

Manter os serviços funcionando quando algo falha
O failover é um mecanismo de confiabilidade que transfere automática ou manualmente as operações de um componente principal com falha para um componente de backup. Ele é usado para manter aplicações, redes, servidores, bancos de dados, sistemas de comunicação, serviços em nuvem e plataformas industriais disponíveis quando hardware, software, links ou serviços deixam de funcionar.
Em termos simples, o failover responde a uma pergunta importante: se o sistema principal falhar, o que assume? Uma arquitetura de failover bem projetada reduz o tempo de indisponibilidade, protege a continuidade do serviço e ajuda as organizações a se recuperarem mais rapidamente de falhas, sobrecargas, eventos de manutenção ou interrupções inesperadas.
O failover não evita todas as falhas. Seu valor está em oferecer ao sistema um caminho de recuperação preparado quando a falha acontece.
Significado básico e papel no sistema
O failover é comumente usado em projetos de alta disponibilidade. Um recurso principal executa a operação normal, enquanto um ou mais recursos em espera permanecem prontos para assumir caso o recurso principal fique indisponível. O backup pode ser outro servidor, roteador, nó de banco de dados, link de rede, data center, região de nuvem, sistema de armazenamento ou instância de aplicação.
O objetivo é reduzir a interrupção do serviço. Em vez de esperar que os técnicos reparem o componente com falha para que o serviço continue, o sistema redireciona tráfego, cargas de trabalho, sessões ou solicitações para outro recurso disponível.
Recursos principais e em espera
O recurso principal é o componente ativo que normalmente fornece o serviço. O recurso em espera está preparado para assumir quando o recurso principal falha. Em alguns sistemas, ele permanece passivo até que o failover seja acionado. Em outros, vários recursos compartilham ativamente o tráfego ao mesmo tempo.
Por exemplo, um site pode rodar em dois servidores de aplicação. Se o primeiro servidor falhar, o tráfego pode ser enviado ao segundo. Um roteador pode usar um link WAN de backup se a conexão principal com a internet cair. Um banco de dados pode promover uma réplica para se tornar o novo nó principal quando o nó principal original falhar.
Detecção de falhas
O failover depende da detecção de falhas. O sistema deve saber quando o componente principal não está saudável. A detecção pode usar sinais de heartbeat, verificações de integridade, monitoramento de links, sondas de serviço, status de replicação do banco de dados, testes de resposta da aplicação ou verificações de alcance de rede.
Uma boa detecção deve ser rápida o suficiente para reduzir a indisponibilidade, mas não tão sensível a ponto de acionar failover desnecessário por um pequeno atraso ou perda temporária de pacotes. Esse equilíbrio é importante no projeto real de redes e aplicações.
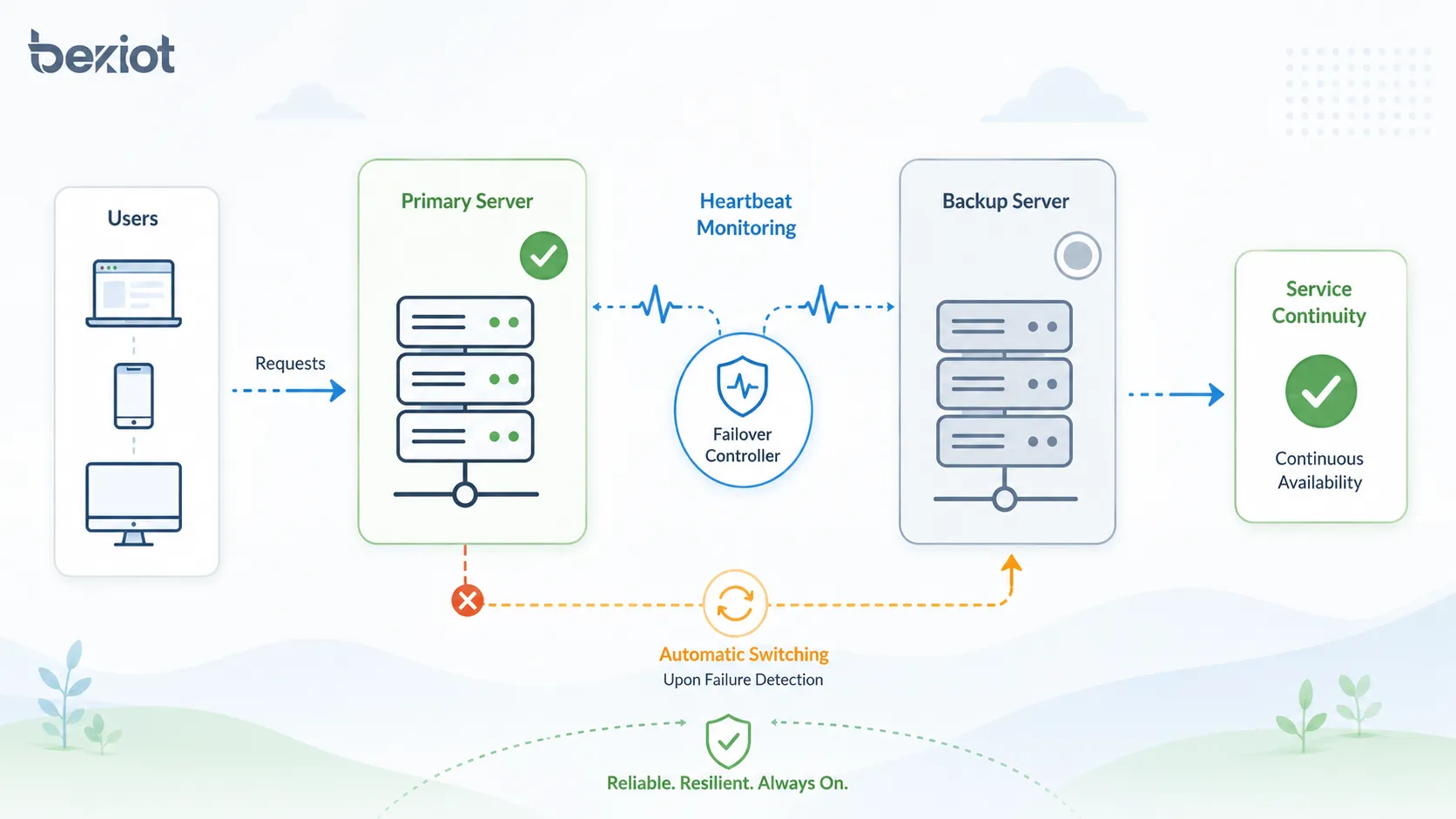
Como funciona o processo de failover
O processo de failover geralmente inclui monitoramento, detecção de falhas, tomada de decisão, troca de serviço, redirecionamento de tráfego, verificação de recuperação e registro de eventos. Os detalhes variam conforme o tipo de sistema, mas a lógica central é semelhante.
Quando o mecanismo de monitoramento detecta que o sistema principal está indisponível ou não saudável, o controlador de failover aciona o caminho de backup. Os usuários podem perceber uma breve interrupção, mas o serviço deve continuar pelo componente de backup.
Monitoramento e verificações de integridade
As verificações de integridade são usadas para confirmar se um serviço está operando corretamente. Uma verificação básica pode testar apenas se um servidor responde a ping. Uma verificação mais avançada pode validar se a aplicação processa solicitações, conecta-se ao banco de dados e retorna respostas válidas.
Verificações no nível da aplicação normalmente são mais confiáveis do que simples testes de rede. Um servidor ainda pode responder a ping enquanto a aplicação nele executada está travada, sobrecarregada ou sem acesso aos serviços de backend necessários.
Comutação para recursos de backup
Depois que a falha é confirmada, o sistema transfere a operação para o recurso de backup. Isso pode envolver alteração de tabelas de roteamento, atualização de registros DNS, movimentação de um endereço IP virtual, promoção de uma réplica de banco de dados, ativação de um servidor em espera ou redirecionamento de tráfego por meio de um balanceador de carga.
O método de comutação deve corresponder ao requisito do negócio. Alguns sistemas toleram alguns minutos de interrupção, enquanto sistemas críticos podem exigir failover quase instantâneo com impacto mínimo ao usuário.
Verificação do serviço após a comutação
Após o failover, o serviço de backup deve ser verificado. O sistema deve confirmar que os usuários conseguem se conectar, as transações podem continuar, os dados estão disponíveis e os serviços dependentes funcionam corretamente.
A verificação é importante porque transferir tráfego para um componente de backup não garante automaticamente uma operação normal. O backup deve estar devidamente sincronizado, configurado corretamente e capaz de lidar com a carga de trabalho.
Principais tipos de failover
O failover pode ser projetado de diferentes maneiras conforme criticidade do sistema, orçamento, requisitos de desempenho e objetivos de recuperação. Os modelos mais comuns incluem ativo-passivo, ativo-ativo, failover manual, failover automático, failover local e failover geográfico.
Failover ativo-passivo
No failover ativo-passivo, um sistema atende ativamente o tráfego de produção enquanto outro permanece em modo de espera. Se o sistema ativo falhar, o sistema passivo se torna ativo e assume o serviço.
Esse modelo é relativamente simples e amplamente usado em servidores, firewalls, bancos de dados, sistemas PBX, controladores de armazenamento e gateways de rede. Sua principal vantagem é a separação clara de papéis. Sua limitação é que os recursos em espera podem ser subutilizados durante a operação normal.
Failover ativo-ativo
No failover ativo-ativo, dois ou mais sistemas atendem o tráfego ao mesmo tempo. Se um sistema falhar, os demais continuam atendendo os usuários e absorvem a carga adicional.
Esse modelo pode melhorar a utilização de recursos e a escalabilidade, mas exige projeto cuidadoso. Balanceamento de carga, sincronização de dados, tratamento de sessões, controle de conflitos e planejamento de capacidade tornam-se mais complexos.
Failover manual e automático
O failover manual exige que um operador ou administrador acione a comutação. Ele oferece controle humano e pode ser útil durante manutenção, migração planejada ou mudanças sensíveis do sistema.
O failover automático é acionado por regras do sistema. É mais rápido e mais adequado para ambientes de alta disponibilidade, mas deve ser configurado com cuidado para evitar falso failover, condições de split-brain ou alternância repetida entre nós.
Failover local e geográfico
O failover local ocorre no mesmo site, rack, data center ou zona de rede. Ele protege contra falhas locais de servidor, link, módulo de energia ou dispositivo.
O failover geográfico transfere o serviço para outro data center, região de nuvem ou site remoto. Ele protege contra falhas maiores, como indisponibilidade de data center, interrupção regional de rede, perda de energia, incêndio, inundação ou grande incidente de infraestrutura.
Recursos essenciais de um projeto confiável
Um bom sistema de failover não deve apenas comutar rapidamente. Ele deve comutar com segurança, consistência e previsibilidade. Os recursos mais importantes incluem monitoramento, redundância, sincronização, controle de tráfego, registro e planejamento de recuperação.
Componentes redundantes
Redundância significa ter componentes de backup disponíveis antes que a falha ocorra. Esses componentes podem incluir servidores, fontes de alimentação, links de rede, roteadores, switches, caminhos de armazenamento, bancos de dados, instâncias de aplicação e regiões de nuvem.
A redundância precisa ser significativa. Um servidor de backup conectado à mesma fonte de alimentação com falha ou ao mesmo switch único pode não oferecer resiliência real. Os projetistas devem evitar pontos únicos de falha ocultos.
Heartbeat e monitoramento de status
Sinais de heartbeat ajudam os sistemas a verificar se o nó principal está vivo. Se o nó em espera deixar de receber mensagens de heartbeat dentro de um período definido, ele pode assumir que o nó principal falhou.
O projeto de heartbeat deve considerar atraso de rede, perda de pacotes e confiabilidade do link de gerenciamento. Uma configuração ruim pode causar problemas de split-brain, em que dois nós acreditam que devem estar ativos.
Sincronização de dados
Muitos sistemas de failover exigem sincronização de dados entre nós principais e de backup. Isso pode envolver replicação de banco de dados, sincronização de arquivos, espelhamento de armazenamento, backup de configuração ou compartilhamento de estado.
A sincronização afeta a qualidade da recuperação. Se o backup tiver dados antigos, o failover pode restaurar o serviço, mas perder transações recentes. Se a sincronização for lenta demais, os objetivos de ponto de recuperação podem não ser atendidos.
Redirecionamento automático de tráfego
O redirecionamento de tráfego permite que usuários ou sistemas alcancem o serviço de backup após o failover. Isso pode ser feito por balanceadores de carga, endereços IP virtuais, protocolos de roteamento, DNS failover, políticas SD-WAN ou gateways de aplicação.
O método de redirecionamento deve corresponder ao tempo de recuperação esperado. O failover baseado em DNS pode ser simples, mas mais lento devido ao cache. O balanceador de carga ou o failover por IP virtual pode ser mais rápido em ambientes locais de alta disponibilidade.
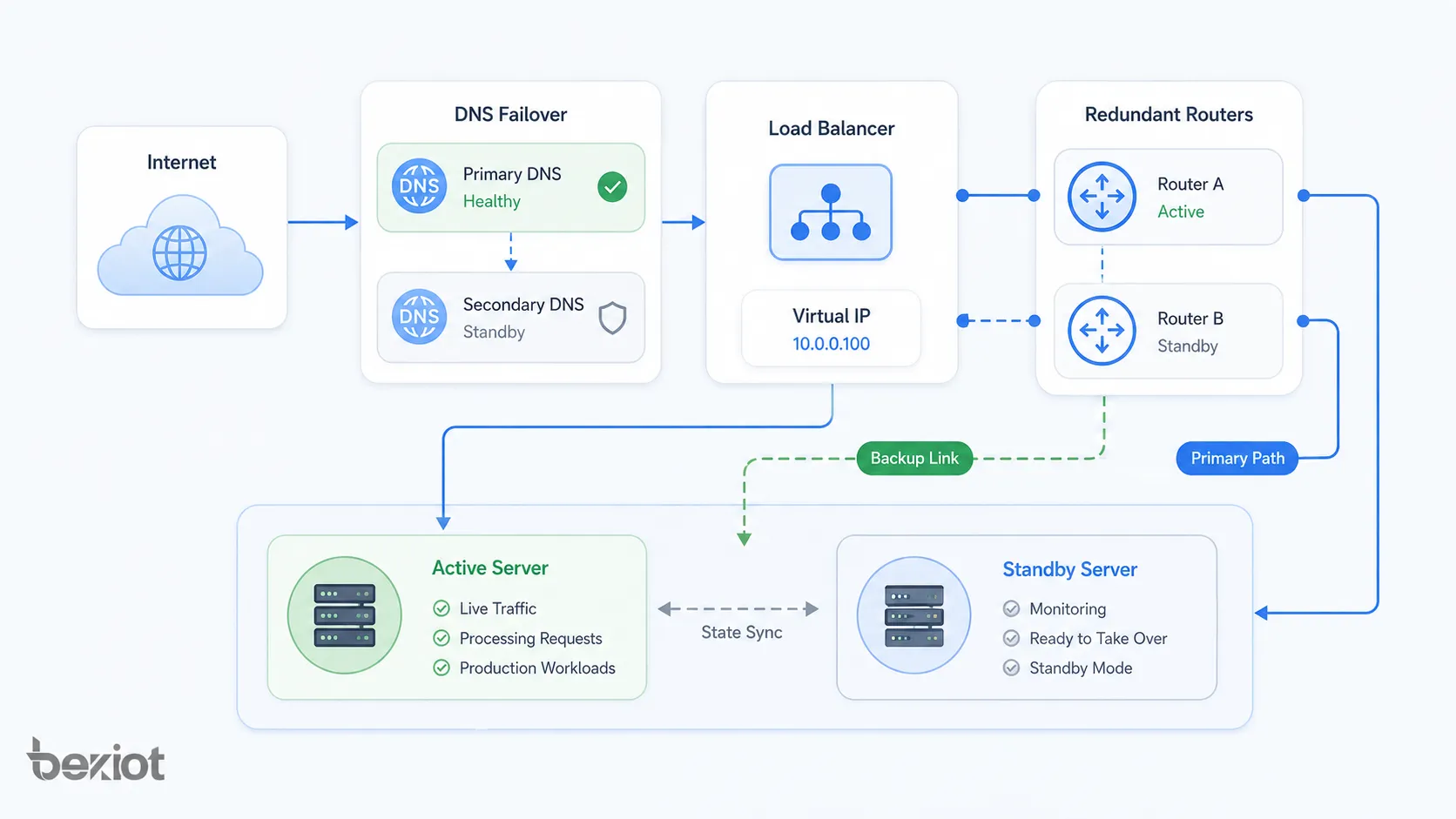
Padrões de arquitetura de rede
A arquitetura de failover pode ser aplicada em diferentes camadas de uma rede e de uma pilha de sistemas. Ela pode proteger links físicos, caminhos de roteamento, clusters de servidores, bancos de dados, regiões de nuvem ou serviços de aplicação.
Failover no nível do servidor
O failover no nível do servidor usa dois ou mais servidores para fornecer o mesmo serviço. Se um servidor falhar, outro assume. Isso é comum em servidores de aplicação, servidores web, servidores de arquivos, servidores de comunicação e plataformas de gerenciamento.
Esse tipo de failover pode usar software de cluster, plataformas de virtualização, balanceadores de carga, orquestração de contêineres ou serviços de alta disponibilidade. A consistência de configuração entre servidores é essencial.
Failover de link de rede
O failover de link de rede usa caminhos de rede de backup quando a conexão principal falha. Exemplos incluem dual WAN, links de fibra de backup, LTE ou 5G de backup, conexões redundantes de ISP e comutação de links SD-WAN.
Isso é importante para filiais, sites remotos, redes varejistas, instalações industriais e sistemas conectados à nuvem. Se o link principal falhar, o link de backup mantém a comunicação disponível, embora largura de banda ou latência possam mudar.
Failover de roteador e firewall
Roteadores e firewalls frequentemente oferecem pares de alta disponibilidade. Um dispositivo pode estar ativo e outro em espera, ou ambos podem compartilhar carga conforme o projeto. Um endereço de gateway virtual costuma ser usado para que os clientes não precisem saber qual dispositivo físico está ativo.
O failover de firewall deve sincronizar o estado das sessões sempre que possível. Sem sincronização de sessão, conexões existentes podem cair durante o failover, mesmo que novas conexões continuem normalmente.
Failover de banco de dados
O failover de banco de dados protege serviços de dados ao trocar de um banco principal com falha para uma réplica ou banco em espera. Ele é usado em aplicações corporativas, plataformas de e-commerce, sistemas financeiros, serviços em nuvem e plataformas operacionais críticas.
Esse failover exige tratamento cuidadoso de atraso de replicação, consistência transacional, conflitos de gravação e reconexão da aplicação. Um projeto ruim pode causar perda de dados ou erros de aplicação.
Failover em nuvem e multirregião
O failover em nuvem pode transferir serviços entre zonas, regiões ou provedores de nuvem. Isso protege contra falhas de infraestrutura local e apoia estratégias de recuperação de desastres.
O failover multirregião pode exigir gerenciamento global de tráfego, bancos de dados replicados, sincronização de armazenamento de objetos, disponibilidade do serviço de identidade e procedimentos de recuperação testados. O projeto deve corresponder aos objetivos de tempo e ponto de recuperação.
Métricas e metas de planejamento
O planejamento de failover costuma ser guiado por métricas de disponibilidade e recuperação. Essas métricas ajudam as organizações a decidir quanta redundância é necessária e quanto tempo de indisponibilidade ou perda de dados é aceitável.
| Métrica | Significado | Por que importa |
|---|---|---|
| RTO | Objetivo de tempo de recuperação | Tempo máximo aceitável para restaurar o serviço após uma falha |
| RPO | Objetivo de ponto de recuperação | Quantidade máxima aceitável de perda de dados medida em tempo |
| MTTR | Tempo médio para reparo | Tempo médio necessário para restaurar um componente com falha |
| MTBF | Tempo médio entre falhas | Tempo operacional médio entre falhas |
| Disponibilidade | Percentual de tempo em que um serviço está operacional | Mostra o desempenho geral de uptime do serviço |
Objetivo de tempo de recuperação
O objetivo de tempo de recuperação define a rapidez com que um serviço deve ser restaurado após uma falha. Uma ferramenta interna de relatórios não crítica pode tolerar horas de indisponibilidade, enquanto um sistema de pagamento, uma plataforma de emergência ou um sistema de controle de produção pode exigir recuperação em segundos ou minutos.
Um RTO menor geralmente exige mais investimento em automação, redundância, monitoramento e infraestrutura. O projeto deve corresponder ao impacto no negócio, em vez de assumir que todos os sistemas precisam do mesmo nível de proteção.
Objetivo de ponto de recuperação
O objetivo de ponto de recuperação define quanta perda de dados é aceitável. Se uma organização só pode tolerar alguns segundos de dados perdidos, pode precisar de replicação quase em tempo real. Se puder tolerar várias horas, backups programados podem ser suficientes.
O RPO é especialmente importante para bancos de dados, sistemas de arquivos, plataformas transacionais, registros de clientes e logs operacionais. Failover sem planejamento de dados pode restaurar o serviço, mas ainda criar perda de negócio inaceitável.
Benefícios para negócios e operações
O failover gera valor porque a indisponibilidade afeta receita, segurança, produtividade, confiança do cliente e continuidade operacional. Uma estratégia bem desenhada ajuda as organizações a manter o serviço durante falhas inesperadas e manutenção planejada.
Maior disponibilidade do serviço
O principal benefício é a melhoria da disponibilidade. Quando um componente principal falha, o componente de backup continua o serviço. Isso reduz a indisponibilidade e ajuda os usuários a continuar trabalhando.
Alta disponibilidade é importante para serviços online, sistemas de comunicação, plataformas de saúde, redes de transporte, automação industrial, sistemas financeiros e aplicações voltadas ao público.
Redução do risco operacional
O failover reduz o risco de que a falha de um único componente pare todo o sistema. Isso é especialmente importante para sistemas com pontos únicos de falha, como um único link de internet, servidor, banco de dados ou gateway.
Ao adicionar caminhos de backup e lógica de recuperação automatizada, as organizações podem reduzir o impacto de falhas de hardware, quedas de rede, travamentos de software e interrupções de manutenção.
Maior flexibilidade de manutenção
O failover pode apoiar manutenção planejada. Administradores podem mover o serviço de um nó para outro, atualizar o sistema principal, testar mudanças e depois retornar quando o trabalho estiver concluído.
Isso reduz a necessidade de longas janelas de manutenção. Também torna as atualizações mais seguras, porque o serviço pode permanecer disponível por meio de recursos de backup.
Maior confiança dos usuários
Os usuários talvez não vejam o processo de failover diretamente, mas percebem quando os serviços permanecem disponíveis. Sistemas confiáveis aumentam a confiança do cliente, a produtividade dos colaboradores e a confiança na infraestrutura digital.
Para plataformas críticas de comunicação, industriais e de negócios, disponibilidade não é apenas uma métrica técnica. Ela faz parte da experiência do serviço.
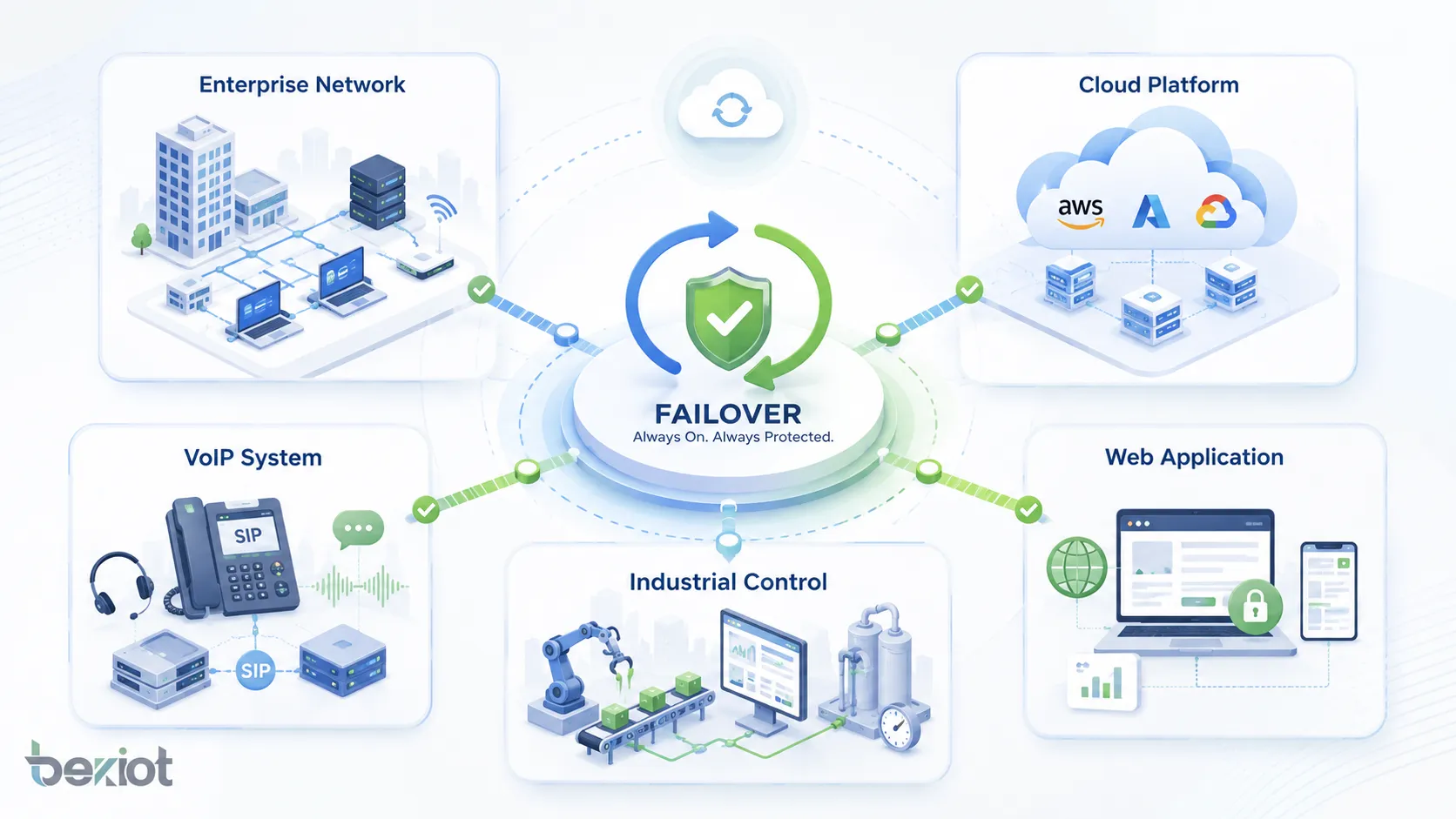
Aplicações em diferentes sistemas
O failover é usado onde a continuidade é importante. O projeto exato depende do tipo de sistema, mas o objetivo permanece o mesmo: evitar interrupção do serviço quando algo falha.
Redes empresariais
Redes empresariais usam failover para links de internet, firewalls, roteadores, switches, túneis VPN, controladores sem fio e conectividade de filiais. Se um caminho falhar, o tráfego pode migrar para outro.
Em organizações com várias filiais, o failover ajuda escritórios remotos a permanecer conectados a serviços em nuvem, data centers, sistemas de comunicação e aplicações de negócios.
Data centers e plataformas em nuvem
Data centers usam failover para servidores, armazenamento, bancos de dados, clusters de virtualização, sistemas de energia, refrigeração e malhas de rede. Plataformas em nuvem usam zonas de disponibilidade, failover regional, balanceadores de carga, grupos de autoescalonamento e réplicas gerenciadas de banco de dados.
Esses projetos ajudam aplicações a sobreviver a falhas de hardware, host, rack ou até interrupções regionais de serviço quando bem planejados.
Sistemas VoIP e de comunicação
Sistemas VoIP e SIP podem usar failover para servidores SIP, plataformas PBX, gateways, SBCs, trunks SIP, registros DNS SRV, servidores de mídia e links de rede. Se um servidor ou trunk falhar, chamadas podem ser roteadas por um caminho de backup.
Isso é importante para comunicação empresarial porque falhas nos serviços de voz podem afetar contato com clientes, coordenação interna, chamadas de emergência e operações de atendimento.
Tecnologia industrial e operacional
Ambientes industriais podem usar failover para servidores SCADA, redes de controle, plataformas de monitoramento, estações HMI, historiadores, gateways industriais e links de comunicação. O objetivo é manter disponíveis produção, monitoramento e operações relacionadas à segurança.
O projeto de failover industrial deve considerar comunicação determinística, compatibilidade de dispositivos, condições ambientais e procedimentos operacionais seguros. A comutação automática não deve criar comportamento inseguro de máquinas.
Aplicações web e serviços online
Aplicações web usam failover por meio de balanceadores de carga, servidores de aplicação replicados, réplicas de banco de dados, serviços CDN, DNS failover e implantação multirregião. Esses métodos ajudam sites e APIs a permanecerem disponíveis durante falhas de servidor ou rede.
Para e-commerce, bancos, SaaS, streaming e portais de clientes, o failover pode proteger receita e experiência do usuário durante interrupções inesperadas.
Desafios e riscos comuns
O failover melhora a resiliência, mas um projeto ruim pode criar novos problemas. O sistema de backup deve ser testado, atualizado, sincronizado e dimensionado corretamente. Caso contrário, o failover pode falhar quando for mais necessário.
Falso failover
O falso failover acontece quando o sistema comuta para o backup mesmo que o serviço principal não tenha realmente falhado. Isso pode ser causado por perda temporária de pacotes, resposta lenta, monitoramento sobrecarregado ou limites agressivos demais.
O falso failover pode interromper usuários desnecessariamente. As verificações de integridade devem ser projetadas para confirmar uma falha real de serviço antes da comutação.
Condição de split-brain
Uma condição de split-brain ocorre quando dois nós acreditam que são o principal ativo. Isso pode acontecer quando a comunicação de heartbeat falha, mas ambos os sistemas ainda estão em execução.
Split-brain é perigoso em bancos de dados, armazenamento e sistemas em cluster porque pode causar corrupção de dados ou gravações conflitantes. Mecanismos de quorum, fencing e bom projeto de cluster ajudam a reduzir esse risco.
Problemas de capacidade do backup
Um recurso de backup deve ter capacidade suficiente para lidar com a carga após o failover. Se o backup for pequeno demais, o serviço pode tecnicamente permanecer online, mas com desempenho ruim.
O planejamento de capacidade deve considerar carga de pico, crescimento, operação em modo degradado e a possibilidade de várias falhas ocorrerem ao mesmo tempo.
Planos de recuperação não testados
Um projeto de failover que nunca foi testado não é confiável. Desvio de configuração, certificados expirados, backups antigos, alterações de firewall, cache DNS, licenças ausentes ou versões antigas de software podem impedir a recuperação bem-sucedida.
Exercícios regulares de failover são necessários. Os testes devem incluir failover planejado e cenários de falha não planejada sempre que possível.
Melhores práticas para implantação confiável
O failover deve ser projetado como parte de uma estratégia mais ampla de alta disponibilidade e recuperação de desastres. Deve incluir planejamento de arquitetura, monitoramento, documentação, testes e melhoria contínua.
Identificar primeiro os serviços críticos
Nem todo sistema precisa do mesmo nível de failover. As organizações devem identificar quais serviços são críticos, como a indisponibilidade afeta as operações e quais objetivos de recuperação são necessários.
Isso ajuda a priorizar investimentos. Sistemas críticos podem exigir failover automático e redundância geográfica, enquanto sistemas menos críticos podem precisar apenas de backup e recuperação manual.
Remover pontos únicos de falha ocultos
O failover pode ser enfraquecido por dependências ocultas. Um servidor de backup pode depender do mesmo armazenamento, fonte de alimentação, switch de rede, serviço DNS ou sistema de autenticação do servidor principal.
A revisão da arquitetura deve identificar essas dependências. Resiliência real exige redundância em todo o caminho do serviço, não apenas na camada visível da aplicação.
Manter a configuração sincronizada
Sistemas principais e de backup devem usar configuração consistente. Diferenças em versão de software, regras de firewall, certificados, políticas de roteamento, dados de usuários ou configurações de aplicação podem causar falha no failover.
Ferramentas de gerenciamento de configuração, modelos, backups e controle de mudanças ajudam a manter os sistemas alinhados. Após qualquer grande mudança, a prontidão para failover deve ser verificada novamente.
Testar o failover regularmente
Testes regulares confirmam se o failover funciona em condições reais. Os testes devem verificar tempo de detecção, tempo de comutação, consistência de dados, comportamento da aplicação, acesso do usuário, registros e procedimento de failback.
Os testes devem ser documentados. Cada teste deve registrar o que foi testado, o que aconteceu, o que falhou e quais melhorias são necessárias.
Failback e recuperação após o failover
O failover é apenas uma parte do processo de recuperação. Depois que o sistema principal é reparado, a organização deve decidir se e como mover o serviço de volta. Esse processo é chamado de failback.
Quando fazer failback
O failback não deve acontecer rápido demais. O sistema principal original deve estar totalmente reparado, testado, sincronizado e verificado antes que o tráfego seja movido de volta. Se o failback for apressado, o sistema pode falhar novamente e criar outra interrupção.
Algumas organizações escolhem manter o sistema de backup ativo até a próxima janela de manutenção. Isso permite um retorno controlado em vez de uma comutação imediata.
Sincronização de dados e estado
Antes do failback, os dados criados durante a operação em backup devem ser sincronizados de volta para o sistema principal original. Isso é especialmente importante para bancos de dados, arquivos, transações, sessões de usuário e mudanças de configuração.
Sem sincronização adequada, o failback pode causar perda de dados, registros desatualizados ou comportamento inconsistente do serviço.
Revisão pós-incidente
Após um evento de failover, as equipes devem revisar o que aconteceu. A revisão deve incluir causa da falha, tempo de detecção, resultado da comutação, impacto ao usuário, desempenho do backup, processo de comunicação e ações de melhoria.
Isso transforma o failover de um evento único de recuperação em um processo contínuo de melhoria da confiabilidade.
FAQ
O que é failover?
Failover é um mecanismo de confiabilidade que transfere serviços, tráfego, cargas de trabalho ou operações de um componente principal com falha para um componente de backup. Ele é usado para reduzir a indisponibilidade e manter a continuidade do serviço.
Qual é a diferença entre failover e backup?
Backup armazena dados ou configurações para recuperação. Failover transfere o serviço ativo para outro recurso quando ocorre uma falha. Backup ajuda a restaurar informações, enquanto failover ajuda a manter o serviço funcionando.
O que é failover ativo-passivo?
Failover ativo-passivo usa um sistema ativo e um sistema em espera. O sistema em espera assume somente quando o sistema ativo falha ou é retirado do ar para manutenção.
O que é failover ativo-ativo?
Failover ativo-ativo usa vários sistemas que tratam tráfego ao mesmo tempo. Se um falhar, os demais continuam atendendo os usuários e assumem a carga adicional.
Onde o failover é comumente usado?
Failover é comumente usado em redes empresariais, plataformas em nuvem, data centers, bancos de dados, aplicações web, sistemas VoIP, firewalls, roteadores, sistemas de armazenamento e plataformas de controle industrial.
Como o failover pode ser testado?
O failover pode ser testado simulando falha do sistema principal, desconectando caminhos de rede de forma controlada, desligando nós de teste, acionando failover de manutenção, verificando a comutação do serviço, validando consistência de dados e revisando logs após a recuperação.







