HTTP, ou Protocolo de Transferência de Hipertexto, é o protocolo da camada de aplicação usado para transferir páginas web, dados de API, arquivos, formulários, imagens, scripts e outros recursos entre clientes e servidores. Ele é a base da World Wide Web e um dos protocolos de comunicação mais usados nos sistemas modernos da Internet.
Quando um usuário abre um site, clica em um link, envia um formulário, carrega uma imagem ou chama uma API, o HTTP define como o cliente solicita um recurso e como o servidor responde. O protocolo em si não decide como uma página aparece nem como uma aplicação se comporta. Sua função principal é oferecer um método de comunicação estruturado entre os dois lados.
Uma conversa de solicitação e resposta
O princípio básico é simples: um cliente envia uma solicitação e um servidor retorna uma resposta. O cliente costuma ser um navegador web, aplicativo móvel, aplicativo de desktop, ferramenta de API, rastreador ou dispositivo embarcado. O servidor é o sistema que hospeda o recurso ou serviço solicitado.
Por exemplo, quando um navegador visita um site, ele envia uma solicitação pedindo uma página específica. O servidor recebe a solicitação, verifica qual recurso está sendo solicitado, processa as regras associadas e retorna uma resposta com conteúdo, informações de status e metadados.
Esse modelo é chamado de comunicação solicitação-resposta. O cliente inicia a troca e o servidor responde. Cada troca é estruturada para que os dois lados entendam o que está sendo solicitado, como deve ser tratado e qual resultado foi retornado.

Antes do primeiro byte se mover
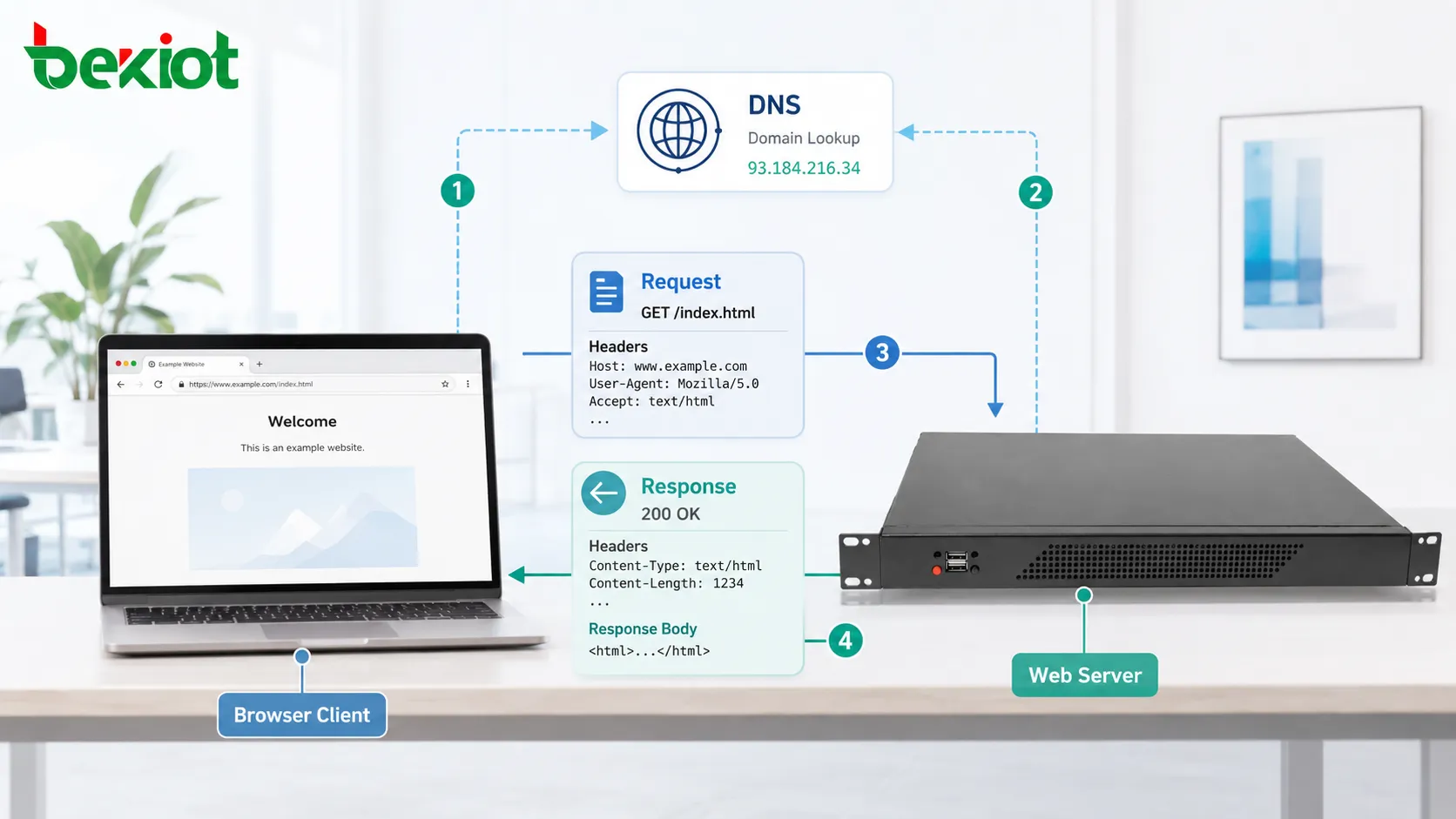
Antes que uma solicitação HTTP alcance o servidor, o cliente precisa saber para onde enviá-la. Quando um usuário digita um nome de domínio, o navegador normalmente realiza primeiro uma resolução DNS. O DNS traduz o nome de domínio legível por pessoas em um endereço IP.
Depois disso, o cliente estabelece uma conexão de rede com o servidor. Com HTTP tradicional sobre TCP, isso significa abrir uma conexão TCP. Com HTTPS, também é realizado um handshake TLS para que a comunicação possa ser criptografada e autenticada.
Somente depois dessas etapas a mensagem HTTP real pode ser trocada. Isso significa que carregar uma página web não depende apenas da mensagem do protocolo. Também depende de DNS, conexão de transporte, criptografia, disponibilidade do servidor, roteamento e desempenho da rede.
Anatomia de uma solicitação do cliente
Uma solicitação HTTP normalmente contém um método, caminho de destino, versão, cabeçalhos e, às vezes, um corpo de mensagem. O método explica a ação pretendida. O caminho identifica o recurso. Os cabeçalhos fornecem informações extras. O corpo carrega os dados enviados quando necessário.
Uma solicitação simples pode pedir uma página inicial. Uma solicitação mais complexa pode enviar credenciais de login, fazer upload de um arquivo, enviar dados JSON para uma API ou solicitar um recurso em cache somente se ele tiver mudado.
Métodos comuns de solicitação incluem GET, POST, PUT, PATCH, DELETE, HEAD e OPTIONS. Cada método tem um significado diferente e deve ser usado de acordo com o objetivo da operação.
GET é comumente usado para recuperar dados. POST costuma ser usado para enviar dados. PUT e PATCH são usados para atualizar recursos. DELETE é usado para solicitar remoção. HEAD pede os cabeçalhos da resposta sem o corpo completo. OPTIONS verifica opções de comunicação compatíveis.
Como o servidor interpreta a mensagem
Depois de receber a solicitação, o servidor lê o método, caminho, cabeçalhos, corpo, cookies, dados de autenticação e regras de roteamento. Em seguida, decide o que deve acontecer.
Se a solicitação for para um arquivo estático, o servidor pode retornar o arquivo diretamente. Se for para uma página dinâmica ou endpoint de API, o servidor pode chamar código da aplicação, consultar um banco de dados, verificar permissões do usuário, executar lógica de negócio ou comunicar-se com outro serviço.
O servidor também pode aplicar regras de segurança antes de retornar qualquer coisa. Ele pode verificar se a solicitação está autenticada, se o usuário tem permissão, se a solicitação está malformada, se a origem está bloqueada ou se limites de taxa foram excedidos.
O resultado final é empacotado em uma resposta HTTP.
Estrutura e significado da resposta
Uma resposta HTTP normalmente contém um código de status, cabeçalhos e um corpo opcional. O código de status informa ao cliente se a solicitação teve sucesso, falhou, foi redirecionada ou precisa de outra ação.
Os cabeçalhos descrevem a resposta. Eles podem incluir tipo de conteúdo, comprimento do conteúdo, regras de cache, cookies, informações do servidor, método de compressão, política de segurança e local de redirecionamento.
O corpo carrega o conteúdo real retornado. Ele pode ser HTML, JSON, XML, dados de imagem, segmentos de vídeo, arquivos de texto, folhas de estilo, scripts ou downloads binários.
Um navegador usa o corpo e os cabeçalhos da resposta para decidir o que exibir, o que armazenar em cache, o que executar, o que baixar e se novas solicitações são necessárias.
Códigos de status como sinais de trânsito
Os códigos de status ajudam os clientes a entender rapidamente o resultado. Eles são agrupados por categoria.
| Faixa de códigos | Significado geral | Exemplo de uso |
|---|---|---|
| 100-199 | Resposta informativa | Continuar processamento ou aviso em nível de protocolo |
| 200-299 | Resposta bem-sucedida | Página carregada, API retornou dados, arquivo entregue |
| 300-399 | Redirecionamento | Recurso movido ou cliente deve solicitar outra URL |
| 400-499 | Erro do lado do cliente | Solicitação incorreta, acesso não autorizado, recurso ausente |
| 500-599 | Erro do lado do servidor | Falha de aplicação, erro de gateway, sobrecarga do servidor |
Uma resposta 200 geralmente significa que a solicitação foi bem-sucedida. Uma resposta 301 ou 302 significa que o cliente deve ir para outro local. Uma resposta 404 significa que o recurso solicitado não foi encontrado. Uma resposta 500 significa que o servidor encontrou um problema interno.
Os códigos de status não servem apenas para navegadores. Clientes de API, sistemas de monitoramento, rastreadores, proxies e balanceadores de carga também os usam para tomar decisões.
Cabeçalhos carregam o contexto
Cabeçalhos são campos chave-valor que fornecem contexto para a troca. Eles ajudam os dois lados a descrever formato de dados, preferência de idioma, compressão, autenticação, comportamento de cache, cookies, comportamento de conexão e requisitos de segurança.
Por exemplo, o cabeçalho Accept pode informar ao servidor quais tipos de conteúdo o cliente prefere. Content-Type informa ao receptor qual formato o corpo usa. Authorization pode carregar credenciais ou tokens. Cache-Control define o comportamento de cache.
Os cabeçalhos tornam o protocolo flexível. O mesmo modelo solicitação-resposta pode suportar sites, APIs, downloads de arquivos, segmentos de streaming, fluxos de autenticação e integrações de serviços, porque os cabeçalhos adicionam instruções sem alterar a estrutura básica da mensagem.
Design sem estado e tratamento de sessão
O HTTP é frequentemente descrito como sem estado. Isso significa que cada solicitação é independente por padrão. O servidor não lembra automaticamente solicitações anteriores como parte do modelo básico do protocolo.
No entanto, a maioria dos sites e aplicações reais precisa de comportamento de sessão. Usuários fazem login, adicionam itens ao carrinho, alteram configurações e continuam fluxos de trabalho por muitas solicitações. Para isso, os sistemas usam cookies, IDs de sessão, tokens, armazenamento local, sessões no servidor e cabeçalhos de autenticação.
O protocolo continua baseado em solicitações, mas as aplicações constroem continuidade sobre ele. Por isso um site pode lembrar um usuário, embora a troca subjacente ainda seja formada por solicitações e respostas separadas.
Identificação de recursos com URLs
Uma URL informa ao cliente onde um recurso está localizado e como solicitá-lo. Normalmente inclui esquema, host, caminho, string de consulta e, às vezes, porta ou fragmento.
O esquema pode ser http ou https. O host identifica o domínio. O caminho aponta para um recurso ou rota específica. A string de consulta carrega parâmetros adicionais. O fragmento geralmente é tratado no lado do cliente e não precisa ser enviado ao servidor da mesma forma que o caminho principal da solicitação.
URLs tornam os recursos web endereçáveis. Elas permitem que navegadores, APIs, mecanismos de busca, aplicações e usuários se refiram a recursos em um formato consistente.
O que acontece quando uma página web carrega
Um único carregamento de página pode envolver muitas trocas HTTP. A primeira solicitação pode recuperar o documento HTML principal. Depois de ler esse documento, o navegador descobre recursos adicionais, como arquivos CSS, JavaScript, imagens, fontes, ícones, scripts de análise, chamadas API e arquivos de mídia.
Cada recurso pode exigir outra solicitação. Alguns recursos podem vir do mesmo servidor, enquanto outros podem vir de CDNs, serviços de terceiros, sistemas de publicidade, provedores de mapas ou gateways de API.
O navegador então combina os recursos recebidos, constrói a estrutura da página, aplica estilos, executa scripts e renderiza a interface visual final. É por isso que uma página web pode exigir dezenas ou até centenas de trocas de protocolo por trás de uma única ação visível.
Cache e melhoria de desempenho
O cache permite que clientes, navegadores, proxies, CDNs e servidores reutilizem recursos baixados anteriormente quando apropriado. Isso reduz transferências repetidas de dados, diminui a latência, economiza largura de banda e melhora a experiência do usuário.
O comportamento de cache é controlado por cabeçalhos como Cache-Control, ETag, Last-Modified e Expires. Esses cabeçalhos ajudam a determinar se um recurso pode ser reutilizado, deve ser revalidado ou precisa ser baixado novamente.
Para arquivos estáticos como imagens, scripts e folhas de estilo, o cache pode reduzir bastante o tempo de carregamento. Para dados dinâmicos, o cache deve ser usado com cuidado, porque conteúdo desatualizado pode causar resultados incorretos.
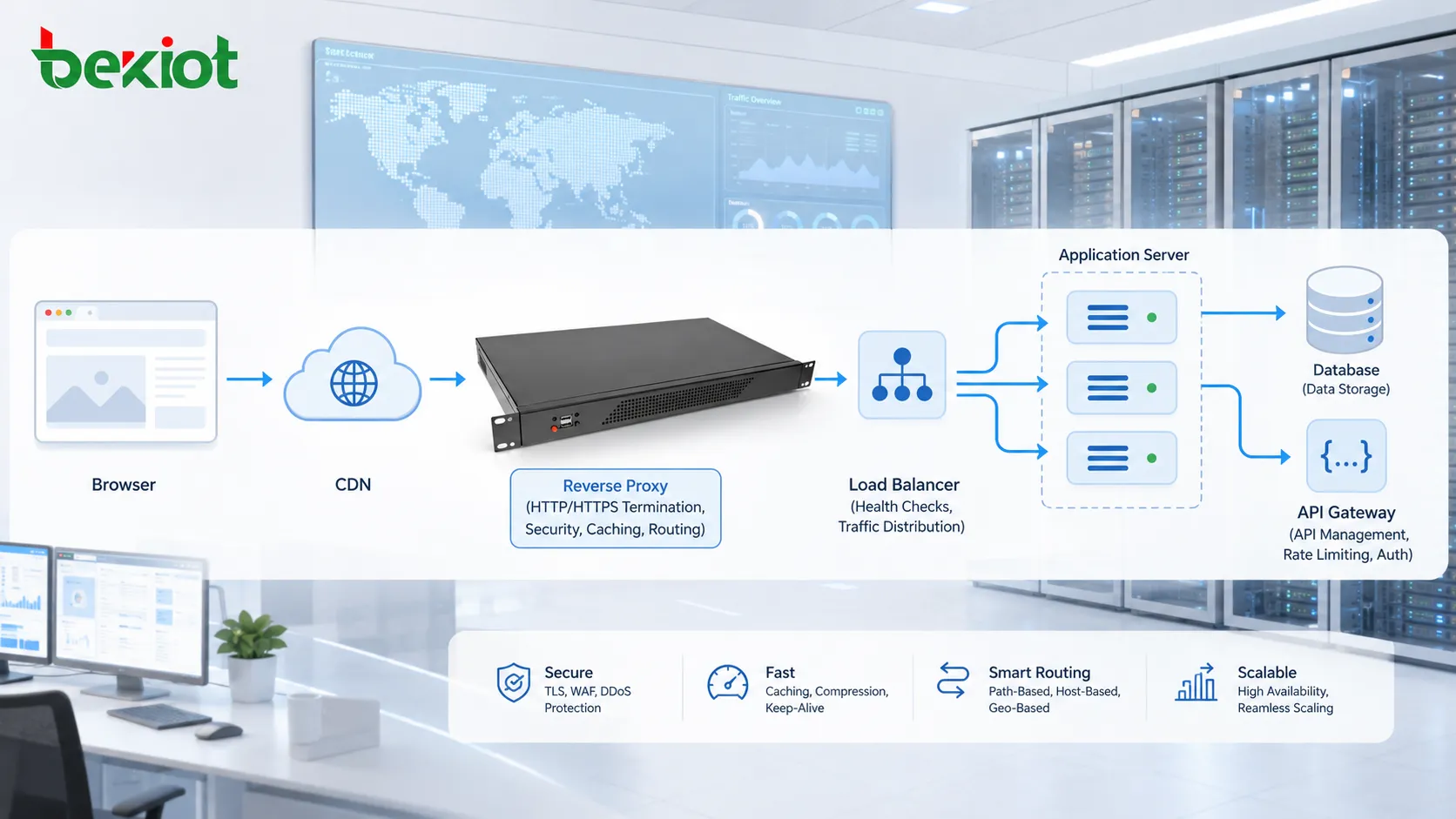
Papel de proxies, gateways e CDNs
O tráfego HTTP nem sempre viaja diretamente do navegador para o servidor de origem. Ele pode passar por proxies reversos, proxies diretos, gateways de API, balanceadores de carga, firewalls, nós de borda CDN ou sistemas de inspeção de segurança.
Um proxy reverso pode receber solicitações em nome de servidores backend. Um balanceador de carga pode distribuir tráfego entre vários servidores de aplicação. Uma CDN pode armazenar conteúdo mais perto dos usuários. Um gateway de API pode verificar tokens, limitar taxas de solicitação, transformar cabeçalhos ou rotear tráfego para microsserviços.
Esses sistemas intermediários melhoram escalabilidade, segurança, desempenho e capacidade de gerenciamento. Eles também tornam a solução de problemas mais complexa, pois erros podem ocorrer em diferentes camadas.
HTTPS e comunicação segura
HTTPS é HTTP transportado sobre criptografia TLS. Ele protege dados em trânsito criptografando a comunicação entre cliente e servidor. Também ajuda a verificar a identidade do servidor por meio de certificados digitais.
Sem criptografia, informações sensíveis como senhas, tokens, dados pessoais e cookies de sessão poderiam ser expostas a atacantes na rede. O HTTPS reduz esse risco e se tornou o padrão normal para sites e APIs modernos.
A comunicação segura também depende de configuração correta de certificados, versões fortes de protocolo, cookies seguros, redirecionamentos adequados e configurações seguras de servidor. O HTTPS é essencial, mas deve ser configurado corretamente.
Evolução das versões do protocolo
O HTTP evoluiu para melhorar desempenho e eficiência. Versões anteriores usavam tratamento de solicitações mais simples. Versões posteriores introduziram conexões persistentes, multiplexação, compressão de cabeçalhos, conceitos de server push e comportamento de transporte aprimorado.
HTTP/1.1 melhorou a reutilização de conexões e foi amplamente implantado. HTTP/2 introduziu multiplexação, permitindo que várias solicitações e respostas compartilhem uma conexão com mais eficiência. HTTP/3 usa QUIC sobre UDP para melhorar o estabelecimento de conexão e reduzir alguns problemas de latência em certas condições de rede.
O princípio de funcionamento continua sendo a comunicação solicitação-resposta, mas os mecanismos de transporte e desempenho ficaram mais avançados.
APIs e comunicação máquina a máquina
HTTP não é usado apenas por navegadores. Ele também é o estilo de protocolo dominante para muitas APIs. Aplicativos móveis, aplicações web, plataformas IoT, serviços em nuvem, sistemas de pagamento, ferramentas de monitoramento e sistemas empresariais frequentemente trocam dados JSON ou XML por HTTP.
Na comunicação de API, o corpo da resposta pode não ser uma página HTML. Pode ser dados estruturados para outro programa processar. Códigos de status, cabeçalhos, tokens de autenticação e métodos de solicitação tornam-se especialmente importantes para integração previsível.
Por isso, desenvolvedores precisam entender tanto o modelo básico de funcionamento quanto as convenções práticas usadas no design de APIs.
Problemas comuns e suas causas
Uma página lenta pode ser causada por atraso de DNS, arquivos grandes, cache ruim, sobrecarga do servidor, latência de banco de dados, congestionamento de rede, solicitações demais ou scripts ineficientes.
Um erro 404 pode indicar arquivo ausente, URL incorreta, rota excluída, regra de reescrita incorreta ou link quebrado. Um erro 500 pode apontar para falha de código no servidor, problema de banco de dados, problema de permissão ou serviço backend mal configurado.
Falhas de autenticação podem envolver tokens expirados, cookies ausentes, credenciais incorretas, configurações de origem cruzada bloqueadas ou tratamento incorreto de cabeçalhos.
Entender o caminho solicitação-resposta ajuda a localizar onde o problema ocorre.
Método prático de solução de problemas
Comece verificando a URL e o método da solicitação. Depois inspecione o código de status. Em seguida, revise cabeçalhos de solicitação, cabeçalhos de resposta, cookies e corpo da resposta. As ferramentas de desenvolvedor do navegador são úteis nesse processo.
Para problemas do lado do servidor, verifique logs de acesso, logs de erro, logs da aplicação, logs do proxy reverso e status de serviços backend. Em sistemas distribuídos, IDs de rastreamento e IDs de solicitação ajudam a acompanhar uma solicitação por vários serviços.
Para problemas de desempenho, verifique tempo de DNS, tempo de conexão, tempo de TLS, tempo de resposta do servidor, tempo de download do conteúdo, comportamento de cache e tamanho dos recursos. Esses detalhes mostram se o problema está relacionado à rede, ao servidor ou ao frontend.
Por que o modelo continua importante
O princípio de funcionamento do HTTP continua importante porque quase todo serviço digital moderno depende dele. Sites, APIs, aplicativos móveis, painéis em nuvem, plataformas de gestão, sistemas de pagamento, serviços de login, sistemas de monitoramento e plataformas IoT usam a mesma ideia básica: solicitar, processar e responder.
Sua força vem da simplicidade, extensibilidade, legibilidade e ampla compatibilidade. Ele pode transportar muitos tipos de conteúdo e suportar muitos tipos de aplicações mantendo uma estrutura de comunicação consistente.
Ao mesmo tempo, um bom design exige atenção a segurança, cache, cabeçalhos, códigos de status, tratamento de erros, compatibilidade de versões e arquitetura de rede.
Resumo
O HTTP funciona permitindo que um cliente envie uma solicitação estruturada a um servidor e receba uma resposta estruturada. Em torno desse modelo simples, sistemas web modernos adicionam DNS, TLS, cache, proxies, CDNs, APIs, autenticação, otimização de desempenho e controles de segurança.
Perguntas frequentes
HTTP é o mesmo que HTTPS?
Não. HTTP define o modelo de troca de mensagens, enquanto HTTPS adiciona criptografia TLS e verificação de identidade baseada em certificados para proteger a comunicação em trânsito.
Por que uma página web dispara muitas solicitações?
Uma página geralmente depende de arquivos separados, como imagens, scripts, folhas de estilo, fontes, chamadas API e recursos de mídia. O navegador solicita esses recursos depois de ler o documento principal.
HTTP pode ser usado sem navegador?
Sim. Aplicativos móveis, servidores, ferramentas de linha de comando, dispositivos IoT, sistemas de monitoramento e APIs podem usar HTTP sem um navegador web tradicional.
Por que algumas chamadas API retornam dados em vez de páginas web?
APIs geralmente retornam dados estruturados, como JSON ou XML. O programa receptor processa os dados em vez de exibi-los como página web.
O que deve ser verificado primeiro quando uma solicitação HTTP falha?
Verifique a URL, o método de solicitação, o código de status, os cabeçalhos, o estado de autenticação, a conexão de rede, os logs do servidor e se algum proxy ou gateway está alterando a solicitação.