

O tempo médio de reparo, geralmente abreviado como MTTR, é uma métrica de manutenção e confiabilidade que mede o tempo médio necessário para restaurar um ativo, dispositivo, máquina, serviço de software, componente de rede ou sistema de produção com falha ao funcionamento normal. Ele se concentra no processo de reparo após a ocorrência da falha, sendo um indicador importante para controle de parada, eficiência de serviço, resiliência operacional e planejamento de manutenção.
Em fábricas, data centers, redes de telecomunicações, sistemas de transporte, instalações de energia, hospitais, edifícios e ambientes de TI, as falhas nem sempre podem ser evitadas. O que importa é a rapidez com que a organização detecta o problema, diagnostica a causa, conclui o reparo, testa o resultado e devolve o sistema ao serviço. O MTTR ajuda as equipes a entender esse desempenho de recuperação de forma mensurável.
Significado básico na gestão de confiabilidade
Mean Time to Repair representa a duração média de reparo em vários eventos de falha. Ele não é o tempo entre falhas nem o tempo total de indisponibilidade de todo um sistema durante um longo período. Em vez disso, responde a uma pergunta prática: quando algo falha, quanto tempo normalmente leva para corrigir?
A métrica é amplamente usada por engenheiros de manutenção, gestores de instalações, equipes de serviço de TI, engenheiros de confiabilidade, fabricantes de equipamentos e gestores de operações. Um MTTR menor geralmente significa restauração mais rápida, melhor resposta de manutenção, maior prontidão de peças sobressalentes, procedimentos mais claros e solução de problemas mais eficiente.
O que o MTTR realmente mede
O MTTR normalmente inclui o tempo ativo de reparo necessário para devolver um ativo à condição de operação. Dependendo da definição da organização, pode incluir confirmação da falha, diagnóstico, substituição de peças, recuperação de configuração, testes funcionais e restauração final do serviço.
Por exemplo, se uma máquina de produção para por causa de um sensor defeituoso, o tempo de reparo pode incluir envio do técnico, inspeção do sensor, substituição, calibração e verificação de reinício. Se um servidor falha, o reparo pode incluir análise do incidente, substituição de componente, recuperação de dados, reinicialização e validação do serviço.
Por que a definição deve ser clara
Diferentes organizações podem calcular o MTTR de maneiras ligeiramente diferentes. Algumas contam desde o momento em que a falha é relatada. Outras contam a partir do início do trabalho de reparo. Algumas incluem espera por peças, enquanto outras incluem apenas o tempo técnico de reparo ativo.
Por isso o MTTR deve ser definido claramente antes de ser usado para comparação de desempenho. Sem uma definição consistente, a métrica pode ser enganosa. Uma equipe pode parecer lenta porque inclui espera, aprovação ou deslocamento, enquanto outra mede somente a atividade real de reparo.
Como o cálculo funciona
A fórmula padrão do MTTR é simples. Some o tempo de reparo de todos os eventos em um período específico e divida esse valor pelo número total de eventos de reparo. O resultado mostra o tempo médio necessário para restaurar o ativo ou sistema com falha.
Por exemplo, se cinco reparos levam 2 horas, 3 horas, 1 hora, 4 horas e 5 horas, o tempo total de reparo é 15 horas. Dividindo 15 horas por cinco eventos de reparo, o MTTR é 3 horas. Isso significa que cada reparo leva em média 3 horas.
Coleta do tempo de reparo
Um MTTR preciso depende de registros de reparo precisos. As equipes precisam registrar quando a falha foi detectada, quando o reparo começou, quais ações foram tomadas, quando o serviço foi restaurado e se o reparo foi verificado. Sistemas de gestão de manutenção, plataformas de chamados, logs SCADA, service desks e CMMS podem ajudar na coleta dessas informações.
Registros manuais também podem funcionar, mas devem ser consistentes. Se técnicos esquecem de fechar ordens de serviço, registram tempos incompletos ou classificam incidentes de forma diferente, o MTTR final pode não refletir o desempenho operacional real.
Exemplo simples de reparo de equipamento
Imagine uma instalação com uma unidade de ventilação que falha três vezes em um mês. O primeiro reparo leva 90 minutos, o segundo 120 minutos e o terceiro 60 minutos. O tempo total de reparo é 270 minutos.
Usando a fórmula de MTTR, 270 minutos divididos por 3 eventos de reparo resultam em 90 minutos. O MTTR dessa unidade de ventilação é, portanto, 90 minutos. Gestores de instalações podem usar esse número para avaliar eficiência de resposta, carga de trabalho técnica, disponibilidade de peças e necessidade de manutenção preventiva.
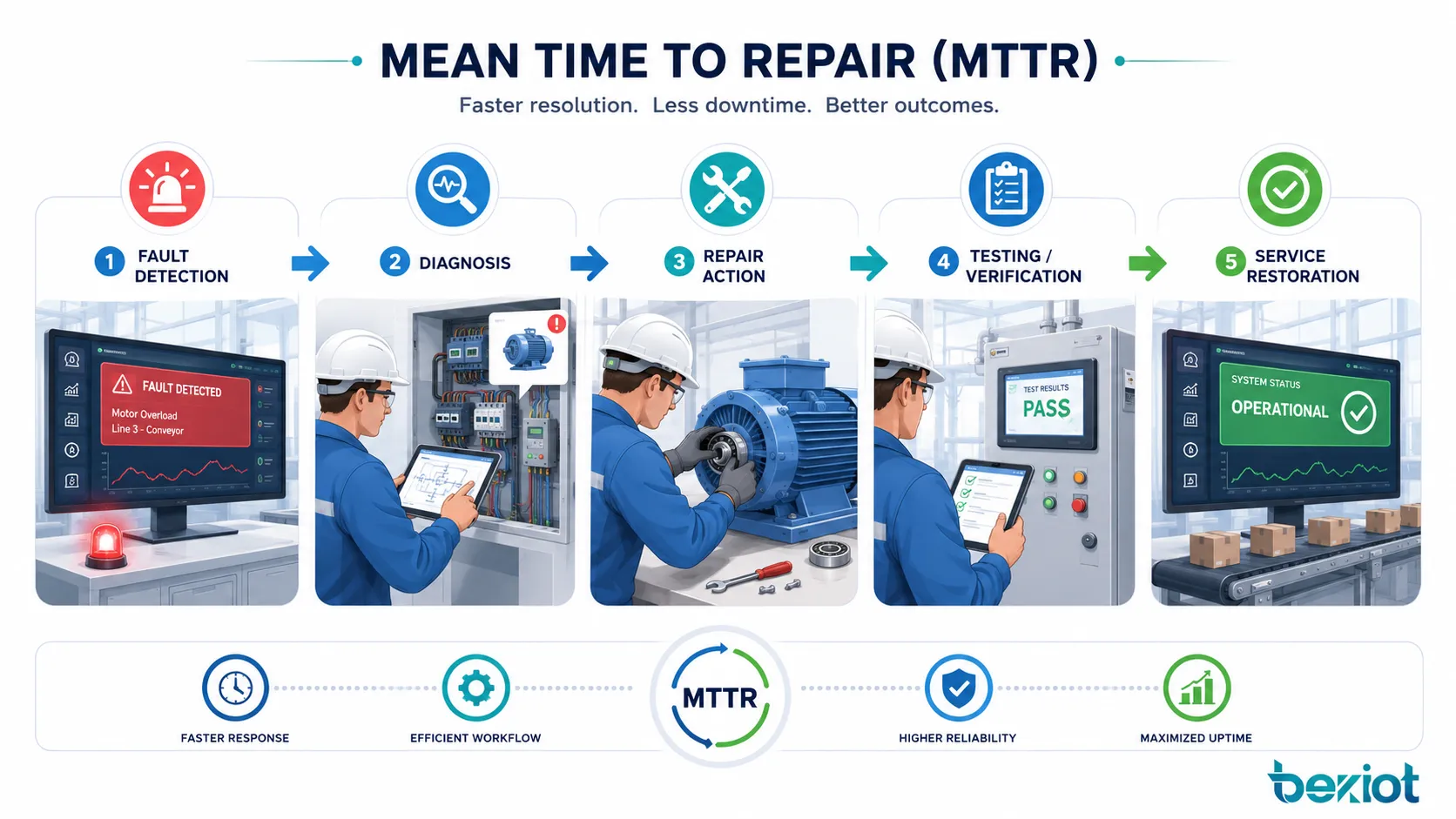
O que acontece durante um ciclo de reparo
O MTTR não é apenas uma média matemática. Ele reflete todo o fluxo de reparo por trás de cada falha. Um tempo longo pode vir de detecção lenta, etapas de diagnóstico pouco claras, falta de peças, documentação ruim, acesso difícil ao equipamento ou ausência de pessoal treinado.
Entender o ciclo de reparo ajuda as equipes a melhorar as causas reais da parada, em vez de observar apenas o número final.
Detecção e relato da falha
O ciclo de reparo começa quando a falha é detectada. Em alguns sistemas, a detecção é automática por alarmes, sensores, painéis de monitoramento, autodiagnóstico ou códigos de erro. Em outros casos, um operador, usuário ou técnico percebe o problema e o relata manualmente.
A detecção rápida reduz o impacto geral da falha. Se um problema de máquina é descoberto imediatamente, o reparo pode começar antes que afete qualidade de produção, segurança ou equipamentos posteriores. Em TI e redes, alertas automáticos podem encurtar muito o tempo de resposta a incidentes.
Diagnóstico e identificação da causa raiz
Após a detecção, técnicos ou engenheiros precisam identificar a causa. O diagnóstico pode envolver inspeção visual, análise de logs, testes elétricos, verificações mecânicas, revisão de software, rastreamento de rede ou comparação com registros históricos de falhas.
O diagnóstico costuma ser um dos fatores que mais afetam o MTTR. Uma equipe com boa documentação, códigos de falha claros, monitoramento remoto e técnicos experientes identifica problemas mais rápido que uma equipe baseada apenas em tentativa e erro.
Reparo, substituição e verificação
O reparo real pode envolver substituição de componentes, reinício de software, correção de configuração, reparo de cabos, ajuste mecânico, recuperação de firmware, limpeza, lubrificação, recalibração ou troca completa do equipamento.
Depois que o reparo termina, o sistema deve ser testado antes de voltar ao uso normal. A verificação pode incluir teste de partida, checagens de segurança, testes de produção, testes de conectividade de rede, confirmação de reset de alarmes ou aceitação do usuário. Sem verificação, um sistema pode parecer reparado e falhar novamente logo depois.
Por que essa métrica importa
O MTTR importa porque o tempo de parada tem consequências reais. Ele pode parar a produção, atrasar a entrega de serviços, reduzir a satisfação do cliente, aumentar custos operacionais, criar riscos de segurança e interromper a continuidade do negócio. Ao acompanhar o tempo de reparo, as organizações encontram pontos fracos da manutenção e melhoram a recuperação.
O MTTR é mais útil quando leva a ações. O objetivo não é apenas calcular o tempo médio de reparo, mas entender por que os reparos demoram e como o processo pode ser melhorado.
Redução do impacto da parada
Um MTTR menor significa que equipamentos ou sistemas retornam à operação mais rapidamente após a falha. Na manufatura, isso reduz perdas de produção. Em telecomunicações e TI, reduz interrupções de serviço. Em edifícios e infraestrutura, melhora conforto, segurança e disponibilidade.
A redução da parada é especialmente importante para sistemas de missão crítica. Plataformas de comunicação de emergência, distribuição de energia, sistemas médicos, controle de tráfego, segurança e linhas industriais exigem restauração rápida porque interrupções podem causar sérias consequências operacionais.
Melhoria da eficiência da manutenção
O MTTR dá às equipes de manutenção uma forma de avaliar a eficiência de resposta. Se o tempo médio aumenta, gestores podem investigar atrasos de peças, treinamento insuficiente, acesso difícil ao equipamento, escalonamento lento ou instruções de reparo pouco claras.
Comparando MTTR por tipo de equipamento, local, turno ou equipe de serviço, as organizações identificam onde a melhoria é mais necessária. Isso apoia melhor alocação de pessoal, treinamento focado, documentação aprimorada e planejamento mais inteligente de peças.
Apoio a metas de confiabilidade e disponibilidade
A disponibilidade do sistema depende da frequência de falhas e da velocidade de recuperação. Mesmo que o equipamento falhe ocasionalmente, um reparo rápido ajuda a manter disponibilidade aceitável. Por isso o MTTR é usado junto com Mean Time Between Failures, porcentagem de uptime, objetivos de nível de serviço e metas de confiabilidade.
Um sistema com falhas frequentes e reparos longos terá baixa disponibilidade. Um sistema com falhas raras e reparos curtos normalmente terá desempenho muito melhor em continuidade operacional.
Benefícios para equipes de operação e manutenção
O MTTR tem valor prático porque conecta desempenho técnico de manutenção a resultados de negócio. Ele ajuda as equipes a sair do reparo reativo e avançar para melhoria estruturada. Em vez de discutir paradas de modo genérico, gestores podem usar dados de reparo para decidir.
Melhor planejamento de peças sobressalentes
Se os reparos demoram por falta de peças, os dados de MTTR expõem o problema. A manutenção pode identificar componentes críticos, definir estoques mínimos, melhorar acordos com fornecedores ou usar módulos de substituição para recuperar mais rápido.
Para ativos de alto valor ou relacionados à segurança, o custo de manter peças em estoque pode ser muito menor que o custo de uma parada prolongada. A análise de MTTR ajuda a justificar essa decisão com evidências mensuráveis.
Gestão de nível de serviço mais clara
Em manutenção terceirizada, suporte de TI, serviços de telecomunicações e operações prediais, o MTTR pode apoiar acordos de nível de serviço. Ele fornece a prestadores e clientes um indicador mensurável do desempenho de reparo.
Metas de serviço devem ser realistas. O alvo para um leitor simples de controle de acesso não é igual ao de uma linha de produção complexa, um grande sistema HVAC ou uma falha de rede em múltiplos locais. Complexidade, localização, risco e acesso devem ser considerados.
Treinamento e documentação mais eficazes
Um MTTR alto pode mostrar que técnicos precisam de melhor treinamento ou instruções mais claras. Se o mesmo tipo de falha demora repetidamente para ser resolvido, a organização pode criar guias de diagnóstico, instruções visuais, checklists ou procedimentos de suporte remoto.
Boa documentação reduz a dependência da experiência individual. Também ajuda novos técnicos a executar reparos com mais confiança e diminui o risco de erros repetidos.
Aplicações comuns em vários setores
Mean Time to Repair é usado em muitos setores porque quase toda organização depende de ativos, sistemas, dispositivos ou serviços que podem falhar. O processo específico de reparo varia, mas a necessidade de medir e melhorar o tempo de restauração é universal.
Manufatura e equipamentos industriais
Em plantas industriais, o MTTR mede o desempenho de reparo de linhas de produção, motores, bombas, transportadores, robôs, máquinas CNC, embaladoras, sensores, painéis de controle e sistemas utilitários.
Reduzir MTTR em ambientes industriais melhora a continuidade da produção, reduz horas extras, aumenta a utilização de ativos e apoia programas de manutenção enxuta. Também ajuda a identificar quais máquinas geram maior carga de reparo.
Sistemas de TI e data centers
Em operações de TI, o MTTR pode se aplicar a servidores, armazenamento, aplicações, bancos de dados, serviços em nuvem, firewalls, switches, roteadores e plataformas voltadas ao usuário. É comum em gestão de incidentes e engenharia de confiabilidade de sites.
Para serviços digitais, reparar pode significar restaurar a funcionalidade de software, não trocar peças físicas. O processo pode incluir revisão de logs, rollback, patch, failover, correção de configuração, reinício ou recuperação por backup.
Telecomunicações e infraestrutura de rede
Operadoras e equipes de rede empresarial usam MTTR para avaliar a velocidade de recuperação de estações base, enlaces de fibra, transmissão, redes IP, gateways, roteadores, switches e plataformas de serviço.
Falhas de rede podem afetar muitos usuários ao mesmo tempo. Reparo rápido e localização precisa são essenciais para manter a qualidade do serviço. Monitoramento remoto, enlaces redundantes, escalonamento claro e coordenação de campo ajudam a reduzir MTTR.
Instalações, edifícios e utilidades
Gestores de instalações usam MTTR para sistemas HVAC, elevadores, bombas, controle de iluminação, acesso, interfaces de alarme de incêndio, segurança, distribuição elétrica, água e automação predial.
Em edifícios e utilidades, o MTTR está ligado a conforto dos ocupantes, segurança, conformidade regulatória e continuidade. Reparos longos podem afetar inquilinos, visitantes, áreas de produção ou usuários de infraestrutura pública.
MTTR comparado a métricas relacionadas
O MTTR é frequentemente discutido com outras métricas de confiabilidade e manutenção. Entender a diferença ajuda a escolher o indicador certo. MTTR foca na velocidade de reparo; outras métricas podem focar frequência de falha, disponibilidade ou tempo de resposta a incidentes.
| Métrica | Significado | Principal finalidade |
|---|---|---|
| MTTR | Tempo médio de reparo | Mede o tempo médio necessário para restaurar um ativo ou sistema com falha |
| MTBF | Tempo médio entre falhas | Mede o tempo médio de operação entre falhas |
| MTTF | Tempo médio até a falha | Estima a vida esperada antes da falha para itens não reparáveis |
| MTTA | Tempo médio para reconhecer | Mede quanto tempo leva para perceber e reconhecer um incidente |
| Availability | Índice de disponibilidade operacional | Mostra com que frequência um sistema está disponível para uso |
MTTR e MTBF
MTBF mede com que frequência as falhas acontecem, enquanto MTTR mede a rapidez do reparo. Ambos são importantes. Um sistema pode ter MTBF alto e ainda causar grande interrupção se cada reparo demorar muito.
Uma máquina que falha apenas duas vezes por ano pode ser problemática se cada falha exige três dias de reparo. Por outro lado, um dispositivo menos crítico pode falhar com mais frequência e ser reparado em minutos. MTBF e MTTR devem ser avaliados juntos.
MTTR e disponibilidade
A disponibilidade é fortemente influenciada pelo MTTR. Se o tempo de reparo diminui e a taxa de falhas permanece igual, a disponibilidade pode melhorar. Por isso reduzir MTTR é estratégia comum para sistemas que não podem ser redesenhados imediatamente para falhar menos.
Na prática, equipes melhoram disponibilidade prevenindo falhas, reparando mais rápido, adicionando redundância, melhorando monitoramento ou projetando sistemas que continuam operando em modo degradado durante o reparo.
Como reduzir o tempo de reparo
Reduzir MTTR exige mais do que pedir aos técnicos que trabalhem mais rápido. A melhoria sustentável vem de melhor projeto do sistema, melhores informações, melhor preparação e melhor coordenação. O objetivo é remover atrasos do processo de reparo.
Usar monitoramento e detecção precoce
O monitoramento automático detecta condições anormais antes que se tornem grandes falhas. Sensores, logs, alarmes, dashboards, sistemas de condição e manutenção preditiva ajudam a responder antes e diagnosticar mais rápido.
A detecção precoce é útil quando o equipamento mostra vibração, aumento de temperatura, mudança de pressão, oscilação de tensão, códigos de erro ou instabilidade de comunicação. Agir nesses sinais reduz tempo de reparo e impacto da falha.
Padronizar procedimentos de solução de problemas
A velocidade de reparo melhora quando técnicos seguem procedimentos claros. Checklists, árvores de falha, manuais, diagramas de fiação, listas de peças, etapas de recuperação de software e regras de escalonamento reduzem incertezas.
Procedimentos padrão também tornam o desempenho mais consistente entre técnicos e turnos. Eles ajudam a garantir que o mesmo problema seja tratado da mesma forma confiável.
Melhorar acesso a peças e ferramentas
Muitos reparos atrasam não porque a falha é difícil, mas porque a peça, ferramenta, senha, imagem de software, cabo ou instrumento de teste não está disponível. Kits de reparo e peças críticas em estoque reduzem significativamente a restauração.
Em locais distribuídos, peças locais, centros regionais ou troca modular evitam longas viagens e atrasos de envio. Em sistemas digitais, backups prontos e modelos de configuração têm função semelhante.
Limites e uso incorreto do MTTR
Embora útil, o MTTR não deve ser o único indicador de manutenção. Um MTTR baixo nem sempre significa sistema confiável; pode apenas mostrar que a equipe é boa em reparar falhas repetidas. Se o mesmo ativo continua falhando, a causa raiz ainda precisa de atenção.
O MTTR também pode esconder variações. A média pode parecer aceitável mesmo quando alguns incidentes críticos levam muito mais tempo. Para sistemas importantes, equipes devem revisar distribuição de tempos, piores casos, falhas repetidas e equipamentos de alto risco separadamente.
Não ignorar a prevenção de falhas
Velocidade de reparo é importante, mas prevenir falhas evitáveis geralmente é melhor. Manutenção preventiva, monitoramento de condição, melhoria de projeto, instalação correta, treinamento do operador e proteção ambiental reduzem a frequência de falhas.
Uma estratégia forte deve equilibrar reparo rápido e melhoria de confiabilidade de longo prazo. O MTTR mostra quão rápido a equipe se recupera, mas não explica por que as falhas acontecem sem análise de causa raiz.
Não comparar sem contexto
Comparar MTTR entre sistemas diferentes pode enganar. Trocar um sensor simples não é comparável a reparar uma turbina, uma queda de rede, um elevador ou uma recuperação de banco de dados. Cada ativo tem sua complexidade, risco, acesso e requisito de reparo.
Comparações úteis devem ocorrer entre equipamentos semelhantes, condições semelhantes ou o mesmo ativo ao longo do tempo. Isso ajuda a identificar melhorias reais e evita julgamentos injustos.
Boas práticas para uso prático
Para usar MTTR com eficácia, organizações devem definir a métrica claramente, coletar dados confiáveis, analisar causas de reparos longos e conectar os resultados a ações de melhoria. A métrica deve apoiar decisões melhores, não ser apenas número de relatório.
Definir pontos de início e fim
Toda organização deve decidir quando o tempo de reparo começa e termina. Pode começar quando a falha é relatada, quando o chamado é aberto, quando o técnico chega ou quando o reparo ativo começa. Pode terminar quando o ativo reinicia, quando os testes terminam ou quando o usuário confirma a restauração.
A definição escolhida deve corresponder ao objetivo da medição. Se o objetivo é melhorar o serviço ao cliente, o tempo total de parada pode ser mais relevante. Se é medir eficiência técnica, o tempo ativo de reparo pode ser mais adequado.
Segmentar os dados
Em vez de calcular um MTTR amplo para todos os ativos, as equipes devem segmentar dados por tipo de equipamento, local, categoria de falha, gravidade, equipe, turno, fornecedor ou função do sistema. Isso torna a métrica mais útil e acionável.
Uma instalação pode descobrir que reparos de bombas são rápidos, mas elevadores são lentos porque peças são terceirizadas. Uma equipe de TI pode ver que incidentes de aplicações resolvem rápido, enquanto incidentes de rede exigem diagnóstico maior. A segmentação mostra onde começar.
Conectar MTTR à análise de causa raiz
Quando os tempos de reparo são altos, as equipes devem investigar o motivo. A falha foi difícil de diagnosticar? Faltava documentação? A peça estava indisponível? A aprovação atrasou? O acesso remoto não estava disponível? O equipamento era difícil de alcançar?
A análise de causa raiz transforma o MTTR de uma medição passiva em ferramenta ativa de melhoria. Com o tempo, isso reduz paradas, melhora a confiabilidade e torna o planejamento de manutenção mais previsível.
FAQ
O que significa Mean Time to Repair?
Mean Time to Repair é o tempo médio necessário para restaurar um ativo, sistema, dispositivo ou serviço com falha à operação normal. Calcula-se dividindo o tempo total de reparo pelo número de eventos em um período definido.
MTTR é o mesmo que tempo de parada?
Nem sempre. MTTR geralmente foca na duração do reparo, enquanto a parada pode incluir detecção, atraso de relatório, espera, atraso de peças, aprovação e reinício. A organização deve definir exatamente o que está incluído.
Qual é um bom valor de MTTR?
Um bom MTTR depende do equipamento, setor, exigência de serviço e gravidade. Poucos minutos podem ser esperados para reiniciar um serviço digital, enquanto várias horas podem ser razoáveis para equipamentos industriais complexos. O melhor benchmark costuma ser comparar ativos semelhantes ou desempenho anterior.
Como uma empresa pode reduzir o MTTR?
Uma empresa pode reduzir MTTR melhorando monitoramento, acelerando detecção, padronizando diagnóstico, treinando técnicos, mantendo peças críticas disponíveis, usando diagnóstico remoto, melhorando documentação e simplificando o acesso ao equipamento.
Por que o MTTR é importante para a confiabilidade?
O MTTR é importante porque a velocidade de reparo afeta diretamente a parada e a disponibilidade. Mesmo sistemas confiáveis podem falhar, então recuperação rápida reduz impacto operacional, interrupção de serviço, perda de produção e insatisfação do cliente.
Qual é a diferença entre MTTR e MTBF?
MTTR mede quanto tempo os reparos levam após a falha. MTBF mede o tempo médio entre falhas. MTTR foca na velocidade de recuperação, enquanto MTBF foca na frequência de falhas. Ambas as métricas ajudam a entender confiabilidade e disponibilidade gerais.







