está ligado. Trata-se de saber se o serviço esperado está realmente disponível quando os usuários precisam dele.
Uptime versus disponibilidade
Uptime e disponibilidade estão intimamente relacionados e, em muitas discussões cotidianas, são usados quase como sinônimos. No entanto, a disponibilidade costuma ser tratada como uma métrica de serviço mais ampla. O uptime descreve por quanto tempo o sistema permanece operacional, enquanto a disponibilidade pode incluir se o sistema consegue entregar a função necessária aos usuários sob condições reais.
Por exemplo, um processo de servidor pode estar em execução, mas se os usuários não conseguem acessá-lo devido a um problema de rede, o serviço ainda pode estar indisponível. Nesse caso, o servidor em si pode ter uptime, mas o serviço voltado para o usuário não possui disponibilidade total. Essa distinção é importante em sistemas complexos, onde muitos componentes trabalham em conjunto.
No gerenciamento prático de serviços, as organizações geralmente se preocupam mais com a disponibilidade percebida pelo usuário. O serviço deve funcionar da perspectiva do usuário, e não apenas a partir da tela de status local do dispositivo.

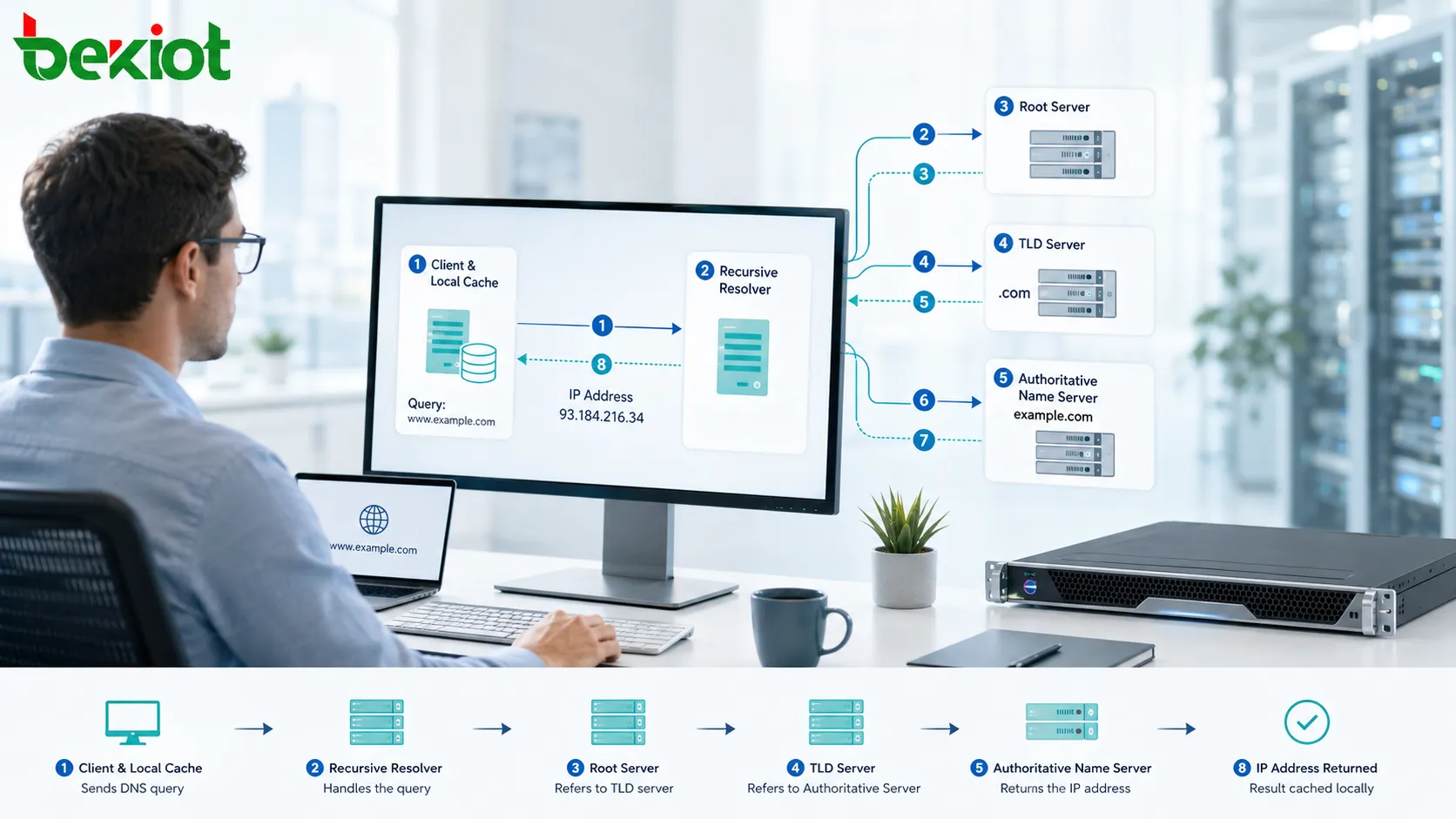
Como o uptime funciona
Medindo o tempo operacional
O uptime funciona medindo o período em que um sistema permanece em um estado saudável e disponível. Isso pode ser medido a partir do tempo de inicialização do sistema, do início do serviço, do tempo de resposta do monitoramento ou de uma janela de disponibilidade de serviço definida. O método depende do que está sendo medido e do que a organização considera como operacional.
Para um único dispositivo, o uptime pode ser exibido como o tempo desde a última reinicialização. Para um site, o uptime pode ser medido por sondas externas que verificam se o site responde corretamente. Para um serviço de rede, o uptime pode depender de os usuários conseguirem se conectar, autenticar, trocar dados e concluir a transação pretendida.
A medição de uptime mais útil está atrelada ao comportamento do serviço. Um sistema que tecnicamente está funcionando, mas falhando em sua função principal, não deve ser contado como totalmente disponível em um modelo operacional sério.
Acompanhando o tempo de inatividade e a porcentagem de disponibilidade
O uptime geralmente é expresso como uma porcentagem ao longo de um período definido, como um mês ou um ano. A fórmula básica compara o tempo em que o sistema esteve disponível com o tempo total que está sendo medido. Se um serviço ficou disponível durante quase todo o período, sua porcentagem de uptime será alta. Se ele sofreu longas interrupções, a porcentagem cairá.
Por exemplo, um serviço que fica disponível por 99,9% de um mês tem menos tempo de inatividade do que um serviço disponível por 99%. Essas porcentagens podem parecer próximas, mas a diferença real de tempo de inatividade pode ser significativa. Pequenas diferenças percentuais são muito importantes em sistemas que suportam operações de negócios, acesso de clientes ou comunicação crítica.
É por isso que o uptime é frequentemente usado em acordos de nível de serviço. Um provedor pode se comprometer com uma determinada porcentagem de uptime, e os clientes usam esse compromisso para entender a confiabilidade esperada do serviço.
A porcentagem de uptime parece simples, mas pequenas diferenças podem representar quantidades muito diferentes de tempo de inatividade real.
Níveis comuns de uptime e o que eles significam
Entendendo 99%, 99,9% e 99,99% de uptime
O uptime é frequentemente discutido em termos de “noves”. Um sistema com 99% de uptime fica disponível na maior parte do tempo, mas ainda permite uma quantidade significativa de inatividade ao longo de um ano. Um sistema com 99,9% de uptime é mais confiável e permite muito menos inatividade. Um sistema com 99,99% de uptime é consideravelmente mais exigente e normalmente requer um projeto mais robusto, melhor monitoramento e disciplina operacional.
Quanto maior a meta de uptime, mais difícil se torna alcançá-la. Passar de 99% para 99,9% pode exigir melhor monitoramento e manutenção. Passar de 99,9% para 99,99% pode exigir redundância, failover, arquitetura de alta disponibilidade, melhor controle de mudanças e resposta mais rápida a incidentes.
No planejamento prático, as organizações não devem escolher metas de uptime apenas porque soam impressionantes. Elas devem alinhar a meta ao risco do negócio, ao custo, às expectativas dos usuários e à importância operacional.
Por que um uptime maior custa mais caro
Um uptime mais alto geralmente exige mais investimento. Um único servidor sem redundância é mais fácil e barato de implantar, mas tem pontos de falha óbvios. Um sistema de alta disponibilidade pode exigir servidores de backup, energia redundante, múltiplos caminhos de rede, balanceadores de carga, bancos de dados com failover, ferramentas de monitoramento e equipe de operações qualificada.
O custo não é apenas de hardware. Inclui planejamento, testes, procedimentos de manutenção, treinamento de pessoal, arquitetura de software, resposta a incidentes e, às vezes, redundância geográfica. Cada camada adicional melhora a resiliência, mas também aumenta a complexidade.
É por isso que o uptime deve ser tratado como um requisito de projeto, não apenas como uma afirmação de marketing. O nível de confiabilidade exigido deve ser suportado por uma arquitetura e um processo operacional reais.

Fatores-chave que afetam o uptime
Confiabilidade do hardware e estabilidade da energia
A confiabilidade do hardware é um dos fatores mais básicos que afetam o uptime. Servidores, dispositivos de armazenamento, switches, roteadores, fontes de alimentação, ventoinhas, discos e outros componentes físicos podem falhar. Se um componente crítico falhar sem um caminho de backup, o serviço pode cair.
A estabilidade da energia é igualmente importante. Mesmo sistemas robustos podem falhar se a energia for interrompida ou estiver instável. Data centers e instalações críticas geralmente usam fontes de alimentação ininterruptas (UPS), geradores de backup, alimentação elétrica dupla e monitoramento de energia para reduzir esse risco.
Em ambientes menores, até mesmo melhorias simples, como proteção elétrica confiável e equipamentos com manutenção adequada, podem melhorar o uptime de forma perceptível.
Conectividade de rede e estabilidade do roteamento
A conectividade de rede afeta fortemente o uptime porque muitos serviços dependem de alcançar os usuários por meio de redes locais, redes de longa distância ou pela internet. Um servidor pode estar saudável, mas se o caminho de rede falhar, os usuários ainda podem enfrentar indisponibilidade. Falhas de switch, erros de roteamento, problemas de DNS, configurações incorretas de firewall e interrupções do ISP podem todos afetar a disponibilidade do serviço.
Links de rede redundantes, provedores diversificados, design de roteamento sólido, gerenciamento adequado de DNS e monitoramento contínuo podem ajudar a melhorar o uptime. Em sistemas de comunicação empresarial, a estabilidade da rede é especialmente importante porque voz, vídeo, mensagens e aplicações em nuvem dependem de conectividade confiável.
Em termos práticos, o uptime deve ser medido ao longo de todo o caminho do serviço, e não apenas no dispositivo principal.
Uptime e arquitetura do sistema
Redundância e failover
A redundância é um dos métodos arquiteturais mais comuns para melhorar o uptime. Significa ter componentes ou caminhos de backup prontos para quando o componente principal falhar. Isso pode incluir servidores, fontes de alimentação, discos, switches, links de rede, bancos de dados, gateways ou data centers redundantes.
Failover é o processo de transferir o serviço do componente com falha para o componente de backup. Em um sistema bem projetado, o failover pode acontecer automaticamente, com pouca ou nenhuma interrupção para o usuário. Em sistemas mais simples, o failover pode exigir intervenção manual.
Redundância e failover não eliminam todos os riscos, mas reduzem a chance de que uma única falha interrompa todo o serviço. Eles são essenciais em sistemas onde o tempo de inatividade tem um impacto significativo nos negócios ou na segurança.
Balanceamento de carga e design de alta disponibilidade
O balanceamento de carga também pode contribuir para o uptime, distribuindo o tráfego entre vários servidores ou instâncias de serviço. Se um servidor ficar sobrecarregado ou falhar, outros servidores podem continuar processando as solicitações. Isso melhora tanto o desempenho quanto a resiliência quando implementado corretamente.
O design de alta disponibilidade combina várias técnicas, incluindo redundância, failover, clusterização, replicação, verificações de saúde, recuperação automatizada e monitoramento. O objetivo é manter o serviço disponível mesmo quando componentes individuais falham.
Um sistema de alta disponibilidade deve ser testado cuidadosamente. Componentes redundantes só são úteis se realmente assumirem o controle corretamente quando ocorrer uma falha.
O uptime é construído a partir da arquitetura, não de pensamento ilusório. Um sistema confiável precisa de caminhos de falha que tenham sido projetados e testados antes de a falha acontecer.
Monitoramento de uptime
Monitoramento interno e externo
O monitoramento de uptime verifica se um sistema ou serviço está disponível. O monitoramento interno observa os componentes de dentro do ambiente, como CPU, memória, saúde do disco, status de processos, estado do banco de dados e conectividade de rede local. O monitoramento externo verifica o serviço de fora, mais próximo da perspectiva do usuário.
Ambos os métodos são úteis. O monitoramento interno pode detectar sinais precoces de falha antes que os usuários sejam afetados. O monitoramento externo pode confirmar se o serviço está realmente acessível do lado de fora. Um sistema pode parecer saudável internamente, mas ainda estar inacessível devido a problemas de DNS, roteamento, firewall ou rede upstream.
Uma estratégia de monitoramento forte geralmente combina verificações internas e externas para criar uma visão mais completa do uptime.
Verificações de saúde, alertas e resposta a incidentes
Verificações de saúde (health checks) são testes automatizados que confirmam se um sistema está funcionando conforme o esperado. Uma verificação simples pode confirmar que um servidor responde a uma solicitação. Uma verificação mais avançada pode validar login, resposta do banco de dados, registro de chamadas, conclusão de transação ou comportamento de API.
Alertas notificam os administradores quando o uptime é ameaçado ou ocorre uma indisponibilidade. No entanto, apenas alertas não são suficientes. A organização também deve ter um processo de resposta a incidentes que defina quem investiga, como os problemas são escalados, como os usuários são informados e como o serviço é restaurado.
O monitoramento se torna mais valioso quando conecta a detecção à ação. Saber rapidamente sobre uma indisponibilidade só é útil se a equipe puder responder de forma eficaz.
Uptime e SLA
Acordos de nível de serviço (SLA)
Um acordo de nível de serviço, frequentemente chamado de SLA, pode definir a porcentagem de uptime que um provedor de serviços ou equipe interna se compromete a entregar. Por exemplo, um provedor pode prometer 99,9% de uptime durante um período de cobrança mensal. O SLA também pode explicar o que conta como tempo de inatividade, quais janelas de manutenção são excluídas e quais compensações ou créditos se aplicam se a meta não for atingida.
A linguagem do SLA é importante porque o uptime pode ser interpretado de maneiras diferentes. Alguns acordos excluem a manutenção programada. Alguns contam apenas a interrupção total do serviço, não a degradação parcial do desempenho. Alguns medem a disponibilidade a partir da rede do provedor, e não da localização do cliente.
Por esse motivo, os usuários devem ler atentamente as definições do SLA. A porcentagem de uptime anunciada é importante, mas as regras de medição são igualmente importantes.
Manutenção planejada versus tempo de inatividade não planejado
Manutenção planejada é um trabalho agendado que pode afetar temporariamente a disponibilidade do sistema. Pode incluir atualizações de firmware, atualizações de software, substituição de hardware, manutenção de banco de dados, aplicação de patches de segurança ou mudanças na infraestrutura. Muitos cálculos de uptime tratam a manutenção planejada de forma diferente das interrupções inesperadas.
O tempo de inatividade não planejado ocorre quando um sistema falha inesperadamente devido a falha de hardware, travamento de software, interrupção de rede, erro de configuração, ataque cibernético, perda de energia ou erro humano. Esse tipo de indisponibilidade geralmente é mais prejudicial porque os usuários não estão preparados para ela.
Um bom gerenciamento de uptime reduz o tempo de inatividade não planejado e comunica a manutenção planejada com clareza para que os usuários possam se preparar.
Dicas de manutenção para um uptime melhor
Use manutenção preventiva
A manutenção preventiva ajuda a melhorar o uptime, abordando os problemas antes que se tornem interrupções. Isso pode incluir a verificação de logs, atualização de firmware, aplicação de patches de segurança, substituição de hardware envelhecido, monitoramento da capacidade de armazenamento, teste de backups e revisão das tendências de desempenho do sistema.
A manutenção preventiva deve ser agendada e documentada. Mudanças aleatórias podem criar novos problemas, mas a manutenção controlada ajuda a reduzir os riscos. O objetivo é manter os sistemas saudáveis sem causar interrupções desnecessárias.
Nas operações práticas, muitas interrupções são evitáveis quando as equipes de manutenção agem antes que os sinais de alerta se transformem em falhas.
Controle as mudanças com cuidado
Mudanças de configuração são uma fonte comum de tempo de inatividade. Uma regra de firewall, alteração de roteamento, atualização de software, substituição de certificado, ajuste de banco de dados ou mudança de política de acesso pode acidentalmente interromper o serviço se não for revisada adequadamente. O controle de mudanças ajuda a reduzir esse risco.
Um bom controle de mudanças inclui documentação, aprovação, teste, planejamento de rollback, escolha de horário e verificação pós-mudança. Para sistemas críticos, as mudanças devem ser feitas durante períodos de baixo impacto e monitoradas de perto em seguida.
O uptime muitas vezes depende tanto de operações disciplinadas quanto de hardware robusto.
Muitos problemas de uptime não começam com equipamentos quebrados. Começam com mudanças descontroladas, hábitos de manutenção frágeis ou verificação ausente.
Aplicações da medição de uptime
Sites, serviços em nuvem e aplicações
Sites, serviços em nuvem e aplicações usam a medição de uptime para avaliar se os usuários podem acessar os serviços digitais quando necessário. Sites de comércio eletrônico, plataformas SaaS, sistemas de internet banking, portais de clientes, plataformas de streaming e aplicações empresariais dependem de alta disponibilidade.
Nesses ambientes, o tempo de inatividade pode causar perda de receita, frustração do cliente, danos à reputação e interrupção do fluxo de trabalho interno. Monitorar o uptime ajuda as organizações a detectar problemas rapidamente e a avaliar se o desempenho do serviço atende às expectativas dos usuários.
Para serviços voltados para o cliente, o uptime costuma ser um dos sinais mais visíveis de confiabilidade.
Redes, sistemas de comunicação e infraestrutura
O uptime também é crítico em redes e sistemas de comunicação. Roteadores, switches, firewalls, plataformas IP PBX, servidores SIP, gateways, sistemas de despacho, redes de interfone, sistemas de segurança e plataformas de monitoramento precisam de operação confiável. Se esses sistemas falharem, a comunicação de voz, o acesso a dados, alarmes, controle de acesso e a coordenação operacional podem ser afetados.
O uptime da infraestrutura é especialmente importante porque muitos outros serviços dependem dela. Uma aplicação em nuvem pode estar saudável, mas se a rede local estiver fora do ar, os usuários não conseguirão acessá-la. Uma plataforma de comunicação pode estar funcionando, mas se um gateway ou caminho de tronco falhar, as chamadas podem não se completar.
É por isso que o uptime da infraestrutura normalmente é monitorado em várias camadas, desde os dispositivos físicos até os serviços voltados para o usuário.
Causas comuns de tempo de inatividade
Falhas técnicas
Falhas técnicas incluem mau funcionamento de hardware, travamentos de software, vazamentos de memória, problemas de banco de dados, falha de disco, falha de equipamento de rede, interrupção de energia, problemas de refrigeração e esgotamento de recursos. Essas são causas comuns de tempo de inatividade em muitos ambientes.
Algumas falhas técnicas acontecem de repente, enquanto outras se desenvolvem gradualmente. Um disco pode mostrar avisos antes de falhar. Um servidor pode ficar lento antes de travar. Um link de rede pode apresentar perda de pacotes antes da interrupção total. O monitoramento ajuda a detectar sinais precoces para que as equipes possam agir mais rapidamente.
Redundância, alertas, planejamento de capacidade e manutenção preventiva ajudam a reduzir o efeito das falhas técnicas.
Erro humano e fragilidade de processos
O erro humano é outra grande causa de tempo de inatividade. Um comando errado, exclusão acidental, regra de firewall mal configurada, arquivo de firmware incorreto, certificado expirado ou atualização mal testada podem derrubar um serviço. Em muitos casos, o sistema não falha porque o hardware é frágil, mas porque o processo operacional é fraco.
Os controles de processo ajudam a reduzir esse risco. Documentação, controle de acesso, revisão por pares, aprovação de mudanças, backups, ambientes de staging e planos de rollback tornam os erros humanos menos prejudiciais. O treinamento também é importante, porque os administradores precisam entender tanto o sistema quanto as consequências das mudanças.
Um gerenciamento de uptime robusto trata pessoas, processos e tecnologia como um único sistema de confiabilidade.
Como melhorar o uptime
Projete para a falha
Melhorar o uptime começa com projetar para a falha. Todo componente pode falhar eventualmente. Um sistema confiável pressupõe que a falha ocorrerá e inclui caminhos de backup, monitoramento, procedimentos de recuperação e comportamento de failover testado.
Essa abordagem muda a mentalidade de design. Em vez de perguntar se um componente vai falhar, a equipe pergunta o que acontece quando ele falhar. Se a resposta for que todo o serviço para, o design pode precisar de melhorias. Se a resposta for que o tráfego muda para um caminho de backup e os usuários continuam trabalhando, o sistema é mais resiliente.
Projetar para a falha é um dos princípios centrais por trás de um alto uptime.
Meça o que os usuários realmente experimentam
A melhoria do uptime deve se concentrar na experiência do usuário, não apenas no status interno. Um painel do servidor pode mostrar que o processo está em execução, mas os usuários ainda podem estar impossibilitados de fazer login, fazer chamadas, abrir arquivos ou concluir transações. Portanto, o monitoramento deve incluir verificações de serviço ponta a ponta sempre que possível.
A medição focada no usuário ajuda a revelar problemas que as verificações em nível de componente podem não perceber. Também ajuda as organizações a entender o impacto real do tempo de inatividade nos negócios. Se os usuários não conseguem concluir a tarefa do serviço, o sistema não está verdadeiramente disponível do ponto de vista deles.
Os melhores programas de uptime medem tanto a saúde técnica quanto o comportamento do serviço voltado para o usuário.
Conclusão
Uptime é a medida de quanto tempo um sistema, dispositivo, serviço ou plataforma permanece operacional e disponível. É um indicador-chave de confiabilidade em sites, plataformas de nuvem, redes, sistemas de comunicação, data centers, infraestrutura industrial e aplicações empresariais. Um alto uptime significa que os usuários podem confiar no serviço quando precisam dele.
O uptime funciona acompanhando o tempo de serviço disponível e comparando-o com o tempo total medido. É influenciado pela confiabilidade do hardware, conectividade de rede, estabilidade de energia, qualidade do software, arquitetura do sistema, monitoramento, manutenção e disciplina operacional. Um uptime robusto normalmente exige redundância, failover, manutenção preventiva, mudanças controladas e monitoramento realista do serviço.
Em termos práticos, o uptime não é apenas uma porcentagem. É um reflexo de quão bem um sistema foi projetado, operado, monitorado e mantido para suportar usuários reais e necessidades de negócios reais.
FAQ
O que significa uptime em termos simples?
Em termos simples, uptime significa a quantidade de tempo que um sistema ou serviço está funcionando e disponível para uso. Se um site, servidor, rede ou dispositivo está funcionando corretamente, esse período conta como uptime.
É comumente usado para medir a confiabilidade.
Como o uptime é calculado?
O uptime geralmente é calculado comparando o tempo em que um sistema esteve disponível com o tempo total no período de medição. O resultado é frequentemente exibido como uma porcentagem, como 99,9% de uptime.
O cálculo exato depende de como a disponibilidade e o tempo de inatividade são definidos.
Por que o uptime é importante?
O uptime é importante porque os usuários e as empresas dependem de sistemas que estejam disponíveis quando necessário. Um uptime ruim pode causar perda de produtividade, falha na comunicação, frustração do cliente, interrupção do serviço e perda de receita.
Um alto uptime apoia a confiabilidade, a continuidade e a confiança do usuário.