Alta disponibilidade é uma abordagem de design que mantém um sistema, serviço, aplicação ou rede acessível mesmo quando componentes individuais falham. Em vez de depender de um único servidor, banco de dados, caminho de rede, fonte de energia ou processo de software, um sistema de alta disponibilidade utiliza redundância, monitoramento, failover e planejamento de recuperação para reduzir o tempo de inatividade e manter a continuidade do serviço.
Para empresas e organizações que dependem de operações digitais, alta disponibilidade não é apenas um conceito de TI. Ela afeta a experiência do cliente, eficiência da produção, resposta a emergências, confiabilidade das comunicações, acesso a dados, operações de segurança e compromissos de nível de serviço. Uma breve interrupção pode ser aceitável para uma ferramenta interna de baixa prioridade, mas a mesma interrupção é inaceitável para um sistema hospitalar, plataforma de despacho, gateway de pagamento, rede de controle industrial, serviço de comunicação pública ou aplicação em nuvem usada por milhares de usuários.
Significado no Design Prático de Sistemas
Alta disponibilidade, frequentemente abreviada como HA, refere-se à capacidade de um sistema permanecer utilizável por uma alta porcentagem do tempo. É comumente discutida por meio de metas de uptime como 99,9%, 99,99% ou 99,999%. No entanto, disponibilidade não se trata apenas de o servidor estar ligado. Um sistema está verdadeiramente disponível apenas quando os usuários conseguem concluir as ações de que precisam, como fazer uma chamada, enviar uma transação, abrir um aplicativo, receber um alarme, sincronizar registros ou acessar informações em tempo real.
Um serviço confiável depende da cadeia completa de serviço. Isso pode incluir recursos de computação, armazenamento, mecanismos de banco de dados, switches de rede, firewalls, DNS, serviços de identidade, certificados de segurança, processos de aplicação, ferramentas de monitoramento, links de backup, infraestrutura de energia e procedimentos operacionais. Se uma dependência crítica não possui caminho de backup, todo o serviço ainda pode estar vulnerável.
Alta disponibilidade também é diferente de backup comum. Um backup ajuda a restaurar dados após uma falha, mas pode não manter o serviço em execução durante a falha. HA foca na continuidade. Ela permite que outro nó, caminho, instância de serviço ou site assuma o controle antes que os usuários experimentem uma longa interrupção.
Por Que as Organizações Constroem para a Continuidade
O valor da alta disponibilidade fica claro quando o tempo de inatividade gera consequências reais. No comércio eletrônico, inatividade pode significar pedidos perdidos e falhas de pagamento. Nas telecomunicações, pode significar chamadas perdidas, ramais inacessíveis ou roteamento de emergência interrompido. Na manufatura, pode parar fluxos de trabalho de produção. Na saúde e segurança pública, pode atrasar comunicação, coordenação e resposta.
A disponibilidade também protege a confiança. Clientes, funcionários, parceiros e equipes de campo esperam que sistemas modernos estejam acessíveis a qualquer momento. Quando uma plataforma fica offline repetidamente, os usuários podem perder a confiança mesmo que cada interrupção seja curta. Para provedores de serviço e plataformas empresariais, uptime estável faz parte da experiência geral do produto.
Outro motivo é o controle operacional. Sem planejamento de HA, equipes técnicas frequentemente dependem de solução de problemas de emergência depois que uma falha já afetou os usuários. Com redundância, verificações de saúde automatizadas, lógica de failover e procedimentos claros de incidentes, falhas se tornam eventos controlados em vez de crises inesperadas.
Um sistema de alta disponibilidade não presume que as falhas nunca acontecerão. Ele presume que as falhas acontecerão e prepara o serviço para continuar operando quando elas ocorrerem.
Funcionalidades Principais que Sustentam a Operação Confiável
Infraestrutura Redundante
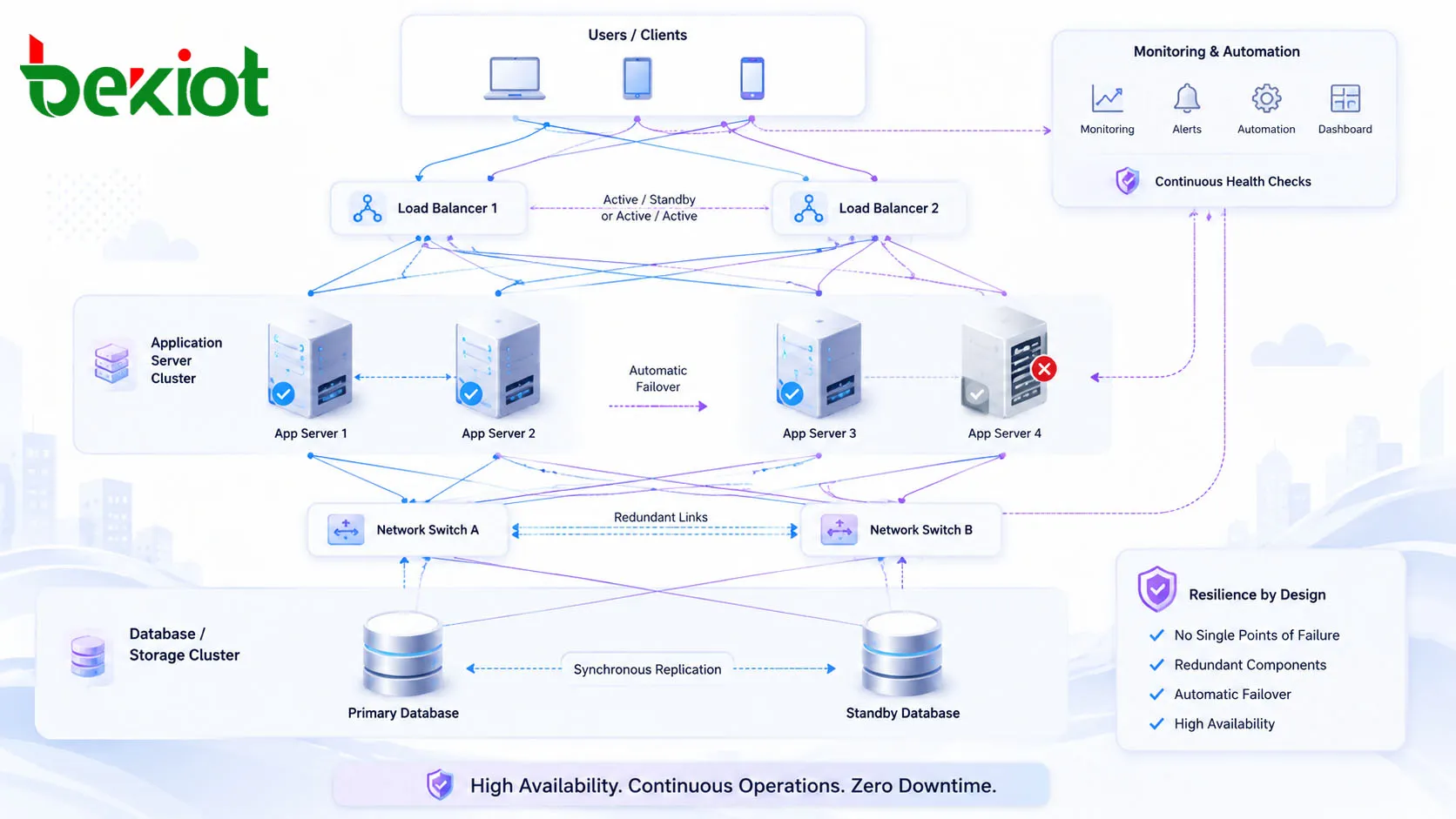
Redundância é a base da alta disponibilidade. Componentes importantes são duplicados para que outro componente possa continuar funcionando se o ativo falhar. A redundância pode incluir múltiplos servidores, nós de aplicação em cluster, armazenamento espelhado, bancos de dados replicados, fontes de alimentação duplas, roteadores de backup, switches redundantes, múltiplas conexões de internet e instâncias de serviço duplicadas em diferentes localizações.
A redundância eficaz deve cobrir o caminho real do serviço. Dois servidores de aplicação não oferecem proteção total se ambos dependem de um único banco de dados, um único array de armazenamento, um único firewall, um único circuito de energia ou um único provedor externo. O planejamento de HA deve revisar cada dependência que o serviço precisa para funcionar.
Failover Automático
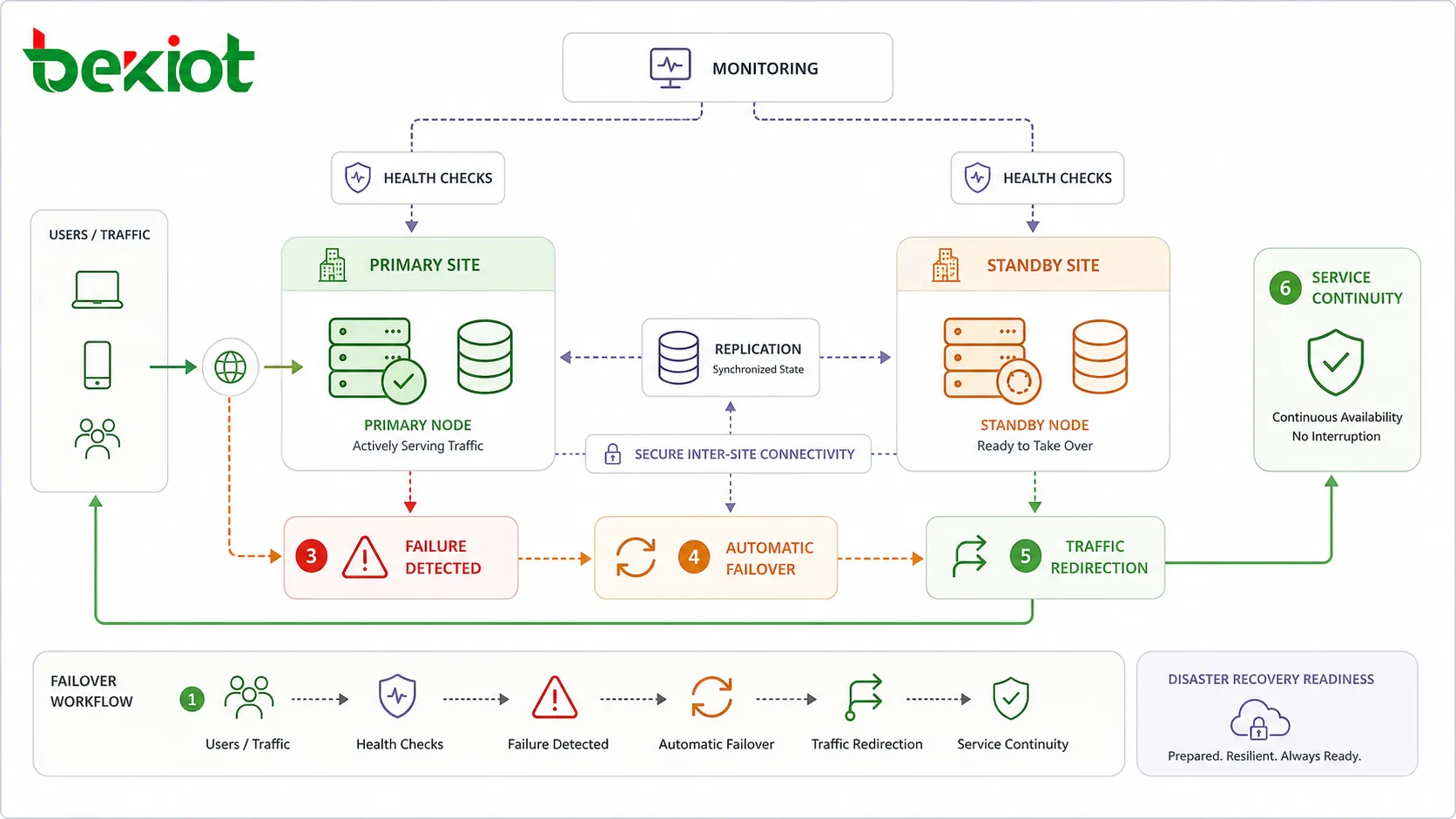
Failover é o processo de mover o serviço de um componente com falha para um componente saudável. Em muitos projetos de HA, esse processo acontece automaticamente. Por exemplo, um balanceador de carga pode remover um servidor não saudável da rotação, um banco de dados standby pode se tornar o banco de dados primário ou uma rota de rede de backup pode assumir quando o link principal é interrompido.
O failover automático reduz o tempo de recuperação porque não espera que um engenheiro diagnostique a falha manualmente. No entanto, a lógica de failover deve ser cuidadosamente projetada. Se as verificações de saúde forem muito simples, o sistema pode alternar desnecessariamente. Se as regras de failover forem muito lentas, os usuários podem experimentar um tempo de inatividade maior do que o esperado.
Monitoramento da Saúde do Serviço
O monitoramento permite que o sistema e a equipe de operações detectem condições anormais precocemente. Um monitoramento útil abrange saúde do servidor, uso de CPU e memória, espaço em disco, tempo de resposta do serviço, replicação de banco de dados, latência de rede, perda de pacotes, conclusão de chamadas, taxa de sucesso de transações, expiração de certificados, status de backup e eventos de segurança.
As verificações de saúde mais úteis estão conectadas ao comportamento real do serviço. Um dispositivo pode responder ao ping enquanto a aplicação está travada. Um servidor web pode estar em execução enquanto a conexão com o banco de dados está quebrada. Um servidor de comunicação pode estar online enquanto o roteamento de chamadas está falhando. O monitoramento deve confirmar se o serviço está realmente utilizável.
Distribuição de Carga
O balanceamento de carga distribui o tráfego entre vários servidores ou instâncias de serviço. Isso melhora o desempenho durante a operação normal e apoia a continuidade durante falhas. Se um nó ficar sobrecarregado ou indisponível, o tráfego pode ser deslocado para outros nós saudáveis.
O balanceamento de carga é amplamente utilizado para sites, APIs, aplicações em nuvem, plataformas de comunicação, serviços de autenticação e sistemas empresariais internos. Dependendo do projeto, ele pode suportar persistência de sessão, roteamento geográfico, roteamento baseado em saúde ou direcionamento de tráfego ciente da aplicação.
Replicação de Dados
Muitos sistemas não podem permanecer disponíveis a menos que os dados também estejam disponíveis. A replicação de dados mantém cópias de informações importantes em vários nós ou localizações. Isso permite que um servidor secundário, sistema de armazenamento ou data center continue o serviço se o ambiente primário falhar.
A replicação pode ser síncrona ou assíncrona. A replicação síncrona confirma uma gravação somente depois que os dados são gravados em mais de um local, o que pode melhorar a consistência, mas pode aumentar a latência. A replicação assíncrona geralmente é mais rápida, mas uma pequena quantidade de dados recentes pode estar em risco se ocorrer uma falha repentina. A escolha certa depende do equilíbrio necessário entre desempenho, consistência e perda de dados aceitável.
Manutenção Sem Desligamento Total
Um bom projeto de HA também ajuda durante a manutenção planejada. Os sistemas precisam de atualizações, patches de segurança, substituição de hardware, renovação de certificados, alterações de configuração e expansão de capacidade. Se a arquitetura suportar atualizações contínuas ou failover controlado, a manutenção pode ser concluída sem tirar todo o serviço do ar.
Isso é especialmente útil para serviços que operam 24 horas por dia. Em vez de esperar por longas janelas de manutenção, as equipes podem atualizar um nó de cada vez enquanto outros nós continuam lidando com o tráfego de produção.
Padrões Comuns de Arquitetura
Ativo-Standby
Em um design ativo-standby, um sistema lida com o tráfego de produção enquanto outro sistema permanece pronto para assumir. Este modelo é frequentemente usado para firewalls, bancos de dados, sistemas PBX, gateways, aplicações industriais e plataformas centrais de gerenciamento.
A vantagem da arquitetura ativo-standby é a simplicidade e o comportamento de failover previsível. A desvantagem é que os recursos standby podem não ser totalmente utilizados durante a operação normal. O sistema standby também deve ser testado regularmente para confirmar que está sincronizado e pronto.
Ativo-Ativo
Em um design ativo-ativo, vários sistemas lidam com o tráfego ao mesmo tempo. Se um nó falhar, os nós restantes continuam executando e absorvem a carga de trabalho. Este modelo pode melhorar tanto a disponibilidade quanto o desempenho porque a capacidade é usada continuamente.
A arquitetura ativo-ativo geralmente exige um design mais cuidadoso. As aplicações devem lidar com sessões distribuídas, consistência de dados, comportamento de roteamento e possíveis cenários de conflito. Se o software não for projetado para operação distribuída, a implantação ativo-ativo pode criar complexidade em vez de confiabilidade.
Serviços em Cluster
Um cluster é um grupo de nós que trabalham juntos como um único serviço. Sistemas em cluster podem proteger aplicações, bancos de dados, máquinas virtuais, plataformas de armazenamento, cargas de trabalho de contêineres e serviços de comunicação. Os gerenciadores de cluster monitoram a saúde dos nós e coordenam o failover ou a redistribuição da carga de trabalho.
O clustering estável requer comunicação adequada de heartbeat, regras de quórum, mecanismos de fencing e separação de rede. Esses controles ajudam a evitar situações de split-brain, onde dois nós acreditam incorretamente que são ambos o sistema primário.
Implantação Multisite
Para requisitos de resiliência mais altos, os sistemas podem ser implantados em vários sites, data centers, zonas de disponibilidade de nuvem ou regiões. Se um site ficar indisponível devido a falha de energia, interrupção de rede, dano físico ou um grande incidente de infraestrutura, outro site pode continuar o serviço.
O design multisite é mais complexo do que a redundância local. Ele requer direcionamento de tráfego, conectividade segura, planejamento de replicação, configuração consistente, coordenação operacional e testes regulares de recuperação de desastres. Também exige regras claras para quando alternar o tráfego entre os sites.
Métricas Usadas para Medir a Continuidade do Serviço
Porcentagem de Uptime
A porcentagem de uptime mede por quanto tempo um sistema permanece operacional durante um período específico. É frequentemente usada em acordos de nível de serviço e metas internas de confiabilidade. Metas de uptime mais altas exigem arquitetura mais forte, recuperação mais rápida, melhor monitoramento e operações mais disciplinadas.
No entanto, o uptime deve ser medido da perspectiva do usuário. Um sistema que está tecnicamente em execução, mas incapaz de processar solicitações, completar chamadas, acessar dados ou responder dentro de limites de tempo aceitáveis não deve ser considerado totalmente disponível.
Objetivo de Tempo de Recuperação (RTO)
O Objetivo de Tempo de Recuperação (Recovery Time Objective - RTO) define a rapidez com que o serviço deve ser restaurado após uma interrupção. Um RTO curto geralmente requer failover automatizado, capacidade standby pronta para uso, procedimentos testados e detecção rápida.
O RTO deve corresponder ao impacto no negócio. Nem todo sistema precisa de recuperação imediata. Alguns sistemas internos podem tolerar um período de recuperação mais longo, enquanto serviços de missão crítica podem exigir operação quase contínua.
Objetivo de Ponto de Recuperação (RPO)
O Objetivo de Ponto de Recuperação (Recovery Point Objective - RPO) define quanta perda de dados é aceitável após uma falha. Um RPO baixo requer replicação frequente ou contínua. Um RPO mais alto pode permitir a recuperação a partir de backups programados.
O RPO é importante para registros de transações, logs de chamadas, históricos de eventos, dados de produção, informações de usuários, trilhas de auditoria e relatórios operacionais. Se a perda de dados for inaceitável, o design de replicação e backup deve ser mais rigoroso.
Tempo Médio de Reparo (MTTR)
O Tempo Médio de Reparo (Mean Time to Repair - MTTR) mede quanto tempo leva para restaurar o serviço normal após uma falha. A alta disponibilidade melhora quando o MTTR é reduzido. Melhor automação, documentação mais clara, operadores treinados, recursos sobressalentes e planos de recuperação testados ajudam a encurtar o tempo de reparo.
Reduzir o tempo de reparo é frequentemente mais realista do que tentar prevenir todas as falhas possíveis. Mesmo sistemas bem projetados acabarão falhando, mas uma organização bem preparada pode se recuperar mais rápido e com menos impacto para o usuário.
Aplicações em Ambientes do Mundo Real
Plataformas de Nuvem e Aplicações SaaS
Serviços de nuvem e plataformas SaaS usam o design de HA para manter as aplicações acessíveis a usuários em diferentes locais e fusos horários. Técnicas comuns incluem grupos de auto scaling, balanceadores de carga, bancos de dados replicados, armazenamento de objetos distribuído, verificações de saúde, regiões de backup e estratégias de implantação contínua.
Para serviços baseados em assinatura, a disponibilidade afeta diretamente a retenção de clientes e a reputação da marca. Os usuários podem não conhecer os detalhes da arquitetura, mas percebem rapidamente respostas lentas, falhas de login, dados ausentes ou interrupções de serviço.
Sistemas de Comunicação Empresarial
Sistemas de voz, vídeo, mensagens, paging e despacho frequentemente exigem alta disponibilidade porque a comunicação pode ser necessária tanto durante o trabalho rotineiro quanto em incidentes urgentes. O planejamento de HA pode incluir servidores de chamadas redundantes, trunks SIP de backup, gateways secundários, caminhos de rede resilientes, sistemas de filial com capacidade de sobrevivência e energia de backup.
A disponibilidade da comunicação deve ser testada de ponta a ponta. Não basta que um servidor esteja online se os telefones não conseguem se registrar, as chamadas não podem ser roteadas, o áudio não atravessa a rede ou os números de emergência não podem ser alcançados.
Operações Industriais e de Energia
Instalações industriais, concessionárias, operações de mineração, portos, centros de transporte e instalações de energia frequentemente dependem de monitoramento e comunicação contínuos. Nesses ambientes, a alta disponibilidade pode incluir anéis de fibra redundantes, links sem fio de backup, servidores de controle duplos, capacidade de sobrevivência local, equipamentos robustecidos e caminhos de emergência isolados.
O design deve considerar tanto falhas de TI quanto condições físicas. Ambientes hostis, interferência eletromagnética, locais remotos, instabilidade de energia e acesso limitado à manutenção podem todos afetar a disponibilidade.
Saúde e Serviços de Emergência
Hospitais, centros de resposta a emergências, agências de segurança pública e salas de comando dependem de sistemas confiáveis para coordenação. A alta disponibilidade pode suportar acesso a informações de pacientes, notificação de alarmes, comunicação de emergência, fluxos de trabalho de despacho, controle de acesso, monitoramento por vídeo e colaboração interna.
Nesses ambientes, o tempo de inatividade não é apenas uma questão técnica. Ele pode afetar a velocidade de resposta, a segurança, a tomada de decisões e a continuidade do cuidado. Energia de backup, redes redundantes, procedimentos claros de escalonamento e exercícios regulares são especialmente importantes.
Finanças, Varejo e Transações Online
Bancos, processadores de pagamento, plataformas de negociação e lojas online exigem sistemas confiáveis para proteger transações e acesso do cliente. Mesmo interrupções curtas podem causar falhas de pagamento, vendas perdidas, atrasos em pedidos, problemas de liquidação ou reclamações de clientes.
Esses sistemas frequentemente combinam planejamento de disponibilidade com segurança forte, registro de auditoria, monitoramento de fraudes, criptografia e controles de conformidade. A continuidade do serviço deve ser projetada juntamente com a integridade dos dados e o gerenciamento de riscos.
Considerações de Design Antes da Implantação
Mapeie a Cadeia Completa de Dependências
O primeiro passo é entender como o serviço realmente funciona. As equipes devem mapear aplicações, bancos de dados, redes, armazenamento, autenticação, DNS, firewalls, serviços de terceiros, certificados, ferramentas de monitoramento e responsabilidades operacionais. Isso ajuda a identificar dependências ocultas que podem se tornar pontos únicos de falha.
Um mapa de serviço também ajuda as equipes a decidir quais componentes precisam de redundância e quais riscos podem ser aceitos. Nem toda dependência requer o mesmo nível de proteção, mas toda dependência crítica deve estar visível.
Defina Metas de Recuperação Realistas
As metas de disponibilidade devem ser baseadas nas necessidades do negócio, não na linguagem de marketing. Uma plataforma de missão crítica pode justificar redundância cara e replicação quase em tempo real. Uma ferramenta de relatórios de baixa prioridade pode precisar apenas de backup programado e recuperação manual.
Metas claras de RTO e RPO ajudam as equipes a escolher a arquitetura certa. Elas também ajudam a evitar o superdimensionamento de sistemas que não precisam de proteção avançada ou a subproteção de serviços essenciais para as operações.
Teste o Failover Sob Condições Controladas
Um plano de failover só é valioso se funcionar quando necessário. Testes controlados verificam se o monitoramento detecta a falha, se os recursos standby são ativados corretamente, se o tráfego é redirecionado como esperado, se os dados permanecem consistentes e se os usuários podem continuar trabalhando.
Os testes devem incluir failover planejado, simulação de falha de nó, isolamento de rede, restauração de backup, recuperação de banco de dados e procedimentos de rollback. Os resultados devem ser documentados para que as melhorias futuras se baseiem em evidências, não em suposições.
Controle as Alterações de Configuração
Muitas interrupções são causadas por erro humano, não por falha de hardware. Regras de firewall incorretas, certificados expirados, atualizações incompatíveis, alterações de roteamento erradas, erros de permissão de banco de dados e configuração inconsistente podem interromper o serviço.
O controle de mudanças, gerenciamento de versão, fluxos de trabalho de aprovação, ambientes de teste, planos de rollback e backups de configuração reduzem esse risco. Em ambientes de HA, tanto o sistema primário quanto o standby devem permanecer alinhados.
Desafios e Limitações
A alta disponibilidade reduz o tempo de inatividade, mas não torna um sistema à prova de falhas. Bugs de software, ransomware, erros de configuração, corrupção de dados, interrupções de dependências, desastres regionais e erros do operador ainda podem interromper o serviço. HA deve trabalhar em conjunto com backup, segurança cibernética, recuperação de desastres, observabilidade e resposta a incidentes.
O custo é outro desafio. A arquitetura redundante pode exigir mais servidores, dispositivos de rede, recursos de nuvem, licenças, sistemas de monitoramento, capacidade de armazenamento e expertise operacional. Quanto maior a meta de disponibilidade, mais importante se torna justificar o investimento.
A complexidade também pode se tornar um risco. Um design de HA complicado que a equipe de operações não entende pode falhar durante um incidente. A alta disponibilidade prática deve ser documentada, testável e gerenciável pelas pessoas responsáveis por executá-la.
A melhor estratégia de disponibilidade nem sempre é a mais complexa. É aquela que protege os serviços mais importantes, pode ser testada regularmente e pode ser operada com confiança durante incidentes reais.
Melhores Práticas para Confiabilidade de Longo Prazo
Comece com a classificação de serviços. Identifique quais sistemas são de missão crítica, quais são importantes para o negócio e quais podem tolerar uma recuperação mais longa. Isso permite que os recursos sejam focados onde o tempo de inatividade tem o maior impacto.
Use monitoramento que reflita os resultados reais do usuário. Em vez de verificar apenas o status do dispositivo, monitore se os usuários podem fazer login, fazer chamadas, acessar registros, enviar formulários, receber alertas ou concluir transações. Isso fornece uma visão mais precisa da saúde do serviço.
Mantenha a documentação atualizada. Diagramas de arquitetura, etapas de failover, listas de contatos, caminhos de escalonamento, locais de backup, manuseio de credenciais e procedimentos de rollback devem ser atualizados após cada mudança importante. Durante um incidente, documentação desatualizada pode atrasar a recuperação.
Revise a arquitetura regularmente. O volume de tráfego, versões de software, requisitos de segurança, dependências de terceiros e prioridades de negócios mudam com o tempo. Um sistema que atendia às metas de disponibilidade no passado pode precisar ser redesenhado à medida que o uso e o risco aumentam.
Conclusão
Alta disponibilidade é um método prático para manter serviços importantes acessíveis quando ocorrem falhas. Ela combina infraestrutura redundante, failover automático, monitoramento de saúde, balanceamento de carga, replicação de dados, planejamento de manutenção e procedimentos de recuperação testados. Seu valor é especialmente claro quando o tempo de inatividade afeta a segurança, a receita, a comunicação, a produção, a conformidade ou a confiança do cliente.
Uma estratégia de HA bem-sucedida não se resume a adicionar mais equipamentos. Ela requer entender a cadeia completa de serviço, identificar pontos únicos de falha, definir metas de recuperação realistas, testar o failover e equilibrar confiabilidade com custo e complexidade. Quando projetada corretamente, a alta disponibilidade ajuda as organizações a construir sistemas que permanecem confiáveis sob condições do mundo real.
Perguntas Frequentes
Um sistema de alta disponibilidade ainda pode perder dados?
Sim. Disponibilidade e proteção de dados são relacionadas, mas não idênticas. Se a replicação estiver atrasada ou as políticas de backup forem fracas, um serviço pode se recuperar rapidamente enquanto ainda perde dados recentes. O planejamento de RPO é necessário para controlar esse risco.
Alta disponibilidade é o mesmo que tolerância a falhas?
Não. Tolerância a falhas geralmente significa que um sistema continua operando com pouca ou nenhuma interrupção mesmo quando um componente falha. Alta disponibilidade foca em reduzir o tempo de inatividade, mas um breve atraso de failover ainda pode ocorrer dependendo da arquitetura.
Pequenas empresas devem usar alta disponibilidade?
Sim, mas o design deve corresponder ao impacto no negócio. Uma empresa pequena pode não precisar de arquitetura multirregião, mas ainda pode se beneficiar de links de internet redundantes, backups confiáveis, failover baseado em nuvem, serviços monitorados e energia de backup para sistemas críticos.
A alta disponibilidade pode proteger contra ataques cibernéticos?
Apenas parcialmente. HA pode ajudar a manter o serviço se um nó for isolado ou restaurado, mas não pode substituir os controles de segurança cibernética. Ransomware, roubo de credenciais, ataques DDoS e adulteração de dados exigem monitoramento de segurança, controle de acesso, aplicação de patches, isolamento de backup e resposta a incidentes.
Toda aplicação suporta implantação ativo-ativo?
Não. Algumas aplicações não são projetadas para sessões distribuídas, estado compartilhado ou gravações em múltiplos nós. Antes de escolher a arquitetura ativo-ativo, as equipes devem confirmar que o software, banco de dados, modelo de licenciamento e design de rede podem suportá-la com segurança.