Um SLA torna-se útil quando as expectativas de serviço precisam sair da promessa verbal e entrar em uma operação mensurável.
O cliente espera disponibilidade estável, recuperação rápida, resposta clara, janelas de manutenção previsíveis e relatórios transparentes. O provedor precisa de limites de responsabilidade, metas mensuráveis, regras de escalonamento e avaliação baseada em evidências. O SLA conecta esses lados ao definir entrega, medição e consequências quando o nível acordado não é atingido.
A lógica operacional por trás de compromissos mensuráveis
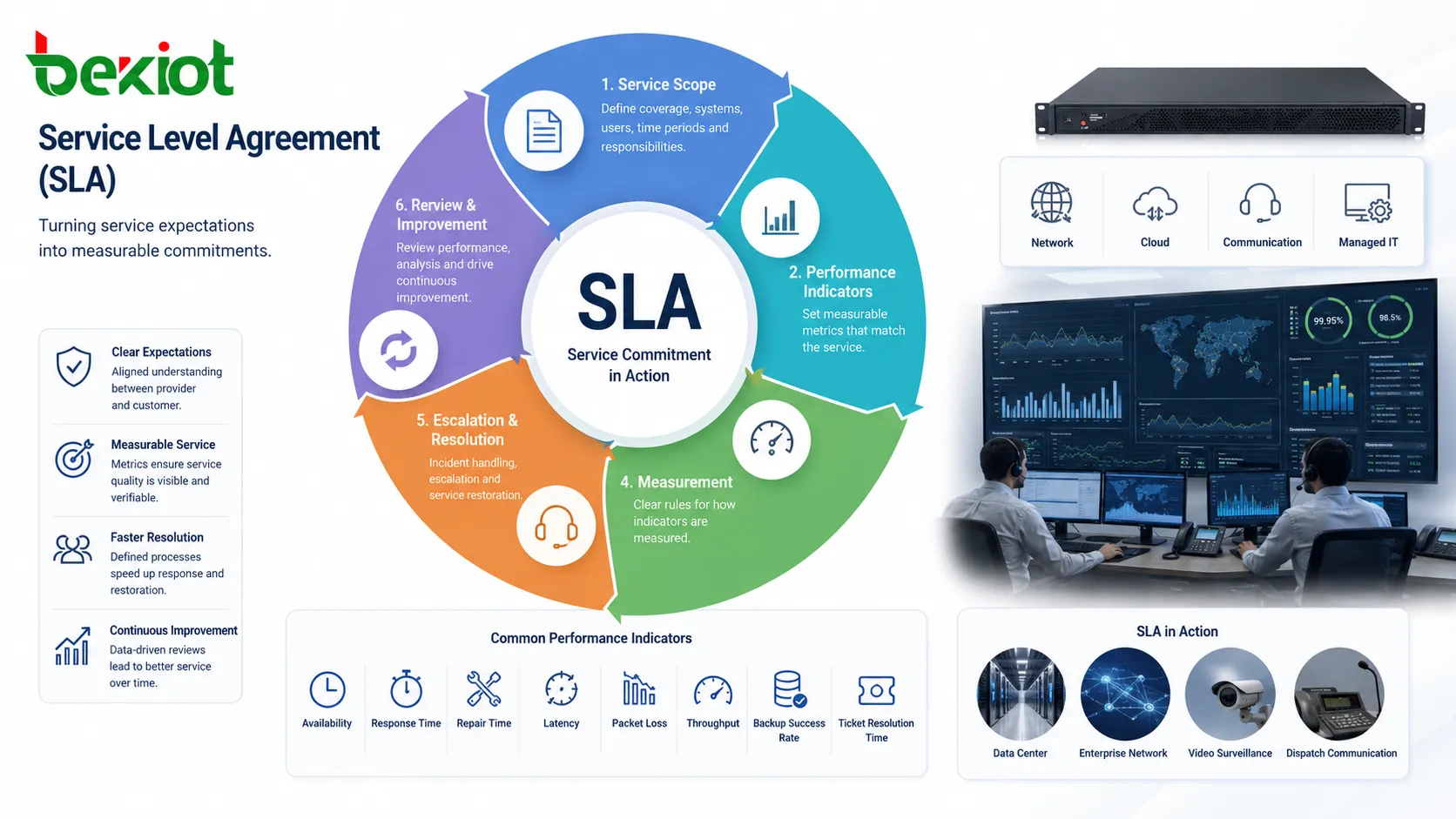
Um Acordo de Nível de Serviço, ou SLA, é um acordo formal que define o nível esperado entre provedor e cliente. Pode abranger redes, nuvem, data centers, sistemas de comunicação, serviços de TI gerenciados, software, manutenção e operações de segurança. Seu objetivo é transformar expectativas em compromissos mensuráveis.
A operação começa pela definição do escopo: quais serviços, sistemas, sites, usuários, períodos e responsabilidades estão incluídos. Sem esse escopo, a avaliação de desempenho fica imprecisa.
Depois são definidos indicadores como disponibilidade, tempo de resposta, tempo de reparo, restauração, atendimento de incidentes, sucesso de backup, resolução de chamados, latência, perda de pacotes, throughput e cobertura de suporte. Cada indicador deve refletir a natureza do serviço.
O SLA também define como esses indicadores são medidos. A disponibilidade pode ser calculada mensal ou anualmente, no ponto do provedor ou do cliente, com ou sem manutenção programada. Regras transparentes evitam interpretações diferentes.
Na prática, o SLA funciona como uma estrutura contínua de gestão de serviços. Ele define expectativas antes da operação, orienta o monitoramento, apoia escalonamentos durante falhas e fornece evidências para revisões posteriores.
Do texto do acordo à execução diária
O SLA costuma ser um documento, mas seu valor aparece na execução diária. Ele deve orientar monitoramento, chamados, resposta das equipes, atualizações ao cliente e revisões de desempenho.
A execução começa pelo monitoramento. Em redes, isso inclui disponibilidade de links, latência, jitter, perda de pacotes, interfaces e saúde de dispositivos. Em nuvem e software, inclui disponibilidade da aplicação, sucesso de transações, tempo de API, recursos e erros.
A gestão de incidentes é parte central. O SLA define o prazo de reconhecimento, a classificação, o escalonamento e o objetivo de restauração. Incidentes críticos exigem resposta imediata e atualizações frequentes; solicitações menores podem seguir prazos maiores.
O SLA também afeta equipe e estrutura de suporte. Se promete atendimento 24/7, o provedor precisa de pessoas, ferramentas e procedimentos. Se promete reparo rápido de equipamentos críticos, peças, acesso remoto e campo devem estar preparados.
A comunicação com o cliente também faz parte da execução. Durante uma falha, o cliente precisa saber se o caso foi recebido, qual é o impacto, quais ações estão em andamento e quando virá a próxima atualização.
Indicadores que dão significado real ao acordo
A qualidade de um SLA depende dos indicadores. Termos vagos como alta confiabilidade ou suporte rápido não bastam. Indicadores mensuráveis permitem que as duas partes julguem o desempenho de forma consistente.
Disponibilidade é um dos indicadores mais comuns. Ela mostra por quanto tempo o serviço fica utilizável em um período definido. O cálculo deve deixar claro se manutenção, falhas do cliente, força maior ou terceiros são excluídos.
Tempo de resposta indica a rapidez com que o provedor reconhece ou começa a tratar um incidente após o reporte. Não é o mesmo que tempo de reparo; ambos são importantes, mas medem etapas diferentes.
Tempo de resolução ou restauração mede quanto tempo o serviço leva para voltar ao estado normal ou aceitável. Em sistemas críticos, diferentes severidades normalmente têm metas diferentes.
Outros indicadores podem incluir latência, jitter, perda de pacotes, throughput, taxa de sucesso, conclusão de backup, ponto de recuperação, disponibilidade da central de serviços, tempo de segurança e manutenção preventiva.
Como os níveis de severidade moldam a resposta
Muitos SLAs usam níveis de severidade para classificar incidentes. Isso evita tratar uma parada total, uma degradação parcial, um defeito menor, uma dúvida e uma mudança planejada com o mesmo esforço.
Um incidente de alta severidade pode causar interrupção completa, impacto de segurança, perda de negócio ou perda de função crítica. Normalmente requer reconhecimento imediato, escalonamento rápido, especialistas, atualizações frequentes e meta rígida.
A severidade deve ser definida pelo impacto, não pela emoção. O cliente pode considerar tudo urgente e o provedor pode ser conservador. Definições claras reduzem discussões em momentos de pressão.
A severidade também orienta o escalonamento. Se a falha não for resolvida no prazo, pode subir para suporte superior, gestão ou relatórios adicionais, impedindo que problemas graves fiquem parados na primeira linha.
Em operações maduras, os dados de severidade são revistos periodicamente. Muitos incidentes graves podem indicar problemas de projeto ou estabilidade; muitas reclassificações indicam definições fracas.
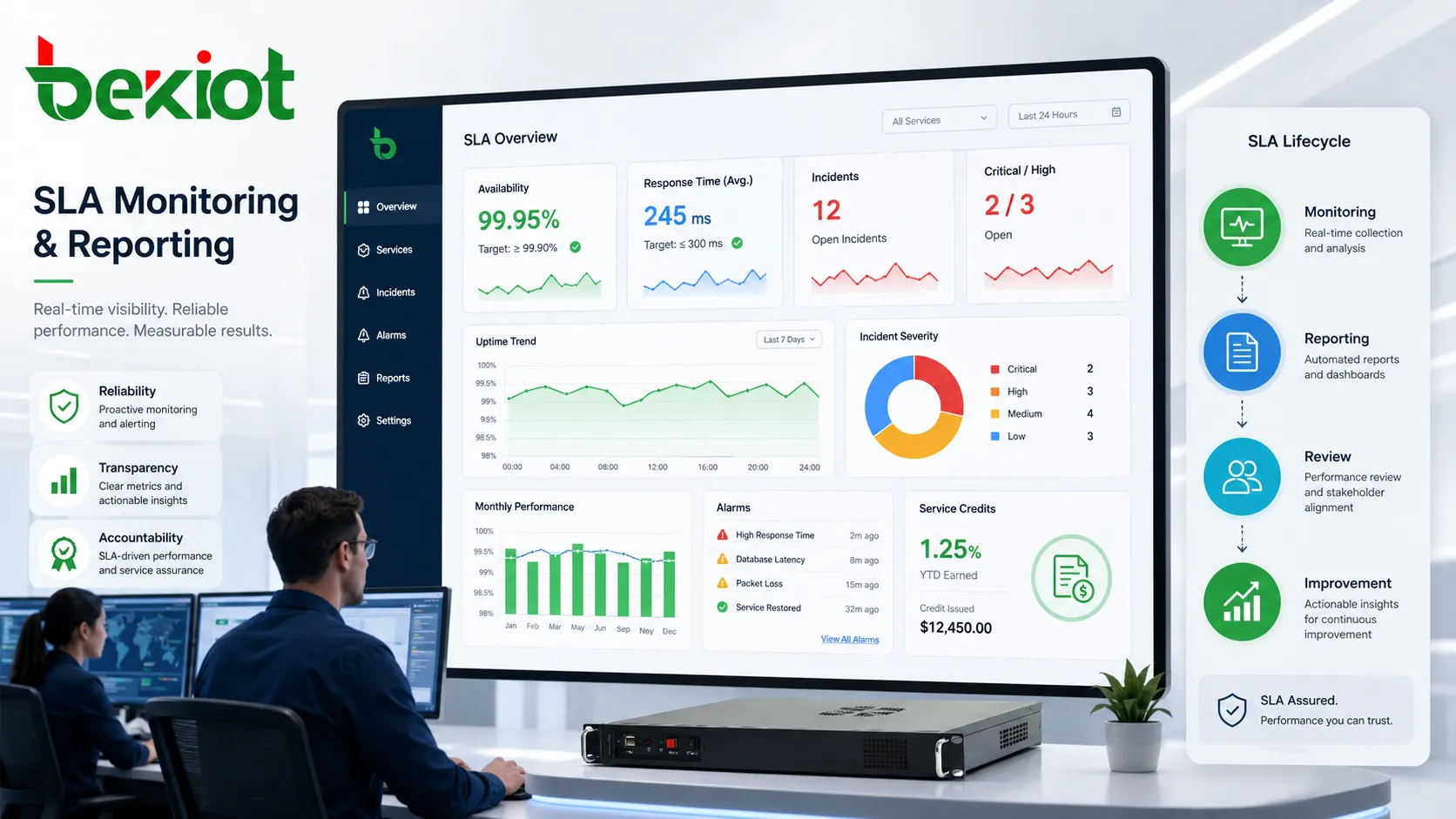
Monitoramento e relatórios como camada de evidência
Sem evidências, um SLA é difícil de aplicar ou melhorar. Monitoramento e relatórios mostram se metas foram cumpridas, onde a qualidade mudou, quais incidentes ocorreram, quão rápido houve resposta e se há problemas recorrentes.
O monitoramento pode ser automático ou manual. Ferramentas acompanham disponibilidade, tráfego, status de dispositivos, servidores, transações, alarmes, resposta e erros. Registros manuais incluem visitas, feedback, notas, inspeções e relatórios pós-incidente.
A frequência do relatório deve combinar com o serviço. Serviços críticos podem exigir painéis em tempo real, resumos diários ou notificações imediatas. Serviços gerenciados comuns podem usar relatórios mensais.
A precisão dos dados é essencial. Medir apenas dentro do data center do provedor pode ocultar falhas no acesso do cliente. O SLA deve definir claramente onde e como as medições são coletadas.
Bons relatórios criam transparência e reduzem disputas. Também revelam padrões, como interrupções repetidas, respostas lentas ou módulos problemáticos, permitindo ações corretivas direcionadas.
Escalonamento, remédios e créditos de serviço
O SLA deve definir o que acontece quando as metas não são atingidas. Escalonamento, remédios e créditos de serviço criam responsabilidade e fazem as partes tratarem problemas com seriedade.
O escalonamento descreve como um chamado não resolvido avança: primeira linha, especialistas, fabricante, centro de operações ou gestão. Deve incluir prazos, contatos, responsáveis e regras de atualização.
Os remédios definem consequências do descumprimento: créditos de serviço, plano corretivo, extensão de manutenção, revisão gerencial ou direito de rescisão após falhas repetidas.
Créditos de serviço devem ser planejados com cuidado. Eles podem compensar financeiramente, mas raramente cobrem todo o impacto do negócio. Em sistemas críticos, restaurar e prevenir é mais importante.
Exclusões também precisam estar claras. Créditos podem não valer para configuração do cliente, mudanças não autorizadas, energia fora do controle do provedor, manutenção programada, força maior ou dependências de terceiros.
Vantagens para clientes e provedores
Para clientes, a principal vantagem é previsibilidade. Eles sabem o nível esperado, os prazos, os serviços cobertos e as evidências usadas para avaliação, o que ajuda planejamento, risco e responsabilidade interna.
O SLA também ajuda a comparar provedores. Duas ofertas parecidas podem diferir em garantia de disponibilidade, resposta, escalonamento, relatórios ou janelas de manutenção.
Para provedores, o SLA define limites. Ele mostra o que está incluído, o que está excluído, como incidentes são classificados e quais responsabilidades cabem ao cliente, reduzindo expectativas irreais.
O SLA melhora a gestão interna. Suporte prioriza por severidade e contrato, operações encontram problemas recorrentes, vendas explicam valor e finanças avaliam risco ligado a créditos ou penalidades.
Para ambos, o maior benefício é o alinhamento. As expectativas do cliente e o processo de entrega do provedor ficam conectados por métricas e procedimentos acordados.
Valor operacional além da proteção contratual
Algumas organizações tratam o SLA como documento jurídico, mas seu valor operacional costuma ser maior. Ele incentiva monitoramento, documentação, escalonamento, análise de causa, capacidade e melhoria contínua.
Se o SLA define respostas rígidas, canais de suporte devem ser monitorados. Se define disponibilidade, o provedor precisa manter redundância, backup e detecção de incidentes. Se exige relatórios, deve coletar dados.
Clientes também usam relatórios de SLA para entender dependências, justificar melhorias, planejar manutenção e avaliar riscos antes que uma falha grande ocorra.
Em ambientes complexos, SLAs ajudam a coordenar vários fornecedores de nuvem, rede, segurança e manutenção local, mostrando onde responsabilidades se encontram e onde há lacunas.
Quando bem usado, o SLA entra na governança do serviço. Ele move a gestão de reclamações reativas para controle estruturado de desempenho.
Erros comuns no desenho de SLA
Um erro comum é usar números impressionantes sem regras de medição. Alta disponibilidade perde força se exclui muitas condições ou usa um ponto que não reflete a experiência do cliente.
Outro erro é escolher métricas demais. Uma lista longa parece completa, mas complica a gestão. As melhores métricas têm ligação direta com impacto de negócio, qualidade ou risco.
Definições ruins de severidade também causam disputas. O acordo deve descrever níveis de impacto e, se possível, exemplos para classificar incidentes com rapidez e consistência.
Alguns SLAs falham porque as responsabilidades são unilaterais. A qualidade depende de acesso, relatórios corretos, janelas aprovadas, contatos, energia e suporte de configuração do lado do cliente.
Outro erro é não revisar o SLA depois que o serviço muda. Necessidades, usuários, arquitetura, segurança e dependências evoluem; revisões mantêm o acordo alinhado.
Como avaliar se um SLA é efetivo
Um SLA efetivo deve ser claro, mensurável, relevante, realista e executável. As partes precisam entender escopo, metas, medições, severidade, relatórios e remédios.
Mensurabilidade significa verificar desempenho com dados confiáveis. O SLA deve indicar fontes, cálculos e formas de resolver disputas.
Relevância significa medir o que realmente importa para a operação do cliente. Métricas técnicas só ajudam quando conectadas à experiência ou ao impacto de negócio.
Realismo significa que metas combinam com arquitetura, orçamento, equipe, risco e ambiente. Um bom SLA equilibra ambição e viabilidade.
Executabilidade significa que o não cumprimento leva a ações definidas, como escalonamento, correção, crédito, revisão gerencial ou plano de melhoria.

Perguntas frequentes
O SLA é necessário apenas para serviços terceirizados?
Não. SLAs são úteis em serviços terceirizados e também entre equipes internas de TI, facilities, áreas de negócio ou centros compartilhados.
Qual é a diferença entre SLA e KPI?
SLA é um acordo de compromissos de serviço. KPI é um indicador de desempenho. Metas de SLA usam KPIs, mas nem todo KPI é compromisso contratual.
Um SLA pode garantir que falhas nunca aconteçam?
Não. Um SLA não elimina falhas; ele define desempenho esperado, resposta, medição e remédios. O bom projeto reduz risco, e o SLA define como julgar e gerir o serviço.
Quem deve revisar relatórios de SLA?
Equipes operacionais e gestão devem revisar os relatórios. Técnicos precisam de detalhes para corrigir; gestores precisam de tendências, risco e evidência de suporte ao negócio.
Com que frequência um SLA deve ser atualizado?
O SLA deve ser revisto quando escopo, arquitetura, escala, dependência de negócio, conformidade ou responsabilidades mudam, além de revisões periódicas.