

Imagine um site remoto perdendo sua conexão com a plataforma central enquanto os operadores ainda precisam ligar uns para os outros, alcançar contatos de emergência e manter a comunicação essencial em operação.
É nesse ponto que a sobrevivência local se torna valiosa. Ela não é projetada para condições ideais de rede, mas para o momento em que o caminho principal é interrompido, o link de longa distância fica instável, o servidor central não responde ou o serviço em nuvem não pode ser acessado pelo site.
Manter a comunicação essencial ativa durante o isolamento da rede
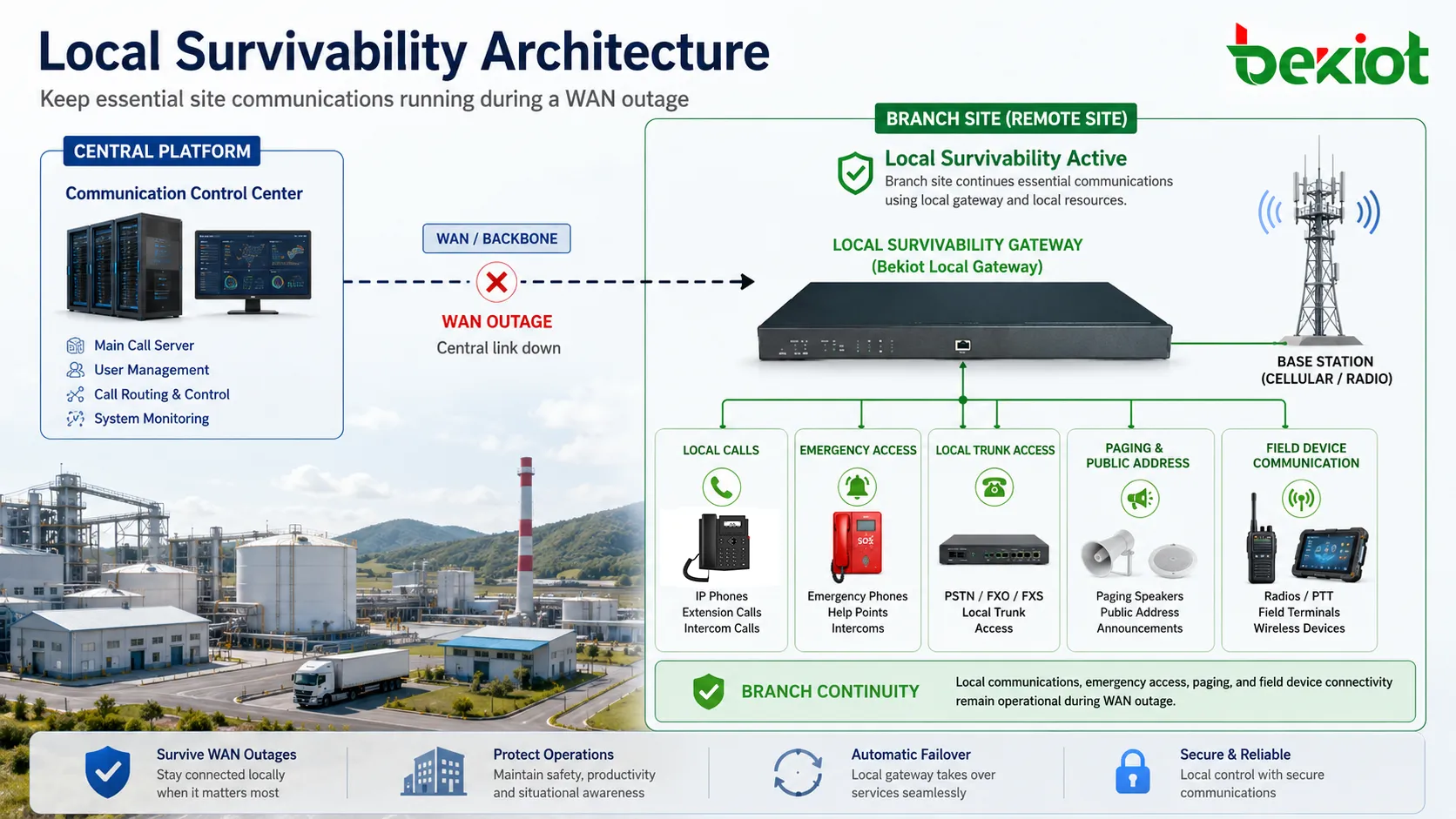
A sobrevivência local é a capacidade de uma filial, estação de campo, instalação industrial ou nó remoto de comunicação continuar executando serviços essenciais mesmo quando a conexão com o sistema central é interrompida. Em redes de comunicação, isso normalmente significa que usuários locais ainda podem ligar entre si, acessar números de emergência predefinidos, usar troncos locais ou manter serviços críticos de voz sem esperar a recuperação da plataforma central.
A vantagem prática é a continuidade. Muitos sistemas distribuídos dependem de servidores centrais para registro, roteamento, controle de políticas, gravação ou gestão de usuários. Esse modelo centralizado é eficiente durante a operação normal, mas também cria dependência. Se o link WAN falhar, os dispositivos do site remoto podem perder acesso ao servidor principal de chamadas, PBX em nuvem, plataforma de despacho ou centro de controle de comunicação. Sem sobrevivência, o site pode ficar operacionalmente isolado.
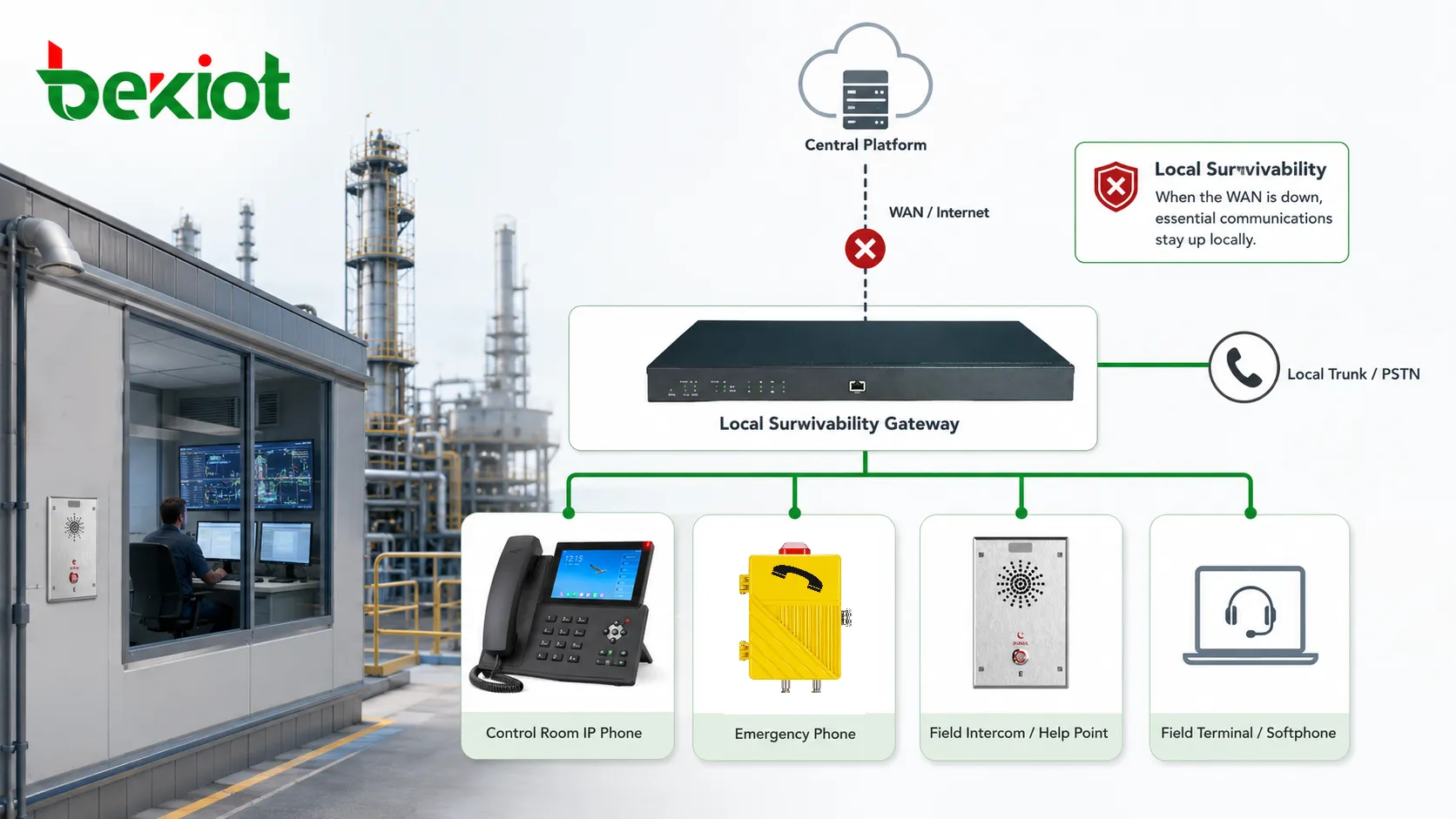
Com a sobrevivência local, um gateway, servidor, controlador ou nó de serviço incorporado pode assumir temporariamente funções selecionadas de comunicação. Ele não substitui necessariamente a plataforma central por completo. Em vez disso, preserva os serviços mais importantes para a operação local: chamadas internas, comunicação de emergência, roteamento local, troncos de contingência, fallback de registro de dispositivos e, em alguns casos, funções limitadas de despacho ou anúncios.
Essa capacidade é especialmente importante em plantas industriais, estações de transporte, instalações de energia, campus, parques logísticos, minas, túneis, aeroportos e sites de serviço público. Esses ambientes não podem simplesmente parar a comunicação porque um link de backbone caiu. A sobrevivência local oferece um estado de contingência controlado em vez de uma interrupção total do serviço.
Reduzir a dependência de uma única plataforma central
Plataformas centralizadas simplificam a gestão, mas podem se tornar um ponto único de dependência se os sites remotos não tiverem fallback local. Em uma arquitetura normal, registro de terminais, roteamento de chamadas, autenticação, tradução de números e políticas de serviço podem ser tratados pelo sistema central. Se toda ação de comunicação precisar passar por essa plataforma, uma falha de link pode afetar até chamadas locais simples entre dois dispositivos no mesmo prédio.
A sobrevivência local altera esse modelo de dependência. Ela permite que funções locais selecionadas permaneçam disponíveis sob condições predefinidas. Por exemplo, extensões locais podem se registrar novamente em um gateway sobrevivente, ou o gateway pode manter um plano de discagem em cache para chamadas locais. Números de emergência podem ser roteados por troncos locais. Portarias de segurança, equipes de manutenção, salas de controle de produção e terminais de campo podem continuar se comunicando dentro do site mesmo quando o servidor principal não está acessível.
Isso não significa descentralizar tudo. Um bom projeto ainda usa gestão centralizada durante a operação normal porque ela oferece configuração unificada, monitoramento, controle de políticas e manutenção mais simples. A sobrevivência adiciona um segundo estado operacional. O sistema trabalha de forma centralizada quando a rede está saudável e muda para controle local somente quando o caminho central falha.
A vantagem é o equilíbrio. As organizações podem aproveitar a arquitetura centralizada sem aceitar perda total de serviço durante o isolamento de rede. Isso é especialmente valioso em implantações multisite, nas quais cada filial, estação, planta ou nó de campo possui responsabilidades operacionais próprias.
Manter chamadas de emergência quando a rota principal falha
Chamadas de emergência são uma das razões mais importantes para implantar sobrevivência local. Em muitos ambientes, os usuários podem precisar contatar segurança, bombeiros, apoio médico, operadores da sala de controle ou serviços locais de emergência justamente durante incidentes que também prejudicam a conectividade. Se o sistema depender totalmente de uma plataforma central, a chamada de emergência pode falhar quando é mais necessária.
Um nó local sobrevivente pode preservar o roteamento de emergência por números locais, linhas analógicas, troncos SIP, gateways de rádio ou terminais de resposta predefinidos. O desenho depende do site, mas o princípio é o mesmo: a comunicação de emergência deve ter um caminho local que não dependa completamente de infraestrutura distante. Isso é especialmente importante para sites industriais remotos, estações de transporte, instalações subterrâneas, plataformas offshore e ambientes de segurança pública.
A sobrevivência local também ajuda a tornar o comportamento de emergência previsível. Quando a plataforma central está indisponível, os usuários não devem ter que adivinhar quais números ainda funcionam. O sistema deve definir quais números de emergência continuam disponíveis, para onde as chamadas são encaminhadas, como os operadores são alertados e se o roteamento de fallback é automático. Um comportamento claro em condição de falha é mais valioso que um sistema complexo que só funciona em condições normais.
No planejamento de implantação, o roteamento de emergência deve ser testado separadamente das chamadas comuns. Engenheiros devem confirmar se chamadas de emergência ainda conectam durante falha WAN simulada, se a localização ou identidade do dispositivo é preservada quando necessário, se operadores locais recebem a chamada e se os troncos de backup funcionam corretamente. A sobrevivência só faz sentido se o caminho de fallback foi verificado antes de um incidente real.
Apoiar operações locais em sites industriais e remotos
Alguns sites não podem pausar suas operações apenas porque a rede central ficou indisponível. Uma linha de produção ainda pode precisar de coordenação entre a sala de controle e a equipe de campo. Uma estação ferroviária ainda pode precisar de comunicação interna entre plataforma, segurança e manutenção. Uma mina pode precisar de contato de voz entre pontos subterrâneos e supervisão local. Uma subestação pode precisar de comunicação entre operadores e técnicos. Esses são fluxos locais, e muitos devem permanecer disponíveis durante a desconexão central.
A sobrevivência local apoia isso mantendo a comunicação próxima das pessoas e dos dispositivos que precisam dela. Em vez de rotear toda chamada por um data center remoto ou plataforma em nuvem, chamadas locais selecionadas podem ser tratadas dentro do site. Isso reduz a dependência de caminhos longos de rede e oferece à instalação uma capacidade operacional básica em condições degradadas.
Em ambientes industriais, o valor não é apenas a continuidade técnica. Ele também apoia segurança e disciplina de produção. Operadores ainda podem reportar falhas, equipes de manutenção coordenar reparos, equipes de segurança falar com portões ou rondas, e telefones de emergência alcançar posições locais de resposta. O site pode operar em modo reduzido, mas não fica silencioso.
Isso é particularmente útil em locais onde o reparo da WAN pode levar tempo. Sites remotos, gabinetes externos, rotas subterrâneas e linhas alugadas nem sempre são restaurados imediatamente. Uma camada de sobrevivência local ganha tempo para as equipes de reparo e mantém a coordenação interna essencial.
Melhorar a resiliência sem complicar toda a rede
Resiliência costuma ser associada à redundância completa: servidores duplicados, links duplicados, data centers de backup, múltiplas operadoras e sistemas paralelos. Esses desenhos podem ser necessários em redes grandes ou de missão crítica, mas também podem ser caros e complexos. A sobrevivência local oferece um método focado de resiliência, protegendo as funções de comunicação mais importantes do site sem duplicar toda a plataforma central em cada local.
Isso a torna atraente para organizações distribuídas. Uma filial pode não precisar de um servidor de comunicação completo com todos os recursos avançados. Uma estação ou planta pode não precisar de duplicação total da plataforma. O que ela precisa é manter chamadas básicas, roteamento de emergência e acesso a serviços locais durante a desconexão. A sobrevivência mira exatamente esse requisito prático.
A arquitetura pode ser dimensionada conforme o risco. Uma filial de baixo risco pode exigir apenas chamadas locais de emergência e fallback de extensões internas. Uma instalação industrial crítica pode exigir registro local, troncos locais, telefones de emergência, acesso a paging e fallback de console. Uma rede de transporte pode exigir continuidade em nível de estação e reconexão controlada ao centro de comando quando o link retornar.
Ao ajustar a profundidade da sobrevivência à importância do site, as organizações melhoram a resiliência sem criar infraestrutura pesada desnecessária em todos os lugares. O objetivo não é tornar cada site totalmente independente; é garantir que cada site retenha as funções de comunicação de que realmente precisa em condições anormais de rede.
Reduzir o tempo de recuperação após interrupção do serviço
A sobrevivência local pode reduzir o impacto operacional das falhas porque os serviços não colapsam completamente durante o problema. Quando o caminho central é restaurado, o sistema pode voltar do fallback local para a operação centralizada. Essa transição pode ser automática ou controlada, dependendo do desenho da plataforma e dos requisitos do projeto.
Sem sobrevivência, uma falha WAN pode gerar muitos problemas secundários. Usuários tentam chamadas que falham repetidamente, operadores recebem reclamações, o roteamento de emergência fica incerto e equipes de manutenção precisam explicar por que dispositivos próximos não conseguem se comunicar. Recuperar não é apenas restaurar o link; também é restaurar a confiança dos usuários e a ordem do serviço.
Com sobrevivência, o site continua operando em modo limitado, porém organizado. Usuários locais podem perceber que alguns serviços centrais estão indisponíveis, mas a comunicação essencial permanece possível. Quando a plataforma principal retorna, registros, roteamento e políticas podem ser sincronizados de volta ao normal. Isso torna a interrupção mais fácil de gerenciar e menos disruptiva.
O planejamento de recuperação deve incluir o que acontece depois que a falha termina. O sistema deve evitar registros duplicados, confusão de rotas, estados inconsistentes de usuários ou restauração tardia. Equipes de manutenção devem ver quando o site entrou em modo sobrevivente, quais chamadas foram tratadas localmente e quando o modo normal foi retomado. Esses registros ajudam a verificar se o failover se comportou corretamente.
Preservar a experiência do usuário em condições degradadas
Usuários geralmente não pensam em servidores de chamadas, roteamento WAN, registro SIP ou fallback de troncos. Eles esperam que o telefone, terminal de emergência, intercomunicador ou console funcione quando necessário. A sobrevivência local preserva essa experiência mantendo disponíveis as ações de comunicação mais familiares mesmo quando a rede mais ampla está prejudicada.
Por exemplo, um usuário ainda pode discar uma extensão local, contatar a segurança, alcançar a sala de controle ou acionar um ponto de chamada de emergência. O sistema pode estar em modo de fallback, mas a experiência permanece próxima o bastante do normal para tarefas críticas. Isso reduz a confusão e evita que pessoas abandonem procedimentos oficiais por soluções informais.
Preservar a experiência também reduz a carga de treinamento. Se o comportamento de fallback segue padrões de discagem e rotas de resposta familiares, usuários não precisam memorizar um método separado de comunicação para falhas de rede. O sistema deve se adaptar à falha, não obrigar todos os usuários a mudar de comportamento em um momento de estresse.
Porém, nem todo recurso pode ou deve permanecer disponível localmente. Serviços avançados como diretórios centralizados, gravação remota, conferência entre sites, voicemail em nuvem ou roteamento global podem ficar indisponíveis durante o isolamento. Uma boa implantação define claramente quais funções são garantidas localmente e quais dependem do sistema central.
Projetar regras de failover em que os operadores confiem
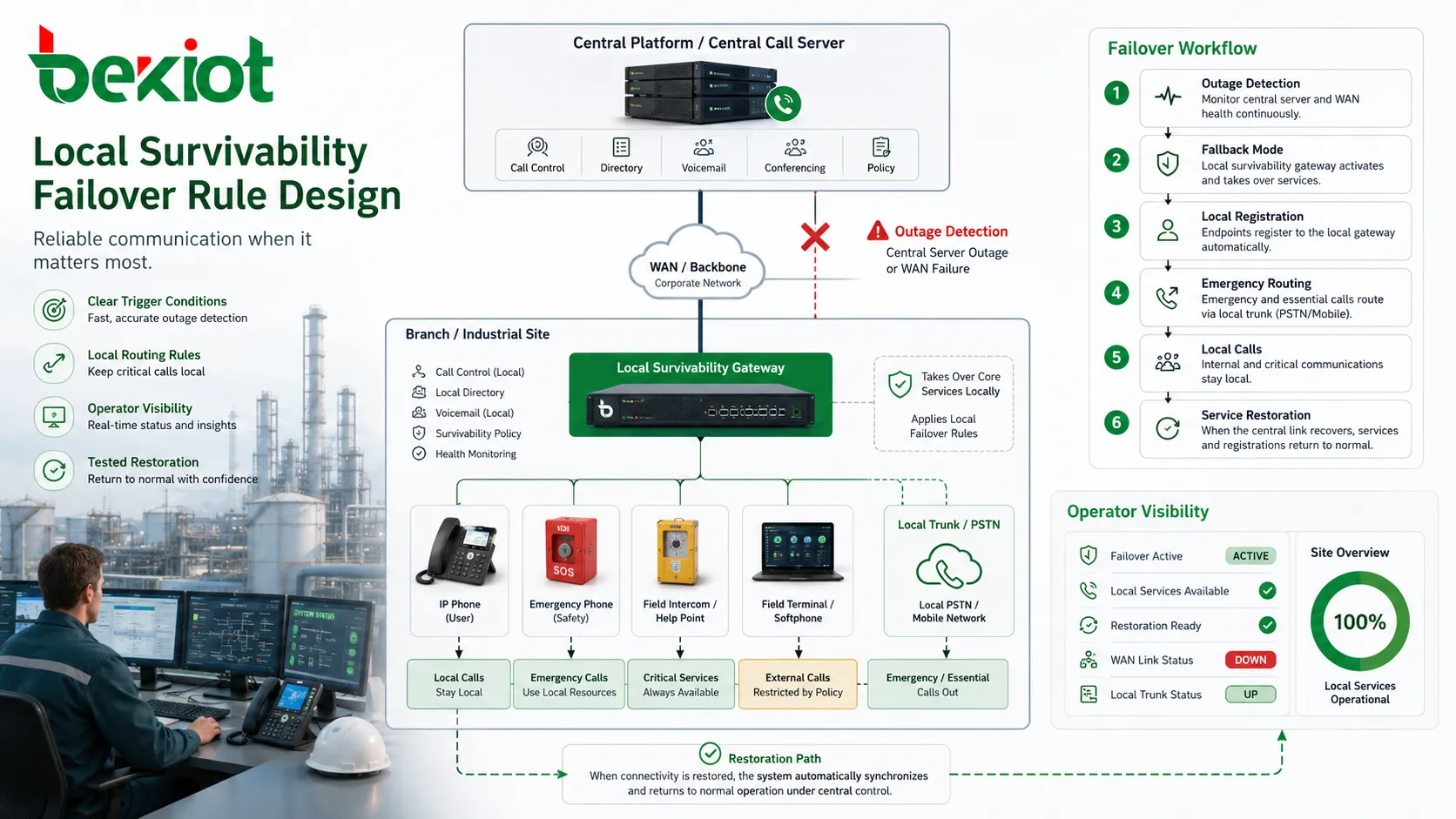
A sobrevivência depende de regras. O sistema precisa saber quando entrar em modo de fallback, quais serviços devem ser assumidos localmente, quais números devem ser roteados por recursos locais e quando a operação normal deve ser retomada. Se essas regras forem obscuras, a sobrevivência pode criar confusão em vez de estabilidade.
As condições de disparo são a primeira questão de projeto. Um site pode entrar em modo sobrevivente quando perde contato com o servidor central de chamadas, quando o registro SIP falha, quando a latência WAN ultrapassa um limite ou quando um tronco primário fica indisponível. O disparo deve ser específico o suficiente para evitar failover desnecessário, mas sensível o suficiente para responder antes de falhas amplas para os usuários.
Regras de roteamento são igualmente importantes. Chamadas locais devem permanecer locais quando adequado. Chamadas de emergência podem ser enviadas a operadores locais ou troncos de backup. Chamadas externas podem ser restritas a números essenciais se a capacidade de tronco local for limitada. Chamadas para outros sites podem ser bloqueadas, redirecionadas ou tratadas por caminhos alternativos. Operadores devem entender essas regras antes de uma interrupção.
A confiança vem de testes e documentação. Se a equipe não sabe o que significa modo sobrevivente, pode achar que o sistema está quebrado mesmo quando funciona corretamente. Indicadores de status claros, logs de manutenção, orientações para operadores e testes regulares de failover ajudam a criar confiança. Um desenho de sobrevivência que ninguém entende não entrega todo seu valor operacional.
Planejamento de implantação para filiais e arquiteturas multisite
A sobrevivência local deve ser planejada conforme o papel do site. Uma pequena filial, grande fábrica, estação de transporte público, prédio de campus, instalação remota de utilidade e ponto de comando de emergência não precisam do mesmo desenho. O primeiro passo é identificar quais funções de comunicação devem permanecer disponíveis se a plataforma central estiver inacessível.
Perguntas-chave incluem: extensões locais ainda devem chamar umas às outras? Chamadas de emergência devem ir para uma mesa local ou tronco externo? Acesso à rede pública é necessário? Paging ou anúncios locais são necessários? Links de rádio ou intercomunicação devem permanecer ativos? Quantas chamadas simultâneas devem ser suportadas? Por quanto tempo o site pode ficar isolado? Essas perguntas definem o tamanho e a função do nó local de sobrevivência.
O desenho de rede também deve ser revisado. Dispositivos locais precisam alcançar o nó de fallback mesmo quando a WAN está caída. Isso significa que comutação local, VLANs, endereçamento IP, comportamento DHCP, dependência de DNS, energia de backup e posição do gateway importam. Um recurso de sobrevivência não funciona se os endpoints locais perdem rede ou energia ao mesmo tempo.
Em implantações multisite, a consistência de configuração é importante. Cada site pode ter suas próprias regras locais de fallback, mas o desenho geral deve seguir um padrão sempre que possível. Modelos padronizados reduzem erros de engenharia e facilitam manutenção. Exceções específicas ainda podem ser adicionadas para locais de alto risco ou finalidade especial.
Valor de monitoramento operacional e manutenção
A sobrevivência local não deve ser tratada como recurso configurado uma vez e esquecido. Seu valor depende de o caminho de fallback local permanecer saudável. Equipes de manutenção devem monitorar gateways locais, troncos de backup, comportamento de registro de endpoints, condições de energia e versões de software. Um nó de sobrevivência offline ou mal configurado pode só ser notado durante uma falha real.
Testes regulares são essenciais. Engenheiros devem simular indisponibilidade do servidor central ou desconexão WAN de forma controlada e verificar se chamadas locais, chamadas de emergência e rotas de fallback se comportam conforme esperado. Esses testes devem ser documentados, especialmente em ambientes onde segurança ou continuidade operacional são importantes.
O monitoramento também deve incluir registros de eventos. Quando um site entra em modo sobrevivente, o sistema deve gerar logs ou alarmes para que as equipes entendam o que aconteceu. Se o failover ocorre com frequência, o problema pode ser instabilidade WAN, alcance do servidor central, limites incorretos ou problemas de rede local. A sobrevivência protege o serviço, mas ativações frequentes indicam uma causa subjacente a corrigir.
Após uma falha real, registros ajudam a avaliar o desempenho. As chamadas locais permaneceram disponíveis? As chamadas de emergência foram roteadas corretamente? Usuários relataram confusão? O sistema retornou limpo ao modo normal? Essas perguntas ajudam a refinar o desenho e melhorar a resiliência futura.
Limitações comuns que devem ser entendidas antes da implantação
A sobrevivência local é valiosa, mas não é o mesmo que duplicação completa do sistema. Alguns serviços centralizados podem não estar disponíveis durante o isolamento. Dependendo da arquitetura, isso pode incluir chamadas entre sites, gravação centralizada, consulta de diretório em nuvem, conferência avançada, voicemail centralizado, filas globais de chamadas ou controle remoto de administrador. Essas limitações devem ser explicadas antes da implantação.
A capacidade também pode ser limitada. Um nó de sobrevivência local pode suportar apenas um número definido de usuários, chamadas, troncos ou recursos. Se o site espera que todos os usuários se comportem normalmente durante uma falha WAN, o sistema de fallback deve ser dimensionado para isso. Se apenas comunicação essencial e emergencial é necessária, um desenho menor pode ser suficiente.
Outra limitação é a consistência de dados. Durante o fallback, alguns registros de chamadas, estados de dispositivos ou mudanças de configuração podem ser armazenados localmente e sincronizados depois, ou podem não estar totalmente disponíveis para a plataforma central. O projeto deve definir como os registros são tratados e quais informações são necessárias para auditoria ou relatórios.
Entender esses limites não enfraquece a defesa da sobrevivência. Torna a implantação mais realista. Os desenhos mais fortes são aqueles que definem claramente o que sobrevive localmente, o que depende do sistema central e como usuários e operadores devem agir durante a operação degradada.
Valor de negócio de longo prazo da resiliência no nível do site
O valor de longo prazo da sobrevivência local vem da redução do risco operacional em ambientes distribuídos. Uma única interrupção pode ser rara, mas quando ocorre o custo pode ser alto. A perda de comunicação pode atrasar manutenção, interromper produção, afetar atendimento ao cliente, enfraquecer resposta de emergência ou criar riscos de segurança. A sobrevivência reduz a chance de uma falha de rede virar uma falha operacional completa.
Para organizações com muitos sites, o valor aumenta ainda mais. Mesmo que cada site tenha problemas ocasionais de conectividade, o risco total na rede pode ser significativo. A capacidade de fallback local cria um modelo operacional mais resiliente, especialmente onde os sites são geograficamente dispersos ou dependem de links WAN alugados.
A sobrevivência também apoia modernização. Organizações podem migrar para plataformas centralizadas ou em nuvem e ainda manter proteção local para sites críticos. Isso torna a migração menos arriscada porque a nova arquitetura não remove toda independência local. Ela combina eficiência centralizada com continuidade no nível do site.
Em termos práticos de implantação, a sobrevivência local não é apenas um recurso técnico. É uma medida de continuidade de negócios, uma camada de apoio à segurança e uma forma de tornar a arquitetura de comunicação distribuída mais tolerante a problemas reais de rede.
Perguntas frequentes
A sobrevivência local é necessária apenas para grandes organizações?
Não. Ela é útil para qualquer site onde a comunicação deve continuar durante falha WAN ou do servidor central. Pequenas filiais, instalações remotas, estações industriais, campus e sites de transporte podem precisar de fallback local se o impacto da perda de comunicação for alto.
A sobrevivência local substitui a redundância central?
Não. A redundância central protege a plataforma principal, enquanto a sobrevivência local protege a comunicação no nível do site quando ele não consegue alcançar a plataforma central. Elas resolvem partes diferentes do problema de resiliência e podem ser usadas juntas.
Quais serviços geralmente permanecem disponíveis no modo sobrevivente?
Serviços comuns incluem chamadas entre extensões locais, roteamento de emergência, acesso a troncos locais, fallback limitado de registro e caminhos essenciais predefinidos. Serviços centralizados avançados podem não permanecer disponíveis a menos que sejam projetados para operação local.
Com que frequência o failover de sobrevivência deve ser testado?
A frequência depende do risco, mas sites críticos devem testar regularmente e após mudanças importantes de rede ou configuração. Os testes devem verificar chamadas locais, rotas de emergência, acesso a troncos, restauração e visibilidade do operador.
Qual é o erro de implantação mais comum?
O erro mais comum é habilitar o recurso de sobrevivência sem projetar todo o fluxo de fallback. O projeto deve definir disparos, roteamento local, comportamento de emergência, capacidade, expectativas de usuários, monitoramento e procedimentos de recuperação antes de depender dele.







