Um problema de banco de dados raramente fica limitado ao próprio banco. Quando a única cópia dos dados fica lenta, inacessível, corrompida ou sobrecarregada, o sistema de negócios acima dela sente o impacto imediatamente: pedidos não são registrados, relatórios não são gerados, dispositivos não enviam registros, usuários não conseguem entrar e a recuperação vira uma corrida contra o tempo.
A replicação de banco de dados existe por esse motivo. Ela cria uma ou mais cópias adicionais dos dados e as mantém sincronizadas com o banco de origem, permitindo que os sistemas leiam mais rápido, recuperem mais rápido, distribuam cargas de trabalho e continuem operando quando um único nó de banco de dados já não é suficiente.
A ideia básica por trás da replicação de banco de dados
A replicação de banco de dados é o processo de copiar dados de um nó de banco para outro e manter essas cópias atualizadas à medida que ocorrem alterações. O banco de origem pode ser chamado de primário, mestre, publicador ou líder, conforme a tecnologia. O banco que recebe os dados pode ser chamado de réplica, standby, assinante, secundário ou seguidor. Os nomes mudam, mas o objetivo é semelhante: levar as alterações feitas em um lugar para outro de forma controlada.
Os dados copiados podem incluir bancos completos, tabelas selecionadas, partições, esquemas, logs de transações ou fluxos específicos. Em alguns sistemas, a réplica serve apenas para backup ou failover. Em outros, ela atende leituras, análises, relatórios, acesso regional ou processamento downstream. Portanto, replicação não é uma função fixa; é um método de projeto para diferentes metas operacionais.
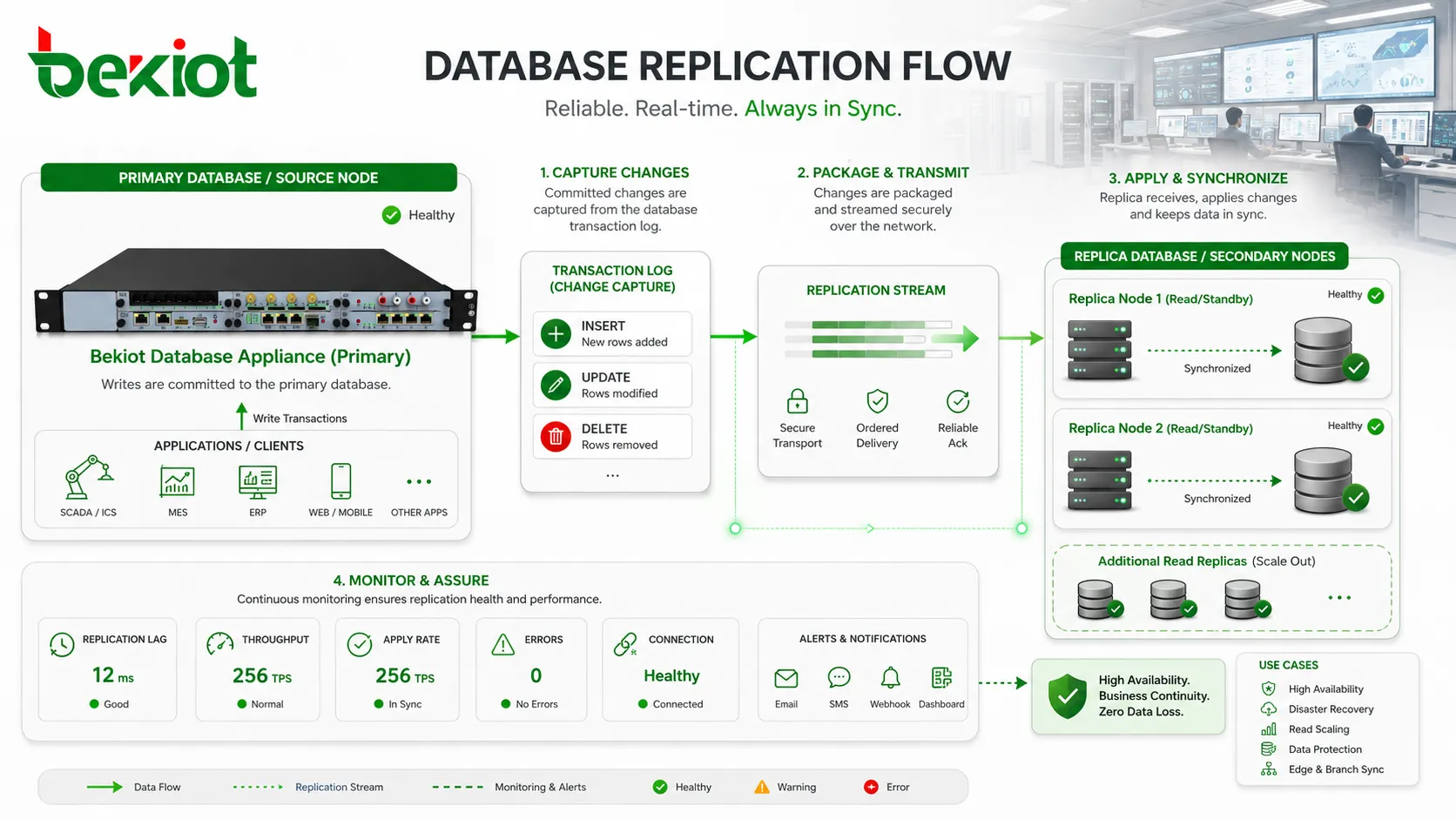
No centro da replicação está o rastreamento de mudanças. Quando dados são inseridos, atualizados ou excluídos, o banco precisa identificar a mudança, empacotá-la de modo confiável, enviá-la a outro nó e aplicá-la na ordem correta. Se isso for feito sem rigor, a réplica pode ficar inconsistente. Se for lento, a réplica fica atrasada. Se não for monitorado, a equipe pode descobrir o problema apenas quando precisar recuperar o serviço.
Um bom desenho de replicação responde perguntas práticas: quais dados devem ser copiados, com que rapidez devem chegar, quem pode escrever, como conflitos serão tratados, o que acontece em falhas de rede e como as aplicações devem agir quando um nó não está disponível. Essas respostas definem se a replicação será uma ferramenta de resiliência ou uma fonte oculta de confusão.
O que realmente se move entre os nós do banco
Replicação nem sempre é uma simples cópia de arquivos. Na maioria dos sistemas de produção, o banco não reenviará todo o conjunto de dados sempre que um registro mudar. Ele captura a alteração e transfere apenas o necessário para reproduzi-la na réplica. Isso reduz o consumo de banda e mantém a réplica próxima da origem sem reconstrução completa.
Um método comum é a replicação baseada em logs. O banco primário registra alterações em logs de transações, logs binários, write-ahead logs ou redo logs. A réplica lê esses logs e aplica as mesmas operações em sequência. Esse método é amplamente usado porque o log já representa a ordem autorizada das mudanças.
Outro método é a replicação baseada em instruções, em que comandos SQL são enviados à réplica. Ela pode ser mais simples em alguns sistemas, mas pode gerar diferenças quando a instrução depende de funções não determinísticas, valores de tempo, valores aleatórios ou comportamento específico do ambiente. A replicação baseada em linhas evita muitos desses problemas ao enviar as alterações reais das linhas.
Alguns sistemas usam replicação por snapshot. Uma cópia total ou parcial dos dados é tirada em um ponto no tempo e entregue a outro local. Isso é útil para sincronização inicial, bancos de relatório ou distribuição periódica. Porém, snapshots sozinhos não bastam para sistemas que exigem atualização quase em tempo real.
Arquiteturas modernas também podem usar captura de dados de mudança, ou CDC. O CDC extrai alterações do banco e as envia a plataformas analíticas, índices de busca, filas de mensagens ou data lakes. Nesse caso, a replicação deixa de ser apenas a manutenção de outra cópia de banco e passa a fazer parte do pipeline de movimentação de dados da organização.
Replicação primário-réplica na operação diária
O padrão mais conhecido é a replicação primário-réplica. Um nó aceita escritas, enquanto uma ou mais réplicas recebem cópias das alterações. As aplicações enviam inserções, atualizações e exclusões ao primário. Consultas somente leitura podem ser enviadas às réplicas se a aplicação e a arquitetura suportarem isso.
Esse padrão é fácil de entender e muito utilizado porque mantém clara a propriedade da escrita. O primário é a autoridade das mudanças; as réplicas seguem seu estado. Se uma réplica falhar, o primário continua operando. Se o primário falhar, uma réplica pode ser promovida a novo primário, conforme o desenho de failover.
O benefício é a separação prática de carga. Escritas transacionais, operações de usuários e atualizações de negócio ficam no primário, enquanto relatórios, dashboards, pesquisas ou serviços com muitas leituras podem usar réplicas. Isso reduz pressão no banco principal e melhora o tempo de resposta.
Ainda assim, as aplicações precisam entender que réplicas nem sempre estão perfeitamente atuais, especialmente em replicação assíncrona. Um usuário que grava no primário e lê imediatamente de uma réplica atrasada pode não ver a alteração mais recente. Isso não é necessariamente falha; é uma compensação de projeto que deve ser tratada com cuidado.
Padrões multi-primário e distribuídos
Alguns ambientes precisam de mais de um nó gravável. Na replicação multi-primário, vários nós aceitam escritas e replicam as alterações entre si. Isso pode apoiar sites distribuídos, operações regionais, escrita local ou alta disponibilidade entre data centers. A proposta é atraente, mas é mais complexa que o modelo primário-réplica.
O principal desafio é o conflito. Se dois nós atualizam o mesmo registro ao mesmo tempo, o sistema precisa decidir qual mudança vence ou como elas serão combinadas. As regras podem se basear em timestamps, versões, lógica da aplicação, prioridade do nó ou resolução manual. Tratamento inadequado de conflitos prejudica a qualidade dos dados.
A replicação distribuída também aparece em sistemas de borda, lojas, sites industriais, aplicações móveis ou operações remotas onde os dados locais precisam continuar disponíveis quando a rede central é instável. Um nó local pode armazenar e atualizar dados temporariamente e sincronizar com o centro depois. Isso melhora a continuidade local, mas exige regras de sincronização cuidadosas.
Projetos multi-primário só devem ser escolhidos quando a necessidade do negócio justificar a complexidade. Para muitas aplicações, um primário de escrita com réplicas de leitura é mais simples de operar. Onde escritas locais em múltiplos locais são realmente necessárias, conflitos, propriedade dos dados e monitoramento devem ser definidos antes da implantação.
Replicação síncrona e assíncrona
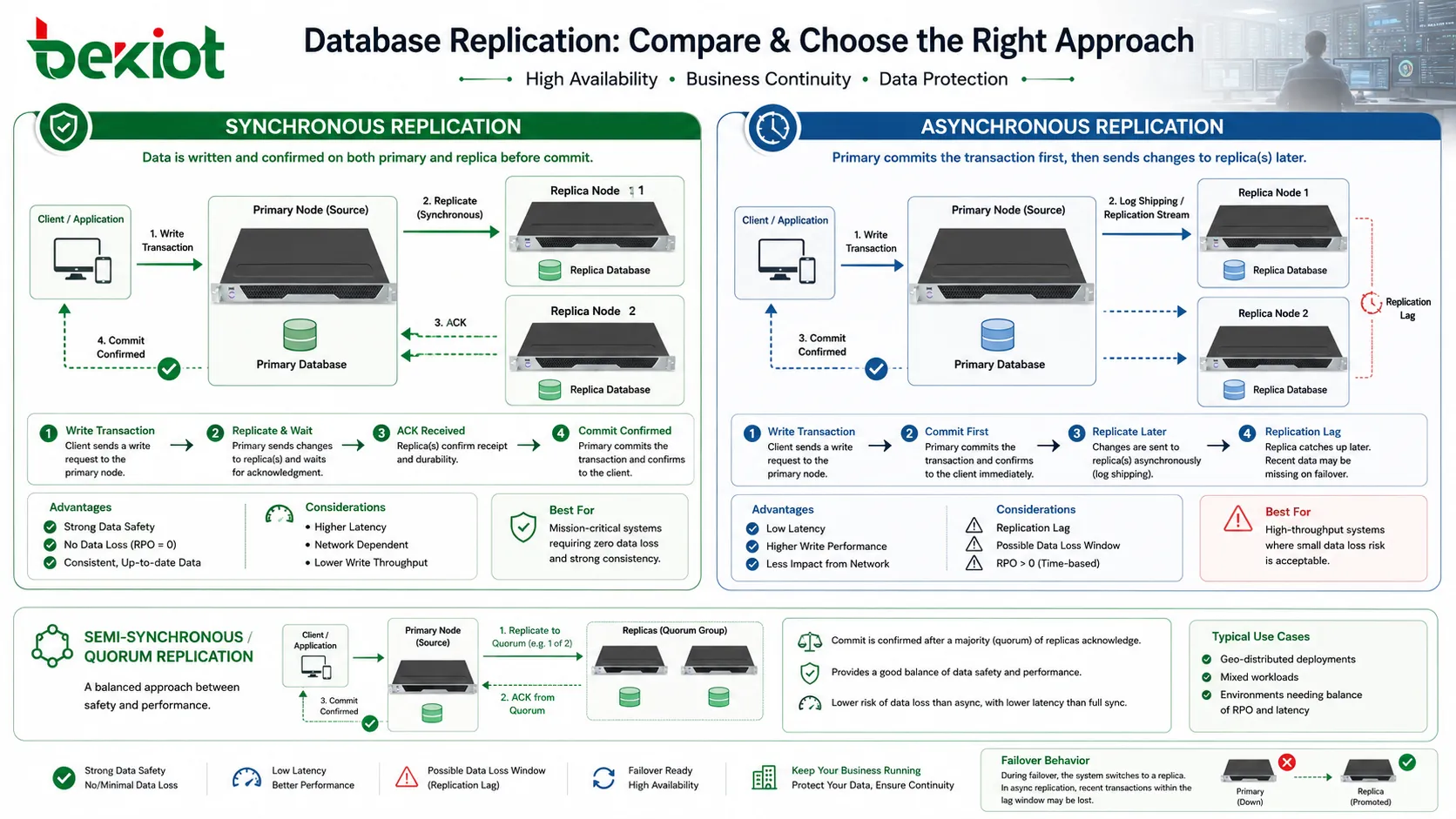
O momento da replicação é uma das decisões mais importantes. Na replicação síncrona, uma transação só é considerada totalmente confirmada quando outro nó confirma a alteração. Isso melhora a segurança dos dados, pois a réplica já possui a mudança antes de a aplicação receber sucesso. Se o primário falhar logo depois, é mais provável que os dados confirmados existam em outro nó.
O custo é a latência. Se a réplica estiver distante ou a rede for lenta, o primário precisa esperar mais para concluir a transação. Isso pode afetar o tempo de resposta da aplicação. A replicação síncrona é usada onde a tolerância à perda de dados é muito baixa e o caminho de rede entre nós é confiável.
Na replicação assíncrona, o primário confirma a transação primeiro e envia a alteração às réplicas depois. Isso melhora o desempenho de escrita, porque a aplicação não espera confirmação remota. É comum em relatórios, escala de leitura ou recuperação de desastres em longas distâncias.
A compensação é o atraso de replicação. Se o primário falhar antes de as mudanças chegarem à réplica, transações recentes podem ser perdidas ou exigir recuperação por logs. Por isso, o modo assíncrono deve estar alinhado a objetivos claros de recuperação, incluindo perda aceitável e tempo esperado para a réplica alcançar o primário.
Alguns sistemas usam métodos semissíncronos ou baseados em quórum para equilibrar desempenho e segurança. Eles confirmam a transação após uma ou mais réplicas responderem, mas não necessariamente esperam todas. A melhor escolha depende do risco de negócio, da rede, do volume de transações e dos requisitos de recuperação.
Vantagens de disponibilidade e failover
O benefício mais direto da replicação é melhorar a disponibilidade. Se o banco primário falhar, uma réplica pode ser promovida para continuar o serviço. Sem replicação, a recuperação pode depender de restauração de backup, que leva mais tempo e pode perder dados mais recentes. A replicação oferece uma cópia viva ou quase viva para restauração mais rápida.
O failover pode ser manual ou automático. O manual dá mais controle aos administradores, útil em ambientes complexos ou quando é preciso evitar split-brain. O automático reduz indisponibilidade, mas deve impedir que dois nós se considerem primários ao mesmo tempo. Em alta disponibilidade, a decisão costuma usar monitoramento, health checks, quórum ou gerenciamento de cluster.
A disponibilidade também depende do comportamento da aplicação. Promover uma réplica não basta se as aplicações não reconectam, se o DNS demora, se pools de conexão continuam usando o endereço com falha ou se usuários precisam mudar configurações manualmente. A replicação deve ser planejada com roteamento da aplicação, balanceadores, strings de conexão, descoberta de serviço e procedimentos operacionais.
Uma réplica também pode apoiar manutenção. Durante atualizações, patches, troca de hardware ou migração de armazenamento, algumas cargas podem ser movidas para outro nó. Isso reduz paradas planejadas e dá mais flexibilidade aos administradores. Bons desenhos atendem tanto recuperação emergencial quanto manutenção rotineira.
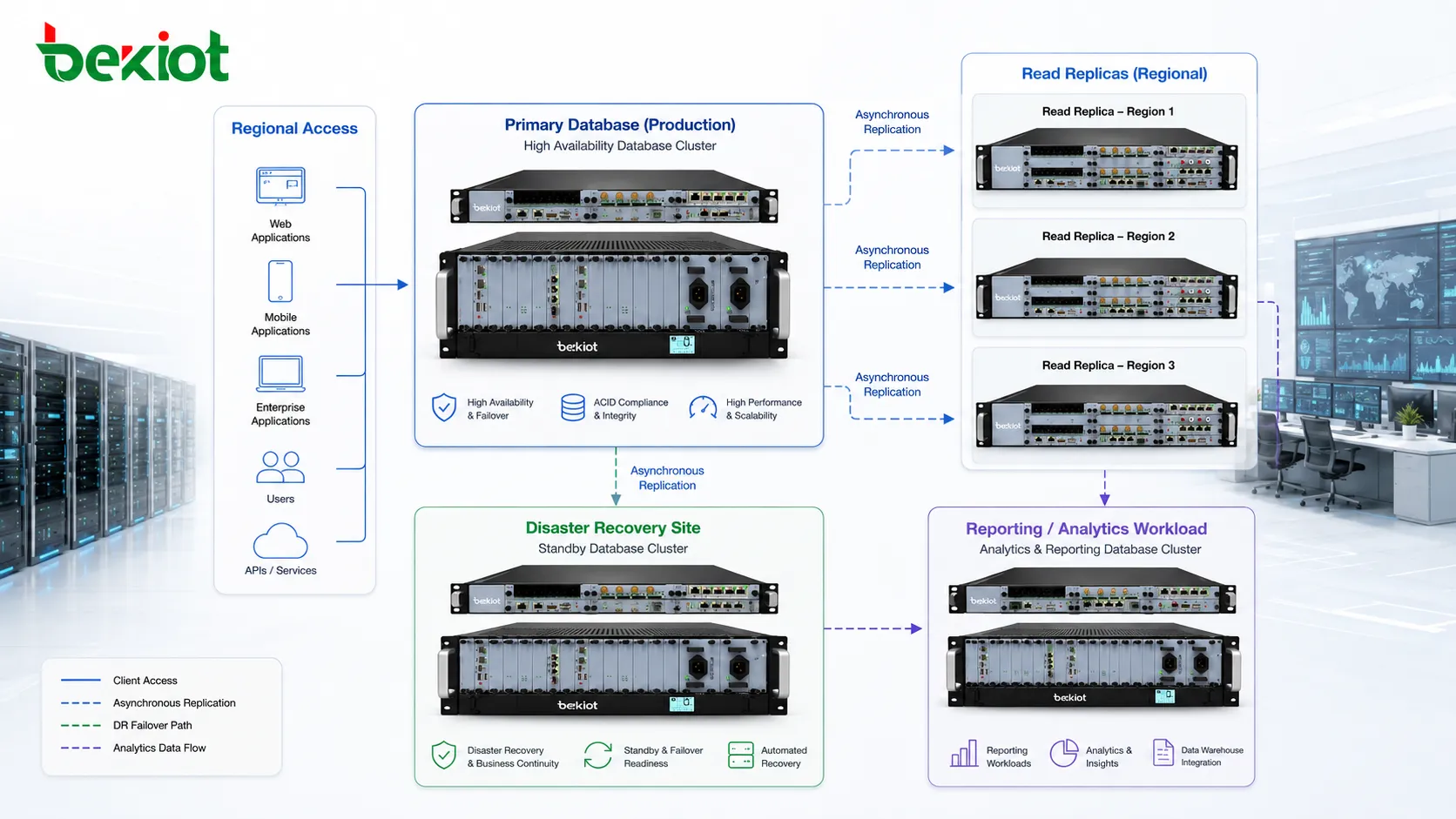
Escala de leitura sem mudar o modelo principal de dados
Muitos bancos sobrecarregam não por excesso de escrita, mas pelo aumento das consultas de leitura. Dashboards, relatórios, páginas de busca, portais de clientes, ferramentas de monitoramento e APIs podem ler do mesmo banco. Se toda leitura atingir o primário, as transações normais ficam lentas. A replicação permite distribuir leituras entre réplicas.
Réplicas de leitura são comuns para relatórios e análises. Consultas longas podem rodar nelas sem bloquear ou degradar o trabalho transacional crítico do primário. Isso é útil quando equipes de negócio precisam de relatórios frequentes e o banco de produção deve continuar responsivo.
A separação de leitura e escrita na aplicação também melhora a escalabilidade. A aplicação envia escritas ao primário e algumas leituras às réplicas. É preciso cuidado porque réplicas podem atrasar. Dados que exigem consistência imediata talvez ainda precisem ser lidos do primário; dados que toleram pequeno atraso são adequados para réplicas.
Esse caminho aumenta a capacidade de leitura sem redesenhar todo o modelo de dados. Em vez de migrar imediatamente para outra arquitetura, a equipe pode adicionar réplicas, otimizar roteamento de consultas e separar cargas de relatório. Frequentemente é uma etapa prática no crescimento do banco.
Recuperação de desastres e resiliência geográfica
A replicação é muito usada para recuperação de desastres. Uma réplica em outro data center, região de nuvem ou local físico pode proteger contra incêndio, queda de energia, interrupção de rede, falha de armazenamento ou desastre no site. Se o primário ficar indisponível, a réplica remota pode oferecer um caminho de recuperação.
A replicação geográfica exige cuidado porque a distância aumenta a latência. Replicação síncrona em longas distâncias pode ser lenta demais para algumas aplicações. A assíncrona é mais comum para recuperação remota, mas pode causar perda de dados se o site primário falhar antes que todas as mudanças sejam copiadas.
O planejamento deve definir RTO e RPO. RTO descreve quão rápido o serviço deve voltar. RPO descreve quanta perda de dados é aceitável. Um sistema com RPO estrito pode precisar de proteção mais síncrona ou atraso muito baixo. Um sistema com RPO flexível pode usar replicação assíncrona com verificações periódicas.
A recuperação de desastres também precisa de testes. Uma réplica que nunca foi promovida, verificada com aplicações ou restaurada em condições realistas pode não ser confiável no desastre real. A replicação fornece a base técnica; os exercícios provam se o processo funciona.
Localidade de dados e desempenho regional
A replicação pode aproximar os dados de usuários, filiais ou aplicações regionais. Quando usuários em locais diferentes leem de uma réplica próxima, o tempo de resposta melhora. Isso ajuda aplicações globais, serviços multi-região, redes varejistas, logística, plataformas financeiras e sistemas empresariais distribuídos.
Réplicas regionais também reduzem pressão em links centrais. Em vez de enviar cada consulta por uma conexão longa, usuários ou serviços locais leem de uma cópia próxima. Isso é útil quando o tráfego de leitura é alto e a exigência de atualização imediata é administrável.
A localidade também apoia relatórios locais. Um escritório regional pode analisar transações, estoque, registros de serviço ou dados operacionais sem carregar continuamente o banco central de produção. Um banco local replicado oferece esse acesso enquanto o sistema central foca nas transações principais.
Ainda assim, a replicação regional deve respeitar governança de dados. Algumas informações podem ser restringidas por leis de privacidade, políticas internas, contratos ou regulamentações. Copiar dados para outra região ou país pode exigir aprovação, criptografia, controle de acesso ou minimização. A replicação deve melhorar desempenho sem enfraquecer governança.
Backup não é a mesma coisa que replicação
Replicação e backup costumam ser citados juntos, mas resolvem problemas diferentes. Replicação mantém outra cópia atualizada para disponibilidade, desempenho ou distribuição. Backup cria cópias históricas recuperáveis após exclusão, corrupção, ransomware, alterações acidentais ou perda de longo prazo.
Uma réplica pode copiar fielmente um erro. Se um usuário excluir registros importantes no primário, a replicação pode removê-los rapidamente na réplica. Se uma aplicação gravar dados corrompidos, a réplica pode receber o mesmo estado. Nesse caso, a replicação não protege a organização sem recuperação point-in-time, replicação atrasada ou backups.
Backups demoram mais para restaurar, mas são mais seguros para recuperação histórica. Eles permitem recuperar dados de um ponto anterior. A replicação é mais rápida para continuidade do serviço, mas pode não oferecer rollback histórico. Uma boa estratégia normalmente inclui replicação e backup.
A distinção deve ser clara no planejamento. Se a meta é failover rápido, replicação ajuda. Se a meta é recuperar dados da semana passada, backup é obrigatório. Se a meta é obter ambos, os dois processos devem ser projetados e testados regularmente.
Monitoramento da saúde da replicação
A replicação deve ser monitorada continuamente. Uma réplica com horas de atraso pode parecer online, mas ser inútil para failover ou imprecisa para relatórios. Pontos comuns incluem atraso de replicação, estado da réplica, progresso de envio de logs, taxa de aplicação, erros, conexão, uso de disco, atraso de transações e falhas de sincronização.
O atraso de replicação é especialmente importante. Ele mede o intervalo entre uma mudança no primário e sua disponibilidade na réplica. Pequeno atraso pode ser aceitável para relatórios. Grande atraso pode quebrar pressupostos da aplicação ou aumentar risco de perda no failover. Limites aceitáveis devem ser definidos por caso de uso.
Armazenamento e capacidade também precisam ser vigiados. A replicação pode gerar logs, arquivos temporários, relay logs, archive logs ou dados intermediários. Se o disco acabar, a replicação pode parar. Se a réplica for fraca, ela não aplicará mudanças rápido o suficiente no pico. A réplica deve ser dimensionada para sua carga.
Alertas operacionais devem ser úteis. Não basta avisar que a replicação falhou; o alerta deve ajudar a identificar se a causa é rede, autenticação, posição de log, disco, esquema, permissão ou escritas conflitantes. Quanto mais cedo a causa for conhecida, mais rápido o caminho de dados volta.
Segurança e controle de acesso
A replicação aumenta o número de locais onde dados sensíveis existem. Cada réplica deve ser protegida com a mesma seriedade do primário. Se uma réplica for menos segura, pode virar o caminho mais fácil para vazamento. O planejamento deve incluir criptografia, controle de acesso, auditoria, restrições de rede e gestão de credenciais para todos os nós.
O tráfego de replicação deve ser protegido, especialmente quando cruza data centers, regiões de nuvem, redes públicas ou links de terceiros. Criptografia em trânsito ajuda a impedir interceptação. Autenticação entre nós impede que sistemas não autorizados entrem na relação. Segmentação de rede reduz exposição a sistemas não relacionados.
Permissões nas réplicas devem ser revisadas separadamente. Uma réplica de relatórios pode ser somente leitura para analistas, mas isso não significa que todas as tabelas devam ser visíveis para todos. Campos sensíveis podem exigir mascaramento, filtragem ou política separada. Em alguns casos, a réplica deve conter apenas os dados necessários.
O acesso administrativo também exige controle. Usuários capazes de parar a replicação, promover uma réplica, alterar filtros ou modificar credenciais têm poder significativo. Essas ações devem ser registradas e restritas a pessoal autorizado. Replicação faz parte da fronteira de confiança do banco, não apenas de uma função em segundo plano.
Erros comuns na implantação
Um erro frequente é implantar replicação sem definir o objetivo real. Se a meta é disponibilidade, o desenho deve incluir failover e reconexão das aplicações. Se a meta é relatório, deve tratar carga e atualização dos dados. Se a meta é recuperação de desastres, deve incluir local remoto, RTO, RPO e testes. Objetivo vago leva a arquitetura vaga.
Outro erro é assumir que a réplica está sempre atual. Réplicas assíncronas podem atrasar. Escritas pesadas, rede instável, discos lentos, mudanças de esquema ou transações longas podem atrasar a replicação. Aplicações que leem réplicas devem ser desenhadas considerando esse atraso.
Algumas equipes não testam promoção. Elas criam réplicas, mas nunca praticam a troca para elas. Na emergência, descobrem problemas de permissão, conexão, tarefas ausentes, configuração incompleta ou dados inconsistentes. O failover deve ser testado antes de ser necessário.
Filtros de replicação também causam confusão. Se apenas certas tabelas ou bancos são replicados, todos devem saber o que está incluído e excluído. Uma equipe de relatórios pode supor que todos os dados estão disponíveis quando só parte do esquema foi copiada. Documentação clara evita falsas suposições.
Por fim, muitas implantações subestimam manutenção. Replicação precisa sobreviver a upgrades, mudanças de esquema, renovação de certificados, rotação de senhas, crescimento de armazenamento, mudanças de rede e diferenças de versão. Não é algo para configurar e esquecer. Precisa de dono.
Quando a replicação traz mais valor
A replicação traz mais valor quando a organização tem necessidade clara de disponibilidade, escala de leitura, recuperação de desastres, distribuição de dados ou separação de cargas. É menos útil quando o banco é pequeno, a tolerância a parada é alta, o tráfego de leitura é leve e a recuperação por backup basta. Como qualquer escolha de arquitetura, deve combinar com o problema.
Para sistemas críticos, pode reduzir downtime e melhorar opções de recuperação. Para aplicações em crescimento, pode mover relatórios e leituras para longe do primário. Para organizações distribuídas, pode apoiar acesso regional. Para equipes de dados, pode entregar dados operacionais a sistemas analíticos sem perturbar a produção.
Os melhores desenhos costumam ser modestos e claros. Eles definem qual nó aceita escritas, quais nós servem leituras, como o atraso é monitorado, como o failover funciona, como backups são mantidos e quem responde pela relação de replicação. Complexidade só deve ser adicionada quando houver forte razão de negócio.
Replicação não é uma cópia mágica de segurança. É uma forma disciplinada de manter dados disponíveis em mais de um lugar. Seus benefícios aparecem quando desenho técnico, comportamento da aplicação, monitoramento, segurança e recuperação são planejados juntos.
Perguntas frequentes
A replicação de banco de dados é usada principalmente para backup?
Não. Ela pode apoiar a recuperação, mas não substitui backup. Uma réplica pode copiar exclusões acidentais ou dados corrompidos do primário. Backups continuam necessários para recuperação histórica e restauração point-in-time.
O que é atraso de replicação?
É o atraso entre uma mudança confirmada no banco primário e a mesma mudança aparecer na réplica. É comum na replicação assíncrona e deve ser monitorado quando réplicas são usadas para leitura ou failover.
As aplicações podem escrever nas réplicas?
Em modelos primário-réplica, as réplicas geralmente são somente leitura. Sistemas multi-primário permitem escrita em mais de um nó, mas exigem tratamento de conflitos e controle operacional mais forte.
A replicação melhora o desempenho?
Pode melhorar ao mover leituras, relatórios e análises para fora do primário. Não acelera automaticamente todas as cargas. Sistemas com muita escrita podem precisar de índices, otimização, particionamento, hardware melhor ou mudanças de arquitetura.
O que deve ser testado antes de confiar na replicação?
Devem ser testados sincronização inicial, atraso sob carga, failover, promoção de réplica, reconexão da aplicação, recuperação por backup, alertas, permissões de segurança e comportamento durante interrupções de rede.