Um cluster é um grupo de computadores, servidores, gateways, dispositivos, aplicações ou nós de rede conectados que trabalham juntos como um sistema coordenado. Em vez de depender de uma única unidade isolada, um desenho em cluster distribui cargas de trabalho, melhora a disponibilidade, oferece failover e permite que os serviços continuem quando uma parte do sistema fica indisponível.
A palavra “cluster” é usada em muitos campos, incluindo infraestrutura de TI, computação em nuvem, bancos de dados, plataformas de comunicação, telefonia, redes de rádio, automação industrial, armazenamento e edge computing. Embora o desenho técnico possa variar, a ideia central é a mesma: vários componentes cooperam para tornar o sistema mais confiável, escalável e gerenciável.

A ideia básica por trás dos sistemas agrupados
Em um sistema autônomo simples, um único servidor ou dispositivo atende o serviço sozinho. Se essa unidade falhar, o serviço pode parar. Se a demanda dos usuários crescer, ela pode ficar sobrecarregada. Se for necessária manutenção, pode ser difícil evitar interrupção.
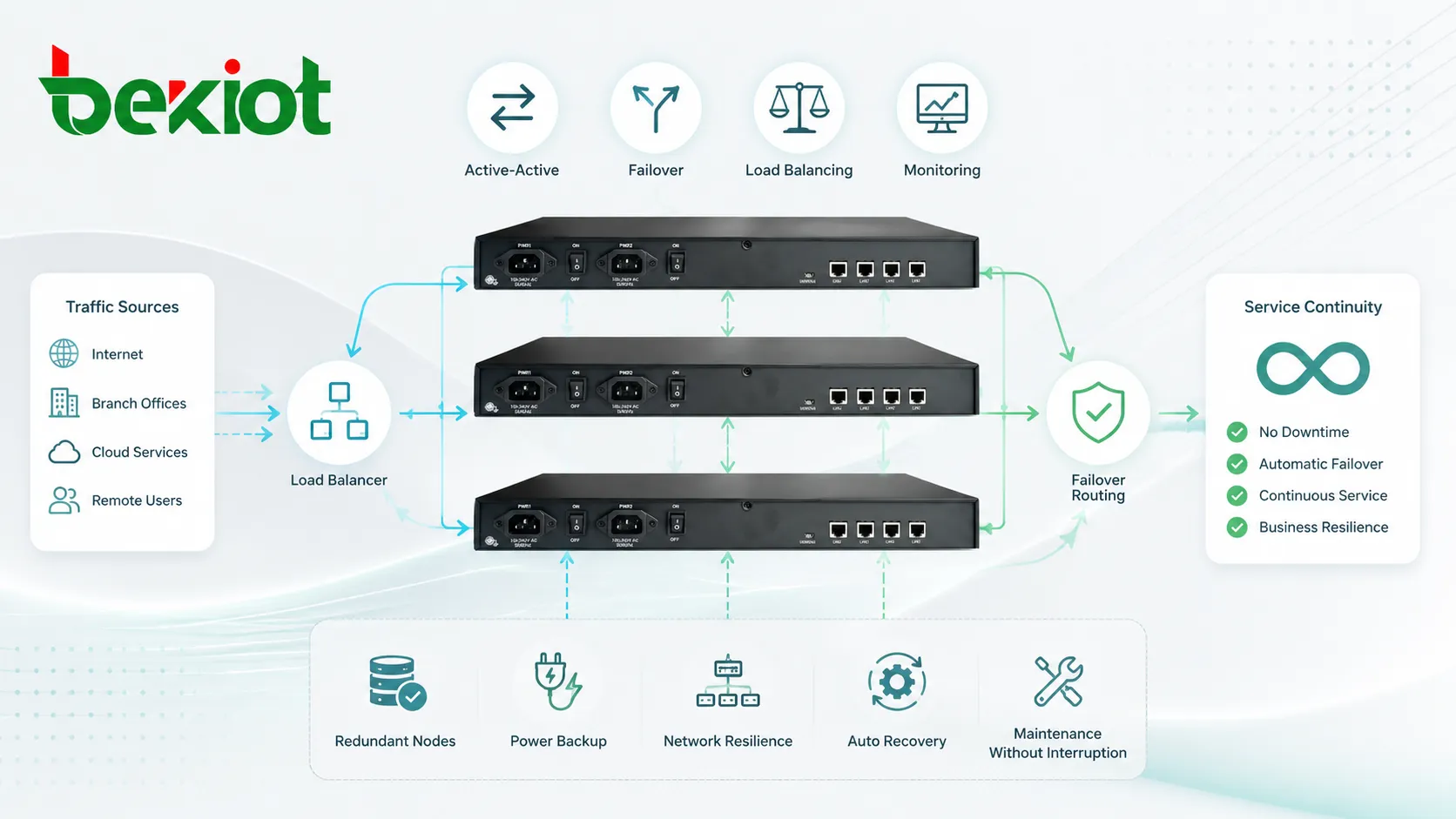
Um sistema em cluster muda esse modelo. Vários nós são conectados por uma rede e gerenciados sob regras comuns. Um nó pode atender a carga atual, outro pode aguardar como reserva, ou todos os nós podem processar tráfego juntos. O desenho depende do objetivo do sistema.
Por exemplo, em uma plataforma de comunicação empresarial, vários servidores podem compartilhar registro de usuários, roteamento de chamadas, gravação ou processamento de mídia. Em um ambiente Radio over IP, vários gateways podem conectar canais de rádio distribuídos, centros de despacho e redes IP para manter a comunicação entre sites.
Como os nós agrupados trabalham juntos
Participação dos nós
Um nó é uma unidade participante dentro do sistema. Pode ser um servidor físico, máquina virtual, gateway, controlador, dispositivo de armazenamento, terminal de comunicação ou serviço de software. Cada nó tem uma função definida e se comunica com outros nós pela rede.
Alguns nós podem executar a mesma função, enquanto outros têm tarefas especializadas. Em um banco de dados, um nó pode aceitar gravações e outros replicar dados. Em um sistema de comunicação, um nó pode cuidar da sinalização enquanto outro gerencia mídia, gravação ou acesso a gateways.
Heartbeat e verificação de integridade
Muitos sistemas em cluster usam sinais de heartbeat para verificar se os nós estão ativos. Um heartbeat é uma mensagem de status trocada regularmente entre nós ou enviada a um controlador de gerenciamento. Se um nó para de responder, o sistema presume que ele pode ter falhado.
A verificação de integridade também pode monitorar uso de CPU, memória, rede, resposta da aplicação, estado de processos, espaço em disco, conexão de gateway ou registro de dispositivos. Isso ajuda o sistema a decidir se um nó deve continuar atendendo tráfego ou ser removido temporariamente.
Distribuição de carga de trabalho
Alguns sistemas em cluster distribuem trabalho entre vários nós. Isso pode ser feito por balanceadores de carga, políticas de roteamento, filas compartilhadas, bancos de dados distribuídos ou coordenação em nível de aplicação. O objetivo é evitar que um nó fique sobrecarregado enquanto outros permanecem ociosos.
A distribuição de carga melhora desempenho e escalabilidade, mas também exige tratamento correto de sessões, sincronização de dados, capacidade de rede e monitoramento. Um método mal desenhado pode gerar carga desigual ou instabilidade do serviço.
Comportamento de failover
Failover significa que, quando um nó falha, outro assume sua função. Em um desenho ativo-standby, o nó reserva pode permanecer ocioso até que o ativo falhe. Em um desenho ativo-ativo, vários nós já atendem tráfego e podem absorver carga adicional quando um nó sai do ar.
O failover deve ser testado com cuidado. Um nó reserva só é útil se tiver a configuração correta, dados atuais, acesso de rede, capacidade de licença e estado da aplicação necessários para continuar o serviço.
Um desenho em cluster não é apenas adicionar mais equipamentos. É coordenar nós para que falhas, crescimento e manutenção sejam tratados sem interrupções desnecessárias.
Padrões de arquitetura que você pode encontrar
Desenho ativo-standby
Em um desenho ativo-standby, um nó fornece o serviço enquanto outro espera como reserva. Se o nó ativo falha, o standby assume. Esse modelo é comum em sistemas nos quais consistência e failover controlado são mais importantes do que usar todos os nós ao mesmo tempo.
A vantagem é a simplicidade. A desvantagem é que recursos de reserva podem ficar subutilizados durante a operação normal. Em sistemas críticos, essa capacidade ociosa costuma ser aceitável porque melhora a continuidade.
Desenho ativo-ativo
Em um desenho ativo-ativo, vários nós fornecem serviço ao mesmo tempo. Tráfego ou tarefas são distribuídos entre eles. Se um nó falha, os demais continuam atendendo usuários, embora a capacidade possa ser reduzida.
Esse modelo melhora a utilização de recursos e a escalabilidade. É usado em plataformas de nuvem, aplicações web, sistemas de comunicação, bancos de dados distribuídos e plataformas de serviços multinó.
Implantação com balanceamento de carga
Uma implantação com balanceamento usa um componente frontal para distribuir tráfego entre vários nós de backend. O balanceador pode usar regras como round-robin, menor número de conexões, status de saúde, endereço de origem, prioridade de serviço ou localização geográfica.
Esse desenho é comum em serviços web, plataformas SIP, APIs, servidores de aplicação, sistemas de mídia e portais corporativos. O próprio balanceador também deve ter redundância; caso contrário, pode se tornar um ponto único de falha.
Desenho de borda distribuída
Alguns sistemas colocam nós em locais diferentes em vez de concentrá-los em um único data center. Isso é comum em comunicação de filiais, sites industriais, redes de transporte, integração de rádio, plataformas IoT e segurança pública.
O desenho de borda distribuída reduz a dependência de um site central e pode melhorar a resposta local. Porém, exige sincronização confiável, monitoramento remoto, controles de segurança e procedimentos claros de manutenção.
Por que as organizações usam esse desenho
Maior disponibilidade
A disponibilidade é uma das principais razões para usar sistemas agrupados. Se uma unidade isolada falha, o serviço pode parar. Se vários nós coordenados estão disponíveis, outro nó pode continuar o serviço ou assumir a carga afetada.
Isso é importante para plataformas de comunicação, serviços de emergência, aplicações de negócio, sistemas financeiros, saúde, controle industrial e serviços voltados ao cliente, onde downtime causa impacto operacional ou comercial.
Escalabilidade para crescimento
À medida que a demanda aumenta, as organizações podem precisar de mais processamento, mais capacidade de chamadas, maior throughput de banco de dados, mais armazenamento, mais canais de gateway ou mais endpoints de serviço. Um desenho em cluster permite crescer adicionando nós, sem substituir todo o sistema.
A escalabilidade é especialmente valiosa quando o tráfego muda ao longo do tempo. Um sistema pode começar pequeno e expandir conforme sites, usuários, canais, serviços ou demanda de clientes aumentam.
Manutenção com menos interrupção
Sistemas em cluster podem facilitar a manutenção. Administradores podem retirar um nó do serviço, atualizá-lo, testá-lo e devolvê-lo à operação enquanto outros nós continuam processando tráfego.
Isso não elimina a necessidade de planejamento. A manutenção ainda deve considerar compatibilidade, sincronização, sessões de usuários, comportamento de failover e rollback. Mas o desenho dá mais flexibilidade do que um sistema de nó único.
Melhor utilização de recursos
Em sistemas ativo-ativo ou balanceados, vários nós compartilham trabalho. Isso melhora a utilização de recursos porque a capacidade não fica limitada a uma única máquina ou dispositivo.
Por exemplo, vários servidores de aplicação podem atender mais usuários que um único servidor. Vários gateways de mídia podem suportar mais canais de voz. Vários nós de armazenamento podem oferecer mais capacidade e resiliência.
Maior resiliência do serviço
Resiliência significa que o sistema pode continuar operando sob estresse, falha parcial, manutenção ou mudança de tráfego. O cluster ajuda ao distribuir responsabilidade e reduzir dependência de um componente único.
Em ambientes mission-critical, a resiliência também deve incluir energia de backup, redundância de rede, separação geográfica, monitoramento, hardening de segurança e procedimentos de recuperação testados.
Componentes técnicos importantes
Configuração compartilhada
Os nós precisam de configuração consistente para se comportarem de forma previsível. Isso pode incluir ajustes de rede, dados de usuários, regras de roteamento, certificados de segurança, parâmetros de serviço, licenças e políticas de aplicação.
Se as configurações divergirem, failover ou compartilhamento de carga podem se tornar pouco confiáveis. Gerenciamento centralizado de configuração ou implantação automatizada reduz esse risco.
Sincronização de dados
Alguns sistemas exigem sincronização de dados entre nós. Isso pode incluir sessões de usuários, estados de chamada, registros de banco de dados, status de filas, registro de dispositivos, dados de voicemail, permissões ou registros de alarme.
O desenho de sincronização é crítico. Se os dados não estão atualizados, um nó reserva pode assumir sem fornecer o estado esperado. Se a sincronização é pesada demais, pode gerar overhead de desempenho.
Quórum e proteção contra split-brain
Em certos clusters, o quórum é usado para decidir quais nós podem tomar decisões. Isso ajuda a evitar situações de split-brain, nas quais duas partes do sistema acreditam estar ativas ao mesmo tempo após uma separação de rede.
Split-brain pode ser perigoso porque gera dados conflitantes, controle duplicado do serviço ou failover instável. Um bom desenho de quórum, fencing e redundância de rede ajuda a reduzir esse risco.
Monitoramento e alertas
Monitoramento é essencial porque clusters podem esconder falhas parciais. Um serviço ainda pode parecer online mesmo que um nó, link, disco, gateway ou processo tenha falhado.
Administradores devem monitorar saúde dos nós, distribuição de tráfego, eventos de failover, status de sincronização, uso de recursos, logs de erro e indicadores de nível de serviço. Alertas devem indicar não apenas que algo falhou, mas qual componente precisa de atenção.
Controle de segurança
Sistemas agrupados geralmente têm mais comunicação interna do que sistemas isolados. Nós podem trocar status, configuração, dados, credenciais ou mensagens de controle. Esses canais devem ser protegidos com autenticação, criptografia, segmentação e controle de acesso.
O acesso administrativo também deve ser controlado. Se um nó for comprometido, o invasor não deve obter automaticamente controle de todo o ambiente.
Cenários de comunicação e gateways
Em redes de comunicação, o conceito de cluster aparece em plataformas PBX, servidores SIP, sistemas de despacho, gateways, redes Radio over IP, plataformas de gravação, contact centers e sistemas de comunicação de emergência. Esses serviços precisam de continuidade porque falhas de comunicação afetam operações diárias, resposta de segurança ou atendimento ao cliente.
Para integração de rádio e despacho, o desenho de gateways em cluster pode conectar vários canais de rádio, redes IP e centros de controle. Um grupo de gateways pode oferecer expansão de canais, failover, acesso remoto e gerenciamento centralizado entre sites.
Por exemplo, o gateway em cluster da série BK-ROIP da Becke Telcom pode ser usado em projetos nos quais sistemas de rádio precisam se conectar a plataformas de despacho IP, centros de comando multisite ou redes corporativas. Nesses cenários, a camada de gateway ajuda a unir voz de rádio, transmissão IP e fluxos de despacho operacional, mantendo a solução escalável e mais fácil de gerenciar.
Aplicações em diferentes setores
Sistemas de TI empresariais
Empresas usam servidores em cluster para aplicações de negócio, bancos de dados, serviços de arquivos, e-mail, identidade e portais internos. Esses sistemas precisam permanecer disponíveis durante falhas de hardware, atualizações de software ou picos de tráfego.
Para TI empresarial, os objetivos principais são uptime, desempenho previsível, manutenção mais fácil e continuidade de negócios. O desenho deve corresponder à importância de cada aplicação.
Nuvem e data centers
Plataformas de nuvem dependem fortemente de recursos agrupados. Nós de computação, armazenamento, controladores de rede e serviços de aplicação são distribuídos pela infraestrutura para que cargas possam escalar e se recuperar de falhas.
Em data centers, esse desenho oferece alta disponibilidade, pool de recursos, virtualização, orquestração de contêineres e migração automatizada de cargas.
Telefonia e comunicações unificadas
Plataformas de voz podem usar servidores agrupados para registro, roteamento de chamadas, serviços de mídia, voicemail, gravação, filas de contact center ou controle de troncos SIP. Isso reduz o risco de que uma falha de servidor interrompa a comunicação de todos os usuários.
Para empresas multisite, nós de comunicação distribuídos também melhoram a sobrevivência local. Uma filial pode continuar a comunicação interna mesmo se a conexão com o site central estiver temporariamente indisponível.
Instalações industriais e de energia
Plantas industriais, utilities, sites de óleo e gás, minas, portos e instalações de energia podem usar sistemas agrupados para monitoramento, despacho, tratamento de alarmes, integração de rádio, controle de acesso e comunicação de sala de controle.
Nesses ambientes, uptime e resiliência são especialmente importantes. O sistema deve ser planejado junto com energia redundante, proteção de rede, condições ambientais e procedimentos de manutenção.
Segurança pública e resposta a emergências
Organizações de resposta a emergências podem usar servidores de comunicação agrupados, plataformas de despacho, gateways de rádio, sistemas de gravação e ferramentas de notificação. O objetivo é manter a comunicação disponível quando a demanda aumenta ou quando parte da infraestrutura falha.
Esses sistemas devem ser testados em condições realistas, incluindo failover, energia de backup, alto volume de chamadas, coordenação multiagência e interrupção de rede.

Planejando a configuração correta
Defina primeiro o objetivo do serviço
Antes de escolher um desenho em cluster, as organizações devem definir o objetivo do serviço. O objetivo pode ser alta disponibilidade, compartilhamento de carga, redundância geográfica, flexibilidade de manutenção, expansão de canais, recuperação de desastres ou integração multisite.
Cada objetivo leva a uma arquitetura diferente. Um sistema desenhado principalmente para failover pode não ser o mesmo que um sistema desenhado para escala de desempenho.
Identifique pontos de falha
Um sistema em cluster ainda pode falhar se outros componentes não forem redundantes. Fonte de energia, switches, roteadores, armazenamento, firewalls, balanceadores, licenças, bancos de dados e plataformas de gerenciamento podem se tornar pontos únicos de falha.
O planejamento deve ir além dos próprios nós. Todo o caminho do serviço precisa ser revisado.
Verifique a compatibilidade da aplicação
Nem toda aplicação ou dispositivo é desenhado para clustering. Alguns sistemas exigem licenças especiais, suporte de banco de dados, lógica de sincronização, armazenamento compartilhado ou arquitetura específica do fornecedor.
A compatibilidade deve ser confirmada antes da implantação. Um desenho que parece bom no papel pode falhar se a aplicação não suportar operação ativo-ativo ou sincronização de estado.
Teste o comportamento de recuperação
O failover deve ser testado antes do uso em produção. Os testes devem incluir falha de nó, interrupção de rede, reinício de serviço, atraso de banco de dados, perda de energia, modo de manutenção e retorno à operação normal.
Testes de recuperação revelam problemas ocultos, como failover lento, sincronização incompleta, roteamento incorreto ou perda de sessão de usuário.
Desafios comuns
Um desafio comum é a complexidade. Mais nós, mais links e mais regras de sincronização criam mais itens para configurar e monitorar. Um sistema em cluster mal gerenciado pode ser mais difícil de diagnosticar do que um sistema simples isolado.
Outro desafio é a falsa confiança. Algumas organizações assumem que adicionar nós cria automaticamente alta disponibilidade. Na realidade, o desenho completo deve incluir redundância, monitoramento, lógica de failover, recuperação testada e manutenção qualificada.
Custo também é uma consideração. Nós extras, licenças, armazenamento, switches, gateways, módulos de software e serviços de suporte podem aumentar o custo do projeto. O investimento deve corresponder ao risco de negócio de downtime ou capacidade limitada.
Um sistema em cluster deve ser desenhado em torno de requisitos reais de serviço, não da ideia de que mais nós automaticamente significam mais confiabilidade.
Manutenção e operação
A manutenção regular deve incluir verificações de saúde dos nós, revisão de configuração, validação de backup, testes de failover, análise de logs, monitoramento de desempenho e atualizações de segurança. Um cluster que nunca é testado pode falhar inesperadamente quando mais se precisa dele.
Administradores também devem observar desvios de configuração. Quando um nó é atualizado manualmente e outro não, o comportamento pode se tornar inconsistente. Ferramentas automatizadas e controle de mudanças documentado ajudam a reduzir esse risco.
A capacidade deve ser revisada ao longo do tempo. Se um nó falhar, os nós restantes devem ter capacidade suficiente para cargas críticas. Caso contrário, o failover pode manter o serviço online, mas com desempenho inaceitável.
Como escolher uma solução adequada
A solução correta depende do tipo de carga, importância do serviço, escala de usuários, distribuição de sites, requisitos de recuperação e orçamento. Uma pequena aplicação de escritório pode precisar apenas de backup e restauração básicos, enquanto uma plataforma carrier-grade pode exigir redundância ativo-ativo em vários sites.
Para projetos de comunicação, a seleção deve considerar capacidade de chamadas, capacidade de canais, compatibilidade SIP, tratamento de mídia, integração de rádio, redundância de gateways, gerenciamento centralizado, logs e comportamento de failover. Se a solução conecta rádio, despacho IP e comunicações corporativas, escalabilidade do gateway e resiliência por site tornam-se especialmente importantes.
As organizações também devem considerar a manutenção de longo prazo. A solução precisa ser compreensível, documentada, monitorada e suportável pela equipe responsável pela operação diária.
FAQ
Uma pequena empresa pode usar sistemas em cluster?
Sim. Uma pequena empresa pode não precisar de uma plataforma multinó complexa, mas ainda pode usar desenhos simples de alta disponibilidade, como firewalls redundantes, servidores de backup, armazenamento replicado ou serviços gerenciados em nuvem.
Clustering sempre exige hardware idêntico?
Nem sempre. Alguns sistemas exigem hardware ou versões de software idênticas, enquanto outros permitem nós mistos. Porém, diferenças de capacidade ou versão podem afetar desempenho, failover e suporte.
Qual é a diferença entre redundância e clustering?
Redundância significa ter componentes de reserva. Clustering é um desenho coordenado em que vários componentes trabalham juntos sob uma lógica compartilhada. Um cluster geralmente inclui redundância, mas redundância sozinha nem sempre significa que o sistema é clusterizado.
Por que o failover às vezes demora mais que o esperado?
O failover pode ser atrasado por temporizadores de health check, sincronização de banco de dados, tempo de inicialização do serviço, convergência de roteamento, cache DNS, recuperação de sessão ou etapas de aprovação manual. Esses fatores devem ser testados antes da produção.
O que deve ser documentado após a implantação?
A documentação deve incluir funções dos nós, endereços IP, dependências de serviço, regras de failover, contas de gerenciamento, limites de monitoramento, procedimentos de backup, janelas de manutenção, passos de recuperação e responsabilidades de contato.