Uma atualização de sistema nunca deve começar pelo pacote de instalação.Ela deve começar por uma pergunta operacional simples: o que precisa permanecer estável enquanto a mudança acontece? Uma nova versão pode trazer correções de segurança, melhor desempenho, novas funções ou maior ciclo de suporte, mas também pode introduzir incompatibilidades, alterações de configuração, interrupção do serviço e pressão de recuperação.
Portanto, uma boa gestão de atualização não é apenas clicar em “atualizar” no momento certo. Ela consiste em controlar a mudança de modo que serviços, usuários, dados e continuidade do negócio fiquem protegidos.
Comece pelo motivo da mudança
A primeira regra é confirmar por que a atualização é necessária. Algumas são urgentes porque corrigem vulnerabilidades de segurança, erros graves, questões de conformidade ou riscos de fim de suporte. Outras são planejadas porque melhoram desempenho, adicionam recursos, suportam novo hardware ou alinham a arquitetura futura. Há ainda atualizações opcionais que devem esperar até que a organização tenha tempo suficiente para testes.
Sem um motivo claro, as decisões de atualização se tornam reativas. A equipe pode atualizar apenas porque existe uma nova versão, porque o fornecedor recomendou ou porque outro departamento já fez. Isso cria risco desnecessário. Um sistema estável não deve ser alterado casualmente se o benefício não compensar a possível interrupção.
O objetivo da atualização deve ser escrito de forma prática, como “corrigir vulnerabilidade de autenticação”, “suportar nova versão de banco de dados”, “melhorar a capacidade de processamento de chamadas”, “substituir sistema operacional sem suporte” ou “habilitar integração com uma nova plataforma”. Um objetivo claro ajuda a definir escopo de testes e critérios de aceitação.
Quando o motivo está claro, a equipe também consegue definir a urgência. Uma atualização crítica de segurança pode exigir aprovação mais rápida. Uma atualização funcional pode ser marcada para uma janela de manutenção de baixo risco. Uma atualização grande de arquitetura pode exigir implantação por fases. Motivos diferentes exigem níveis diferentes de controle.
Avalie o impacto no negócio antes da ação técnica
Toda atualização afeta mais do que o sistema técnico. Ela pode afetar usuários, janelas de serviço, aplicações conectadas, relatórios, permissões de acesso, dispositivos, experiência do cliente, fluxo de produção ou equipes de suporte. Antes de qualquer ação técnica, a equipe deve identificar quais processos de negócio dependem do sistema.
Isso é especialmente importante em sistemas que operam continuamente, como plataformas de comunicação, bancos de dados, sistemas industriais, portais de clientes, sistemas de pagamento, plataformas de monitoramento e ferramentas internas de operação. Mesmo uma interrupção curta pode causar chamadas perdidas, transações falhas, atraso de produção, registros incompletos ou reclamações.
A análise de impacto deve considerar períodos de pico, grupos críticos de usuários, clientes externos, departamentos internos, compromissos de nível de serviço e exigências legais ou de conformidade. Se o sistema suporta resposta a emergências, controle de produção, monitoramento de segurança ou serviço público, o plano deve ser mais rigoroso que o de ferramentas comuns de escritório.
O resultado dessa análise deve orientar o agendamento. Algumas atualizações podem ocorrer no horário normal de manutenção. Outras exigem noites ou fins de semana. Algumas precisam de sistemas temporários de backup, comunicação aos usuários ou migração por etapas. Uma atualização tecnicamente simples ainda pode ser arriscada se o momento for inadequado.
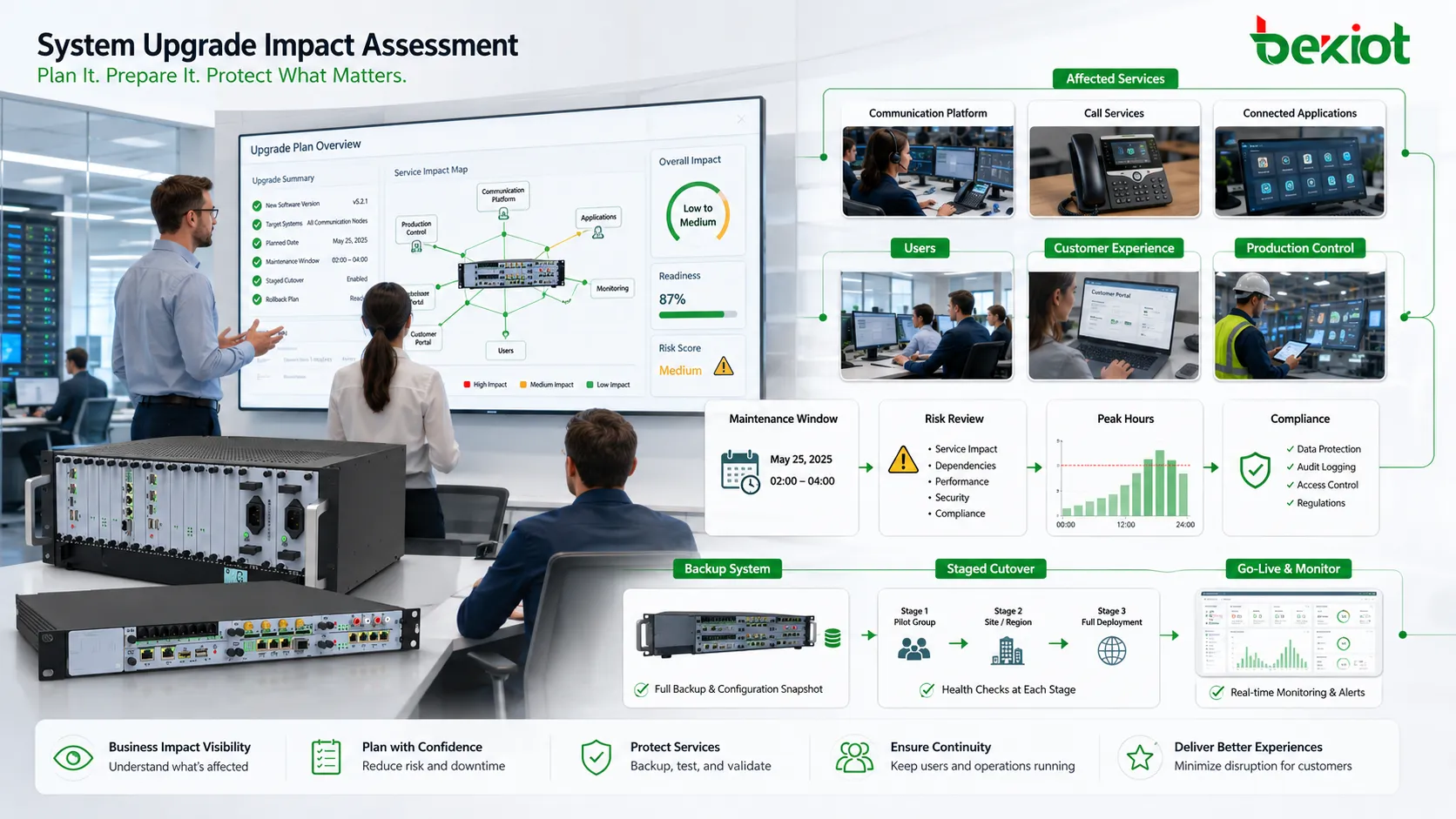
Monte primeiro um inventário preciso
Um sistema não pode ser atualizado com segurança se a equipe não souber o que está conectado a ele. O inventário deve incluir servidores, sistemas operacionais, bancos de dados, middleware, aplicações, terminais, dispositivos de rede, armazenamento, licenças, certificados, APIs, integrações de terceiros, ferramentas de backup, sistemas de monitoramento e métodos de acesso dos usuários.
Esse inventário revela dependências ocultas. Uma ferramenta de relatórios pode depender de uma versão específica de banco de dados. Um cliente legado pode não suportar um novo protocolo. Um dispositivo pode falhar após mudança de firmware. Um sistema de segurança pode usar API desatualizada. Descobrir isso depois da implantação aumenta a pressão por reversão.
O inventário de configuração é igualmente importante. Parâmetros do sistema, regras de roteamento, permissões, chaves de integração, tarefas agendadas, contas de serviço, regras de firewall, certificados e scripts personalizados devem ser registrados antes da atualização. Muitos problemas surgem por detalhes de configuração ausentes ou sobrescritos, não pela nova versão em si.
Em ambientes grandes, o inventário também deve mostrar diferenças de versão entre sites ou nós. Uma filial pode estar em outro nível de patch. Um servidor pode ter módulo customizado. Um modelo de dispositivo pode precisar de firmware especial. Essas diferenças influenciam a sequência de atualização e o desenho dos testes.
Confirme a compatibilidade em vez de presumir
Compatibilidade é um dos riscos mais comuns. Uma nova versão pode exigir banco de dados mais recente, biblioteca de execução diferente, navegador atualizado, driver alterado, API revisada ou novo método de autenticação. Se os sistemas conectados não forem compatíveis, a atualização pode ser tecnicamente concluída e operacionalmente falhar.
As verificações devem cobrir hardware, sistema operacional, banco de dados, versão da aplicação, protocolo, interface, navegador, cliente móvel, terminal, driver, plug-in, certificado e serviço de terceiros. A equipe não deve depender apenas de notas gerais de versão; as condições do projeto precisam ser comparadas com os requisitos do fornecedor e a configuração local.
A compatibilidade retroativa também importa. Se clientes antigos, dispositivos ou integrações precisarem continuar funcionando após a atualização, isso deve ser testado diretamente. Alguns sistemas aceitam versões mistas por tempo limitado; outros exigem atualização conjunta de todos os componentes. Um erro nessa avaliação pode causar falha parcial do serviço.
Quando houver incerteza, use um ambiente piloto. A equipe pode testar dispositivos representativos, perfis de usuário, fluxos de dados e chamadas de interface antes de alterar produção. Isso reduz a chance de descobrir conflitos importantes durante a janela de manutenção.
| Área de atualização | Regra principal | Motivo da revisão |
|---|---|---|
| Versão da aplicação | Verificar notas de versão e mudanças de dependência | Evita perda de funções e conflitos de interface |
| Banco de dados | Validar esquema, driver e requisitos de migração | Protege acesso a dados e estabilidade de transações |
| Sistema operacional | Confirmar suporte a runtime, serviços e políticas de segurança | Evita problemas de inicialização e permissão |
| Rede e segurança | Revisar firewall, certificados, DNS e regras de acesso | Evita falhas de conexão após a transição |
| Terminais e clientes | Testar dispositivos e versões representativos | Reduz reclamações de compatibilidade em campo |
Proteja os dados antes de mudar o ambiente
Proteção de dados é regra inegociável. Antes da atualização, a equipe deve confirmar disponibilidade, integridade, método de restauração, local de armazenamento, política de retenção e tempo de recuperação do backup. Um backup nunca testado é apenas uma hipótese, não um plano de recuperação.
Para bancos de dados e plataformas de aplicação, o backup deve ser feito no ponto correto. Se os dados continuarem mudando durante a atualização, é preciso decidir se as gravações serão paradas, se logs de transação serão usados, se haverá snapshot ou se será preparada recuperação por replicação. O método depende da arquitetura e da parada aceitável.
O backup de configuração não deve ser ignorado. Configurações de aplicação, arquivos de serviço, tabelas de roteamento, tarefas agendadas, papéis de usuário, certificados, chaves e modelos personalizados podem ser tão importantes quanto os dados de negócio. Após uma falha, reconstruí-los manualmente pode demorar mais que restaurar o software.
Scripts de migração também devem ser revisados com cuidado. Algumas atualizações alteram esquema, índices, codificação, tamanho de campos ou estrutura de dados. Essas mudanças podem ser difíceis de desfazer. A equipe deve saber se a migração é reversível, se a reversão exige restauração completa e quanto tempo a recuperação levará.
Use testes que reflitam condições reais
O teste só tem valor quando o ambiente se parece com produção nos pontos relevantes. Um sistema de teste pequeno e vazio pode confirmar que o instalador roda, mas não revelar desempenho ruim, problemas de migração, falhas de integração, conflitos de permissão ou incompatibilidade de dispositivos.
O ambiente de teste deve incluir dados representativos, papéis de usuário, serviços conectados, configurações, chamadas de interface e cargas típicas. Ele não precisa ser uma cópia perfeita da produção, mas deve conter realidade suficiente para expor os riscos principais.
Os casos de teste devem seguir fluxos reais. Usuários devem fazer login, criar registros, executar relatórios, realizar transações, acionar alarmes, chamar APIs, gerar arquivos, acessar clientes móveis ou usar dispositivos conectados conforme o tipo de sistema. Serviço iniciado não significa serviço pronto.
Testes de desempenho também podem ser necessários. Uma nova versão pode funcionar com um usuário e ficar lenta sob carga real. Migração de banco, cache, memória, CPU, I/O de disco, latência de rede e tarefas em segundo plano devem ser observados quando relevantes. A atualização deve ser julgada pelo comportamento operacional.

Prepare a reversão antes da implantação
Uma atualização não deve prosseguir sem plano de reversão. Reversão é o retorno do sistema ao estado anterior funcional se a atualização falhar ou causar problemas inaceitáveis. Dizer “restauraremos o backup se necessário” não basta; a equipe precisa saber exatamente como fazer.
O plano deve definir quem decide reverter, quais condições acionam a reversão, quais arquivos ou bancos serão restaurados, quanto tempo a recuperação levará, que dados podem ser perdidos e como os usuários serão avisados. Também deve indicar se a reversão é possível depois da migração ou se apenas a correção adiante é realista.
Algumas atualizações são fáceis de desfazer. Outras mudam estrutura de banco, métodos de criptografia, firmware ou formatos de configuração de modo difícil de reverter. Esses casos exigem cautela adicional, implantação por etapas, arquitetura blue-green, nós de reserva ou operação paralela.
A reversão deve ser testada quando possível. Um plano nunca ensaiado pode falhar em emergência. Mesmo um ensaio parcial revela permissões ausentes, restauração lenta, backups incompletos ou responsabilidades pouco claras.
Controle a janela de manutenção
A janela de manutenção é o período planejado para a atualização. Ela deve ser escolhida conforme impacto nos usuários, carga do sistema, disponibilidade da equipe, suporte do fornecedor, conclusão dos backups e tempo de reversão. Um erro comum é reservar tempo para atualizar, mas não para solucionar problemas ou reverter.
A janela deve incluir preparação, backup final, execução, verificação, possível correção, tempo de decisão de reversão, execução da reversão e comunicação com usuários. Se a atualização precisa de uma hora, mas a reversão precisa de três, a janela deve refletir isso.
Pode ser necessário congelar mudanças antes da atualização. Outras equipes devem evitar alterações não relacionadas de configuração, rede, banco de dados ou políticas de acesso no mesmo período. Quando várias mudanças ocorrem juntas, a análise de falhas fica muito mais difícil.
A disponibilidade de suporte é essencial. Técnicos-chave, donos da aplicação, engenheiros de rede, administradores de banco, equipes de segurança e suporte do fornecedor devem estar acessíveis. A atualização não deve ocorrer quando a única pessoa que conhece uma dependência crítica está indisponível.
Comunique-se com usuários antes e depois
A comunicação com usuários evita confusão. Antes da atualização, os afetados devem saber horário previsto, impacto no serviço, limitações temporárias, canal de contato e o que devem evitar durante a janela. Sistemas públicos também podem exigir comunicação com clientes.
A mensagem deve ser específica, mas sem excesso de detalhes técnicos. Usuários precisam saber se o sistema ficará indisponível, se a entrada de dados deve parar, se o aplicativo móvel deve ser atualizado, se senhas ou método de login mudarão e quando o serviço deve voltar.
Depois da atualização, os usuários devem receber confirmação de disponibilidade. Se funções mudaram, notas de versão ou orientação curta podem ser necessárias. Se problemas permanecerem, a equipe deve explicar limitações conhecidas e próximos passos de resolução.
Boa comunicação reduz chamados desnecessários. Muitas reclamações pós-atualização não são falhas técnicas, mas surpresa com mudanças de interface, novos prompts de login, sessões expiradas ou variação temporária de desempenho.
Verifique o resultado com verificações de aceitação
A atualização não termina quando o instalador termina. Ela termina apenas quando o sistema passa nas verificações de aceitação. Essas verificações devem ser definidas antes do início para que a equipe saiba o que significa “sucesso”.
As verificações podem incluir inicialização de serviços, login, execução de fluxos principais, leitura e gravação de dados, relatórios, chamadas de interface, conexão de dispositivos, tarefas agendadas, permissões, operação de backup, estado de monitoramento e confirmação de usuários. A lista depende da função do sistema.
Funções críticas devem ser testadas primeiro. Se o sistema suporta transações, teste transações. Se suporta comunicação, teste rotas de chamadas ou fluxos de mensagens. Se suporta monitoramento, teste alarmes e painéis. Se oferece banco de dados, teste acesso e consultas. Não gaste o início da verificação com funções secundárias enquanto serviços críticos não foram testados.
A aceitação também deve incluir análise de logs. Logs de erro, avisos, jobs falhos, erros de autenticação, mensagens de migração e falhas de integração podem revelar problemas antes dos usuários. Uma tela limpa nem sempre significa uma atualização limpa.

Monitore o sistema após a liberação
As primeiras horas e dias após a atualização são importantes. Alguns problemas aparecem apenas com tráfego real, tarefas agendadas, horário de pico ou comportamento específico de usuários. O monitoramento pós-atualização deve ser mais ativo que o normal, especialmente em sistemas críticos.
O monitoramento deve incluir CPU, memória, disco, desempenho do banco, tráfego de rede, status de serviços, logs de erro, sessões de usuário, taxa de sucesso de transações, resposta de API, tamanho de filas e crescimento de armazenamento quando relevante. A equipe também deve acompanhar feedback dos usuários.
Linhas de base de desempenho são úteis. Se a equipe conhece tempo de resposta, uso de recursos e taxa de erro antes da atualização, pode comparar a nova versão de forma mais objetiva. Sem referência, fica difícil saber se a lentidão é nova ou antiga.
O monitoramento deve ter duração definida. Sistemas pequenos podem exigir poucas horas. Sistemas críticos podem precisar de dias ou de um ciclo completo de negócio. A atualização não deve ser encerrada até o sistema provar estabilidade em condições normais.
Documente o que mudou
A documentação faz parte da atualização, não é tarefa administrativa opcional. A equipe deve registrar versão instalada, configurações alteradas, backups feitos, problemas encontrados, como foram resolvidos, quem aprovou a mudança e se há trabalho pendente.
Registros de versão são especialmente importantes. O diagnóstico futuro depende de saber qual versão de sistema, banco, firmware, driver ou patch está em execução. Sem documentação, equipes futuras podem perder tempo redescobrindo o ambiente.
Problemas conhecidos devem ser registrados. Se uma função exige ajuste posterior, uma integração precisa de confirmação do fornecedor ou um grupo precisa de treinamento, esses itens não devem ficar apenas em conversas informais. Devem fazer parte do registro da atualização.
Boa documentação melhora a próxima atualização. A equipe pode revisar o que funcionou, o que demorou mais que o previsto, quais riscos foram perdidos e que etapas devem melhorar. Cada atualização deve deixar a organização mais preparada para a próxima.
Resumo
A regra mais importante de uma atualização de sistema é a mudança controlada. Uma atualização bem-sucedida protege dados, verifica compatibilidade, limita indisponibilidade, prepara reversão, comunica usuários e confirma o comportamento do serviço após a liberação. O pacote de atualização é apenas uma parte do processo.
Em ambientes críticos, a abordagem mais segura é tratar a atualização como um fluxo operacional completo: avaliar impacto, testar com realismo, agendar com cuidado, executar com responsabilidades claras, verificar resultados e monitorar depois. Quando essas regras são seguidas, a atualização melhora sistemas em vez de criar interrupções evitáveis.
FAQ
Todo sistema deve ser atualizado assim que uma nova versão é lançada?
Não. Correções urgentes de segurança podem exigir ação rápida, mas melhorias funcionais ou grandes mudanças de versão devem ser avaliadas primeiro. Compatibilidade, impacto no negócio, prontidão de testes e opções de reversão devem ser revisados antes da implantação.
Qual é a preparação mais importante antes de atualizar?
A preparação mais importante é confirmar a capacidade de recuperação. Isso inclui backups testados, registros de configuração, procedimentos de reversão e regras claras de decisão. Sem confiança na recuperação, até uma atualização simples pode ser arriscada.
Por que atualizações falham mesmo após testes?
Os testes podem não cobrir condições reais de produção, como alto tráfego, dados incomuns, clientes legados, integrações de terceiros, tarefas agendadas, diferenças de permissão ou restrições de rede. O ambiente de teste deve refletir as dependências principais da produção.
Por quanto tempo o monitoramento pós-atualização deve continuar?
Depende da importância do sistema e do ciclo de uso. Uma pequena ferramenta interna pode precisar de pouco monitoramento, enquanto um serviço crítico pode exigir acompanhamento em picos, tarefas agendadas e um ciclo completo de negócio.
O que deve constar no registro da atualização?
O registro deve incluir versões antiga e nova, horário da atualização, responsáveis, detalhes de backup, configuração alterada, resultados de teste, problemas encontrados, status de reversão, comunicação aos usuários e ações pendentes.