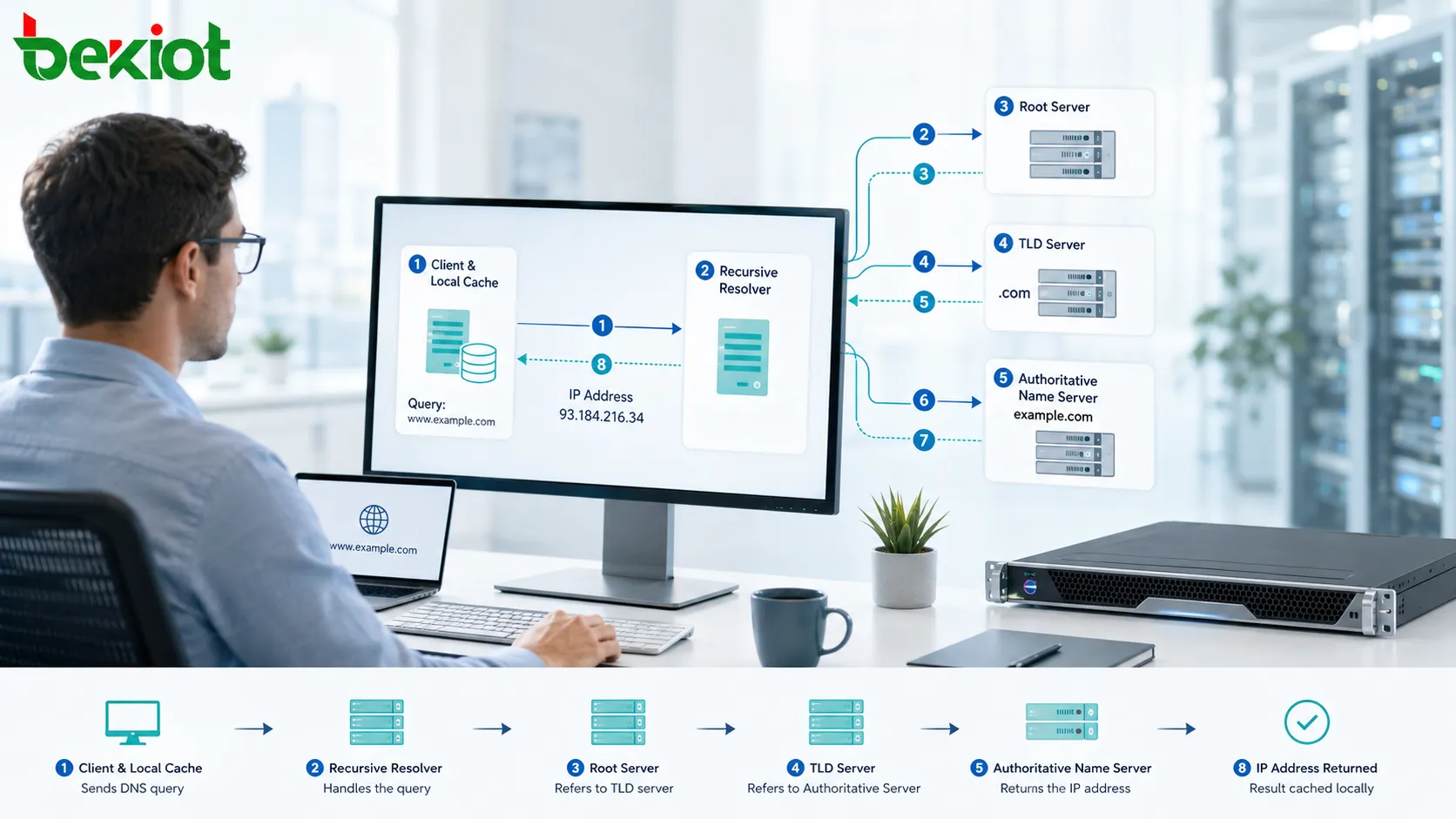
Uma empresa com apenas um escritório muitas vezes resolve problemas de rede adicionando um switch, atualizando um roteador ou ajustando uma regra de firewall. Uma organização com muitas localidades enfrenta outro desafio: cada filial, planta, armazém, campus, data center, região de nuvem e ponto de acesso remoto passa a fazer parte de um mesmo sistema operacional. Se esses locais forem conectados sem planejamento, podem surgir acesso fragmentado, recursos duplicados, segurança inconsistente, diagnóstico lento e colaboração instável.
Visão do setor:o valor de uma rede distribuída já não se limita à conectividade básica. Organizações modernas a utilizam para acesso à nuvem, comunicação unificada, monitoramento remoto, videovigilância, plataformas IoT, gestão centralizada, recuperação de desastres, acesso de confiança zero e aplicações de negócio em tempo real. A questão não é apenas conectar lugares diferentes, mas transformar essas conexões em uma base de serviços controlável e inteligente.
Aproveitar totalmente essa arquitetura significa tratá-la como uma plataforma digital estratégica. Cada site não deve operar como uma ilha separada. Ele deve compartilhar os recursos corretos, seguir as regras de segurança adequadas, trocar os dados necessários e permanecer resiliente quando links, dispositivos ou serviços falharem.
Da conectividade de filiais à integração operacional
O objetivo inicial de conectar várias localidades normalmente era simples: permitir que usuários das filiais acessassem os sistemas da matriz. Esse modelo usava linhas dedicadas, túneis VPN, links WAN privados ou conexões ponto a ponto. Ele resolvia o acesso, mas nem sempre criava operações digitais flexíveis.
Hoje o ambiente operacional é mais complexo. As aplicações podem rodar em nuvem pública, nuvem privada, servidores de borda, data centers locais ou plataformas SaaS. Usuários podem trabalhar em escritórios, veículos, casas remotas, locais de campo e dispositivos móveis. As ameaças podem vir da Internet, endpoints comprometidos, serviços em nuvem mal configurados ou movimento lateral interno.
Por isso, uma arquitetura distribuída precisa suportar mais que transporte de tráfego. Ela deve oferecer desempenho de aplicações, acesso baseado em identidade, políticas centralizadas, segmentação, monitoramento, automação e resiliência em todos os sites conectados.

Definir o papel de cada localidade
Nem toda localidade possui a mesma função. A matriz pode hospedar sistemas centrais de negócio, equipes executivas, salas de dados e equipamentos de segurança central. Uma fábrica pode priorizar tecnologia operacional, monitoramento de produção, terminais industriais e sistemas de controle locais. Um armazém pode focar em códigos de barras, plataformas logísticas, câmeras, cobertura sem fio e dispositivos portáteis. Um pequeno escritório talvez precise apenas de acesso seguro a aplicações em nuvem e serviços de voz compartilhados.
Antes da otimização, cada site deve ser classificado por papel de negócio, dependência de aplicações, número de usuários, tipo de tráfego, requisito de disponibilidade e sensibilidade de segurança. Essa classificação ajuda a definir largura de banda, roteamento, redundância, segmentação, escolha de dispositivos, profundidade de monitoramento e modelo de suporte.
Sem essa etapa, as organizações podem superdimensionar sites pequenos e subproteger sites críticos. Um bom desenho ajusta o nível da rede à importância do negócio em cada localidade.
Construir um modelo claro de conectividade
Um ambiente distribuído pode usar MPLS, Internet de banda larga, 4G/5G, fibra privada, micro-ondas, satélite, VPN, SD-WAN ou conectividade híbrida. Cada opção tem características diferentes de desempenho, custo, confiabilidade e gestão.
Links WAN privados tradicionais oferecem desempenho controlado, mas podem ser caros e lentos para implantar. VPN pela Internet é flexível e econômica, mas o desempenho pode variar. SD-WAN pode combinar vários links, direcionar tráfego por política de aplicação e oferecer orquestração centralizada. Links celulares servem para implantação rápida ou backup. Satélite cobre sites remotos sem enlaces terrestres.
O melhor modelo costuma ser híbrido. Sites críticos podem usar links duplos. Pequenas filiais podem usar banda larga com backup celular. Sites industriais remotos podem usar fibra privada ou backhaul sem fio. O tráfego de nuvem pode ir diretamente às plataformas cloud em vez de retornar pela matriz.
Usar gestão centralizada sem perder resiliência local
A gestão centralizada permite configurar, monitorar, atualizar e proteger muitos sites a partir de uma única plataforma. Isso reduz erros manuais, melhora a padronização e torna a operação em larga escala mais eficiente.
Entretanto, a centralização não deve criar um ponto único de falha. Uma filial não deveria parar totalmente apenas porque perdeu contato temporário com o controlador central. Dependendo da importância do site, podem ser necessários saída local, política em cache, roteamento de backup, DHCP local, encaminhamento DNS local e caminhos de comunicação de emergência.
O objetivo do projeto é equilibrar controle. A organização deve administrar de forma consistente a partir do centro e permitir que os sites mantenham operações essenciais durante falhas de link ou indisponibilidade do controlador.
Segmentar o tráfego por função e risco
A segmentação é essencial em uma arquitetura distribuída. Tráfego de usuários, voz, videovigilância, Wi-Fi de visitantes, sistemas de controle industrial, pagamentos, servidores, interfaces de gestão e dispositivos IoT não devem compartilhar o mesmo espaço de segurança.
VLANs, VRFs, zonas de firewall, listas de controle de acesso, microssegmentação, políticas de confiança zero e grupos de segurança definidos por software ajudam a separar o tráfego. O objetivo é reduzir riscos, controlar acessos e impedir que uma área comprometida afete toda a organização.
A segmentação deve seguir a lógica de negócio. Por exemplo, um usuário de Wi-Fi visitante não deve acessar servidores internos. Uma rede de câmeras pode enviar vídeo para uma plataforma de armazenamento, mas não deve acessar computadores de escritório. Terminais industriais podem exigir caminhos estritos para sistemas de controle e servidores de monitoramento.
Otimizar os caminhos das aplicações
O desempenho das aplicações é uma das principais razões para modernizar a conectividade entre localidades. Os usuários não julgam a rede por diagramas de links; julgam por chamadas claras, dashboards rápidos, arquivos sincronizados, vídeo estável e sistemas de negócio sem atraso.
Roteamento consciente de aplicações pode escolher caminhos conforme latência, perda de pacotes, jitter, largura de banda e prioridade do serviço. Voz e vídeo precisam de baixa latência e baixo jitter. Transferências grandes toleram atraso, mas exigem largura de banda. Aplicações em nuvem podem se beneficiar de saída direta à Internet. Dados sensíveis podem precisar de inspeção por gateways de segurança.
A engenharia de tráfego deve se basear no comportamento real das aplicações. Um modelo genérico de enviar todo o tráfego para a matriz pode se tornar ineficiente quando a maioria das aplicações está hospedada na nuvem.
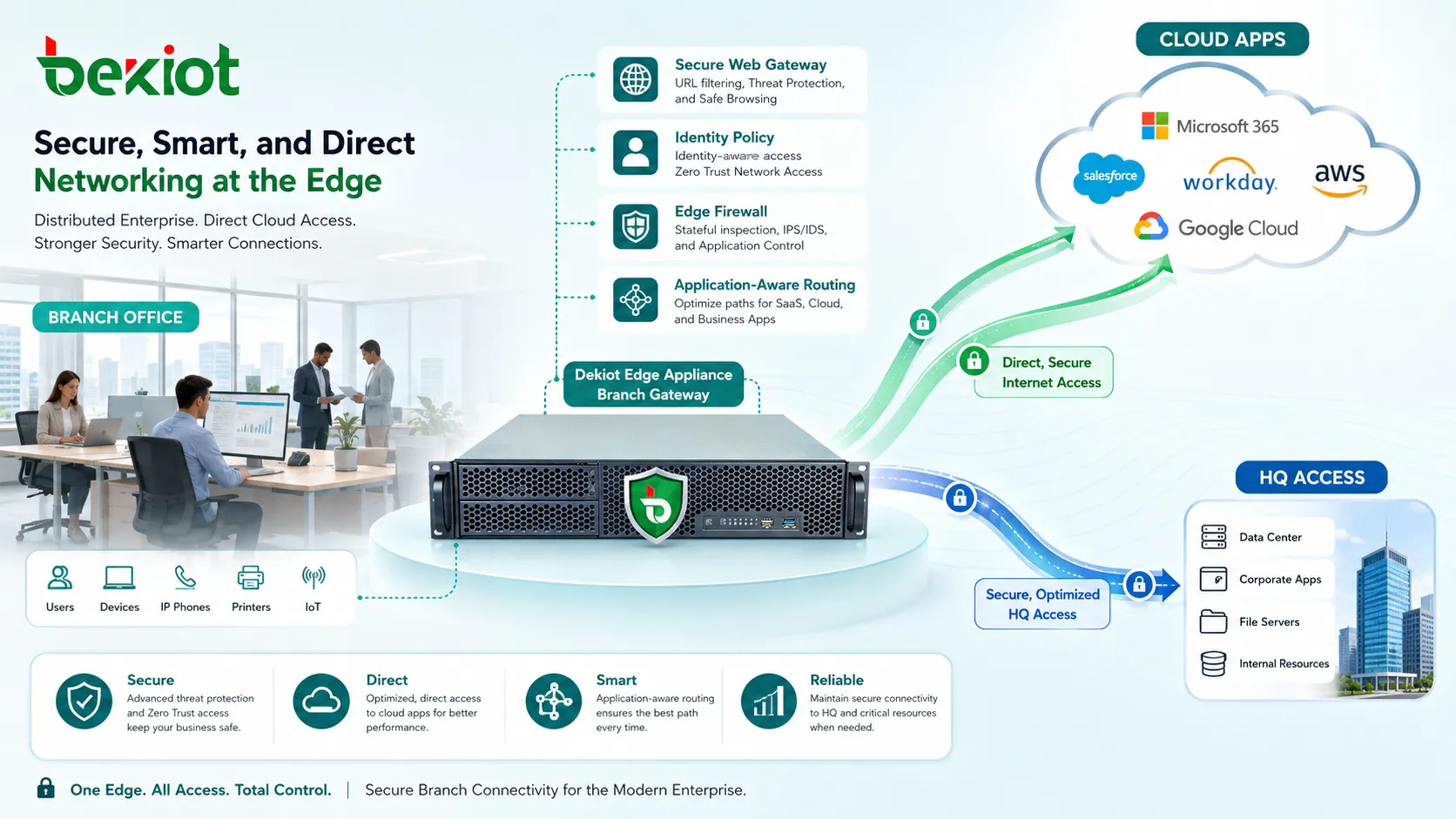
Fortalecer o acesso à nuvem e SaaS
O acesso à nuvem mudou o desenho de redes. Muitas organizações usam plataformas SaaS, cargas em nuvem pública, serviços de identidade, armazenamento cloud, desktops remotos e sistemas de negócio orientados por APIs. Se todo tráfego cloud for forçado por um data center central, os usuários podem sofrer atraso desnecessário.
O acesso direto à nuvem melhora o desempenho, mas precisa ser seguro. Isso pode envolver gateways web seguros, funções CASB, políticas baseadas em identidade, segurança DNS, verificação da postura do endpoint e inspeção de tráfego criptografado quando apropriado.
A conectividade cloud também deve ser planejada para confiabilidade. Cargas críticas podem exigir regiões de nuvem redundantes, interconexões dedicadas, links de Internet de backup ou políticas de failover.
Suportar comunicação unificada entre sites
Voz, vídeo, mensagens, conferências, intercomunicação, paging e despacho geralmente dependem da mesma base de rede. Roteamento ruim, jitter, perda de pacotes ou configuração incorreta de firewall afetam rapidamente a qualidade da comunicação.
Uma rede distribuída bem projetada deve classificar o tráfego de mídia em tempo real, priorizar fluxos sensíveis a atraso, garantir travessia NAT quando necessário e monitorar indicadores de qualidade de voz. Também deve oferecer sobrevivência local de comunicação crítica se serviços centrais estiverem indisponíveis.
Para organizações com muitos sites, a comunicação unificada deve ser integrada a diretórios, planos de numeração, roteamento de emergência, política de gravação e regras de segurança. Isso evita ilhas de comunicação e melhora a coordenação diária e em incidentes.
Habilitar vídeo e IoT em escala
Videovigilância, sensores, controle de acesso, monitoramento ambiental, medidores inteligentes, terminais industriais e dispositivos IoT podem gerar grande volume de tráfego. Eles também possuem características de segurança diferentes dos dispositivos comuns de usuário.
Para usar esses sistemas de forma eficaz, a rede deve definir onde os dados são processados. Algumas análises de vídeo podem ocorrer na borda. Algumas gravações podem ser armazenadas localmente e sincronizadas ao centro. Alguns dados de sensores podem ser enviados a plataformas cloud. Nem todo fluxo precisa cruzar a WAN continuamente.
O processamento na borda reduz pressão sobre largura de banda e melhora o tempo de resposta. Plataformas centrais oferecem visibilidade e gestão. A melhor abordagem depende do site, da aplicação, do valor dos dados e dos requisitos de retenção.
Usar segurança baseada em políticas
A segurança tradicional se concentrava no perímetro do site. Ambientes distribuídos modernos exigem controle mais granular. Um usuário pode acessar aplicações a partir de uma filial, escritório em casa, dispositivo móvel ou workspace cloud. Um dispositivo pode se mover entre redes. Um serviço pode rodar em várias regiões.
A política deve se basear em identidade, saúde do dispositivo, localização, aplicação, sensibilidade dos dados e nível de risco. É aí que princípios de confiança zero se tornam úteis. O acesso deve ser concedido conforme contexto verificado, e não porque um site está dentro da WAN.
A segurança baseada em políticas também melhora a consistência. Em vez de configurar cada firewall e roteador de forma diferente, as organizações podem definir modelos padrão de acesso e aplicá-los entre sites.
Projetar para falhas, não apenas para operação normal
Um sistema distribuído sofrerá falhas. Links de Internet caem, energia falha, dispositivos travam, serviços cloud podem ficar inacessíveis, fibra pode ser cortada e mudanças de configuração podem criar roteamento inesperado. O teste real é se funções críticas continuam ou se recuperam rapidamente.
O planejamento de resiliência deve incluir links redundantes, energia de backup, dispositivos duplos, failover automático, sobrevivência local, gestão out-of-band, backup de configuração e procedimentos de recuperação de desastres. Sites críticos devem ter mais proteção do que sites de baixo risco.
O failover deve ser testado. Um link de backup nunca testado pode falhar quando mais necessário. Os testes devem incluir roteamento, política de segurança, serviço de voz, acesso a aplicações e alertas de monitoramento.
Melhorar a visibilidade com monitoramento e telemetria
Grandes ambientes distribuídos não podem ser gerenciados por observação manual. Administradores precisam de dados em tempo real e históricos sobre status de links, uso de banda, latência, perda de pacotes, saúde dos dispositivos, desempenho de aplicações, eventos de segurança, experiência do usuário e mudanças de configuração.
O monitoramento deve ser em camadas. Monitoramento de dispositivos mostra se o equipamento está online. Monitoramento de links mostra a qualidade do transporte. Monitoramento de aplicações mostra se usuários concluem tarefas. Monitoramento de segurança mostra comportamento suspeito. Análise de logs mostra o que mudou antes de um incidente.
Boa visibilidade reduz o tempo de diagnóstico. Em vez de perguntar se o problema é “a rede”, engenheiros podem ver se é DNS, congestionamento WAN, bloqueio de firewall, falha de serviço cloud, problema Wi-Fi ou endpoint.

Automatizar operações repetitivas
A automação ajuda a reduzir trabalho manual repetido. Tarefas comuns incluem integração de dispositivos, modelos de configuração, implantação de políticas, atualização de firmware, renovação de certificados, backup de configuração, resposta a alertas e verificações de conformidade.
Configuração baseada em modelos é especialmente valiosa para novas filiais. Em vez de reconstruir roteamento, VLANs, VPNs, regras de firewall e monitoramento manualmente, administradores aplicam um perfil padrão e ajustam apenas parâmetros específicos do site.
A automação deve ser controlada por aprovação, controle de versão, testes e rollback. Implantação rápida só é útil quando as mudanças são confiáveis.
Padronizar endereçamento e nomes
O planejamento de endereços fica difícil quando muitos sites crescem de forma independente. Faixas IP sobrepostas, nomes VLAN pouco claros, registros DNS inconsistentes e sub-redes sem documentação criam conflitos de roteamento e atraso no diagnóstico.
Um plano central de endereçamento deve definir códigos de site, blocos IP, faixas VLAN, endereços loopback, redes de gestão, escopos DHCP e faixas reservadas. Regras de nomes devem identificar claramente site, tipo de dispositivo, função e papel.
Bons nomes e endereços reduzem confusão. Também facilitam automação, monitoramento, políticas de firewall e manutenção da documentação.
Planejar Wi-Fi e acesso de borda de forma consistente
Muitos sites dependem fortemente de Wi-Fi, terminais portáteis, dispositivos móveis, leitores de código de barras, tablets, câmeras, sensores e acesso de visitantes. O desenho sem fio deve ser consistente o suficiente para roaming, segurança e gestão, mas flexível para o layout local.
Controladores sem fio centralizados ou pontos de acesso gerenciados na nuvem simplificam políticas. Porém, o planejamento de rádio ainda exige levantamento de site, desenho de canais, análise de interferência e planejamento de capacidade.
O acesso de borda também deve considerar segurança física. Portas de rede em áreas públicas, armazéns e locais industriais não devem fornecer acesso interno irrestrito.
Conectar tecnologia operacional com cuidado
Sistemas industriais e prediais frequentemente incluem tecnologia operacional como PLCs, terminais SCADA, sensores, controle de acesso, sistemas de energia e equipamentos de produção. Esses sistemas podem exigir baixa latência, operação estável, segmentação estrita e janelas de manutenção controladas.
Conectar redes operacionais a sistemas corporativos melhora o monitoramento e a análise de dados, mas também introduz risco cibernético. O acesso deve ser controlado por firewalls, gateways, jump hosts, verificações de identidade e logs.
Equipes de IT e OT devem concordar sobre propriedade, procedimentos de manutenção, acesso de emergência e controle de mudanças. Uma alteração inofensiva na rede de escritório pode afetar sistemas de produção se aplicada sem cuidado.
Usar saída local estrategicamente
A saída local para Internet permite que uma filial acesse serviços cloud e Internet diretamente em vez de enviar todo o tráfego à matriz. Isso reduz latência e melhora a experiência das aplicações.
O risco é que o tráfego da filial possa contornar controles centrais de segurança. Para evitar isso, a saída local deve ser combinada com gateways web seguros, filtragem DNS, proteção de endpoints, serviços de segurança cloud e inspeção baseada em políticas.
Nem todo tráfego deve sair localmente. Aplicações internas sensíveis ainda podem usar caminhos privados, enquanto SaaS e tráfego web de baixo risco podem usar saída local controlada.
Alinhar o desenho da rede à continuidade do negócio
O planejamento de continuidade deve definir quais serviços precisam sobreviver a diferentes cenários de falha. Uma loja pode precisar de processamento de pagamento. Um hospital pode precisar de acesso clínico e comunicação de emergência. Uma fábrica pode precisar de monitoramento de produção. Um armazém pode precisar de sistemas de leitura e logística.
Depois que as funções críticas são identificadas, a rede pode fornecer o nível correto de redundância e sobrevivência local. Isso pode incluir servidores locais, autenticação em cache, WAN de backup, failover celular, roteamento de voz local ou procedimentos de emergência.
A continuidade do negócio deve ser testada com cenários reais. Um plano escrito não basta se usuários não sabem operar durante uma queda de rede.
Governança e controle de mudanças
Ambientes multilocalidade precisam de governança disciplinada. Uma mudança rápida de firewall em um site pode afetar acesso de outro. Uma nova conexão cloud pode alterar o roteamento. Uma VPN temporária pode se tornar permanente sem revisão.
O controle de mudanças deve incluir motivo da solicitação, sites afetados, nível de risco, plano de rollback, método de teste, janela de manutenção, aprovação e atualização da documentação. Mudanças emergenciais devem ser revisadas após o incidente.
Governança não significa desacelerar tudo. Significa tornar as mudanças seguras, rastreáveis e repetíveis.
Otimização de custos
Aproveitar totalmente uma arquitetura distribuída também significa controlar custos. Algumas organizações pagam caro por largura de banda em locais com pouco tráfego e investem pouco em links críticos. Outras mantêm circuitos privados antigos mesmo após mudança dos padrões de acesso cloud.
A análise de custos deve comparar valor de negócio, necessidade de desempenho, nível de risco e requisito de redundância. Um link caro pode ser justificado para um site crítico, mas desnecessário para um pequeno escritório com aplicações apenas em nuvem.
Dados de monitoramento ajudam nas decisões. Uso real de banda, perda de pacotes, tempo de resposta de aplicações e eventos de failover oferecem evidências melhores que suposições.
Roteiro de implementação
Comece pela descoberta. Mapeie sites, links, dispositivos, aplicações, usuários, zonas de segurança, serviços cloud e dependências operacionais. Identifique sistemas duplicados, links fracos, equipamentos não gerenciados e fluxos sem documentação.
Depois defina a arquitetura-alvo. Decida quais sites precisam de redundância, quais tráfegos devem usar caminhos privados, quais serviços podem usar saída local, como a segmentação funcionará e como políticas serão gerenciadas.
Em seguida, implemente por etapas. Padronize nomes e endereços primeiro, melhore o monitoramento, implante segmentação de segurança, otimize o acesso cloud, introduza automação e teste resiliência. Evite mudar todos os sites de uma vez sem forte capacidade de rollback.
Erros comuns
Um erro é tratar todos os sites da mesma forma. Sites têm riscos, perfis de tráfego e importância de negócio diferentes. A arquitetura deve refletir essas diferenças.
Outro erro é focar apenas em largura de banda. Mais banda não corrige erros de roteamento, falhas de segurança, Wi-Fi ruim, DNS inadequado, latência de aplicações ou falta de visibilidade.
Um terceiro erro é permitir exceções locais sem controle. Rotas temporárias, switches não gerenciados, linhas de Internet paralelas e VPNs não rastreadas criam risco de longo prazo.
Um quarto erro é ignorar a experiência do usuário. A rede pode parecer saudável pelo status dos dispositivos, enquanto usuários sofrem com aplicações lentas ou baixa qualidade de voz.
Um quinto erro é atrasar a documentação. Em ambiente distribuído, desenho não documentado se torna risco de futura indisponibilidade.
Tendências do setor
Redes distribuídas caminham para controle gerenciado na nuvem, SD-WAN, SASE, acesso de confiança zero, edge computing, monitoramento assistido por IA e integração mais forte entre rede e segurança. A fronteira entre WAN, acesso cloud, identidade e proteção contra ameaças fica menos separada.
Ao mesmo tempo, organizações adicionam mais dispositivos conectados e serviços em tempo real. Vídeo, voz, sensores, telemetria industrial e operações remotas aumentam a pressão sobre o desenho da rede.
A direção mais bem-sucedida não é simplesmente adicionar mais ferramentas. É construir um modelo operacional coerente em que conectividade, segurança, monitoramento, automação e fluxo de negócio se apoiem.
Uma rede multisite é plenamente utilizada quando se torna uma base digital gerenciada que conecta localidades, protege acessos, otimiza aplicações, sustenta resiliência e dá aos administradores visibilidade clara de toda a organização.
Perguntas frequentes
Por que filiais diferentes têm qualidade de rede diferente?
Cada filial pode usar links de acesso, ambientes Wi-Fi, caminhos de roteamento, modelos de equipamentos, distâncias até a nuvem e cargas locais diferentes. O monitoramento deve comparar condições por site em vez de assumir uma causa comum.
Todo tráfego deve voltar para a matriz?
Nem sempre. Tráfego cloud e SaaS pode ter melhor desempenho por saída local controlada, enquanto tráfego interno sensível ainda pode exigir roteamento privado ou inspeção central.
Como proteger pequenos sites sem equipamentos complexos?
Use modelos padronizados, firewalls gerenciados, gateways cloud seguros, proteção de endpoints, filtragem DNS, autenticação forte e monitoramento centralizado. A complexidade deve corresponder ao risco do site.
Por que a segmentação entre localidades é importante?
A segmentação limita acessos desnecessários entre usuários, dispositivos, servidores, sistemas IoT e redes operacionais. Ela reduz o impacto de comprometimentos e melhora o controle de políticas.
O que verificar antes de adicionar uma nova filial?
Revise necessidades de largura de banda, acesso a aplicações, endereçamento IP, zonas de segurança, desenho Wi-Fi, requisito de redundância, acesso cloud, integração de monitoramento, regras de nomes e responsabilidade de suporte.