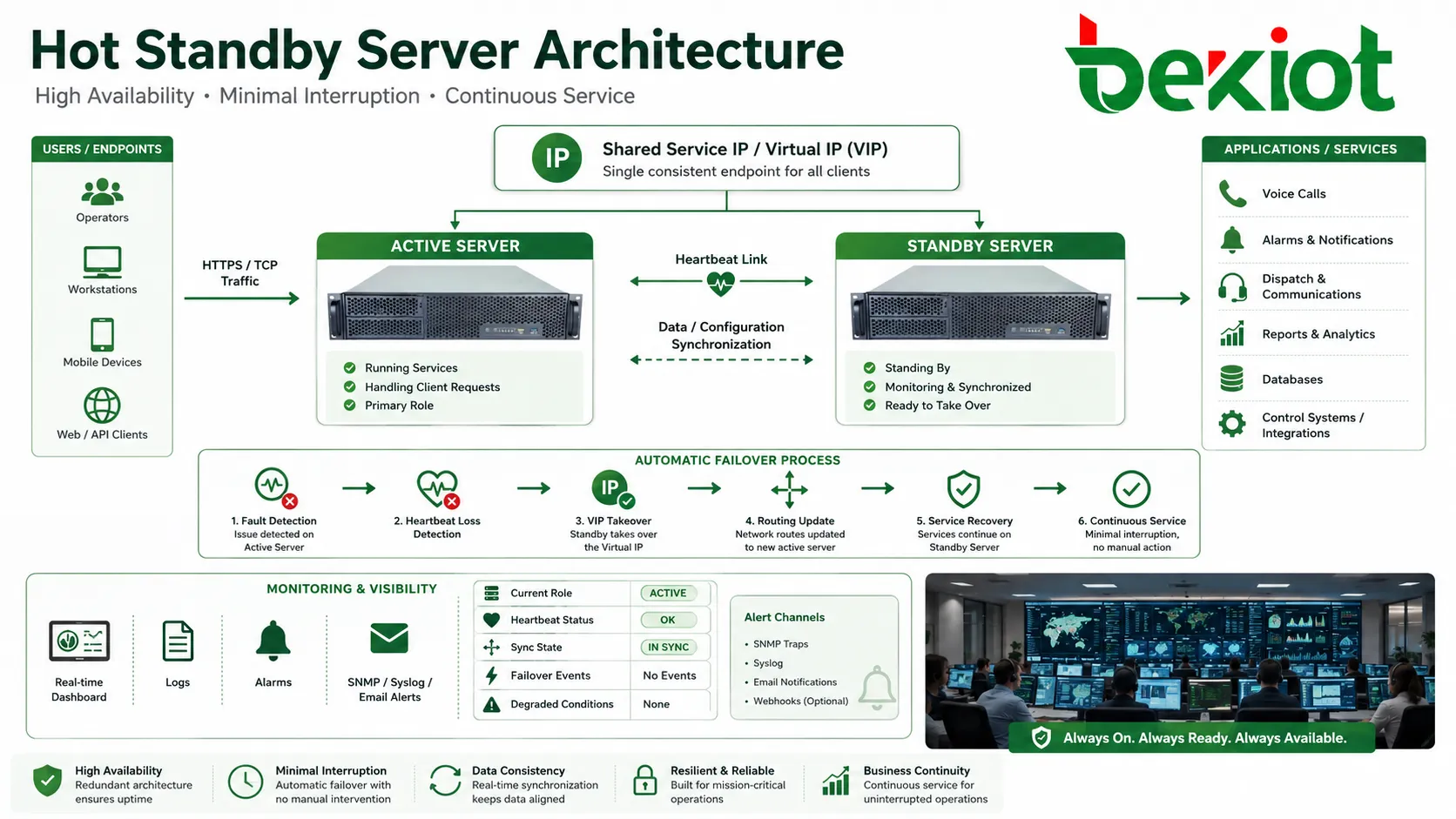
Hot standby é um projeto de alta disponibilidade no qual um dispositivo, servidor, controlador, gateway ou plataforma de reserva permanece energizado, sincronizado e pronto para assumir quando a unidade ativa falha. Em vez de esperar reparo manual ou reinicialização a frio, o lado em espera pode assumir o serviço por failover automático, reduzindo a parada e mantendo a continuidade de sistemas críticos.
Essa função é usada em plataformas de comunicação, data centers, controle industrial, segurança, infraestrutura elétrica, transporte, serviços em nuvem, gateways de telecomunicações, sistemas de emergência e aplicações corporativas. Seu valor central não é apenas ter uma máquina reserva: a unidade em espera precisa estar conectada, monitorada, sincronizada e testada para se tornar ativa quando o nó de produção ficar indisponível.
Do dispositivo de reserva ao desenho de continuidade do serviço
Um backup tradicional pode ficar parado até que ocorra uma falha. O hot standby é diferente porque o elemento de reserva já faz parte da arquitetura em operação. Ele escuta sinais de heartbeat, recebe atualizações de configuração, acompanha o estado do serviço e se prepara para assumir com interrupção mínima.
Para os usuários, o resultado ideal é simples: chamadas continuam, sessões se recuperam, alarmes permanecem visíveis, sistemas de controle continuam disponíveis e operadores não precisam reconstruir o serviço manualmente. Por trás dessa experiência, a arquitetura precisa tratar sincronização de dados, tomada de IP, estado de serviço, atualização de rotas, detecção de falhas e ordem de recuperação.
Em ambientes empresariais e industriais, a alta disponibilidade costuma ser mais importante que o desempenho máximo. Um sistema um pouco mais lento, mas disponível de forma contínua, pode ser mais valioso que um sistema poderoso que para totalmente sem proteção.
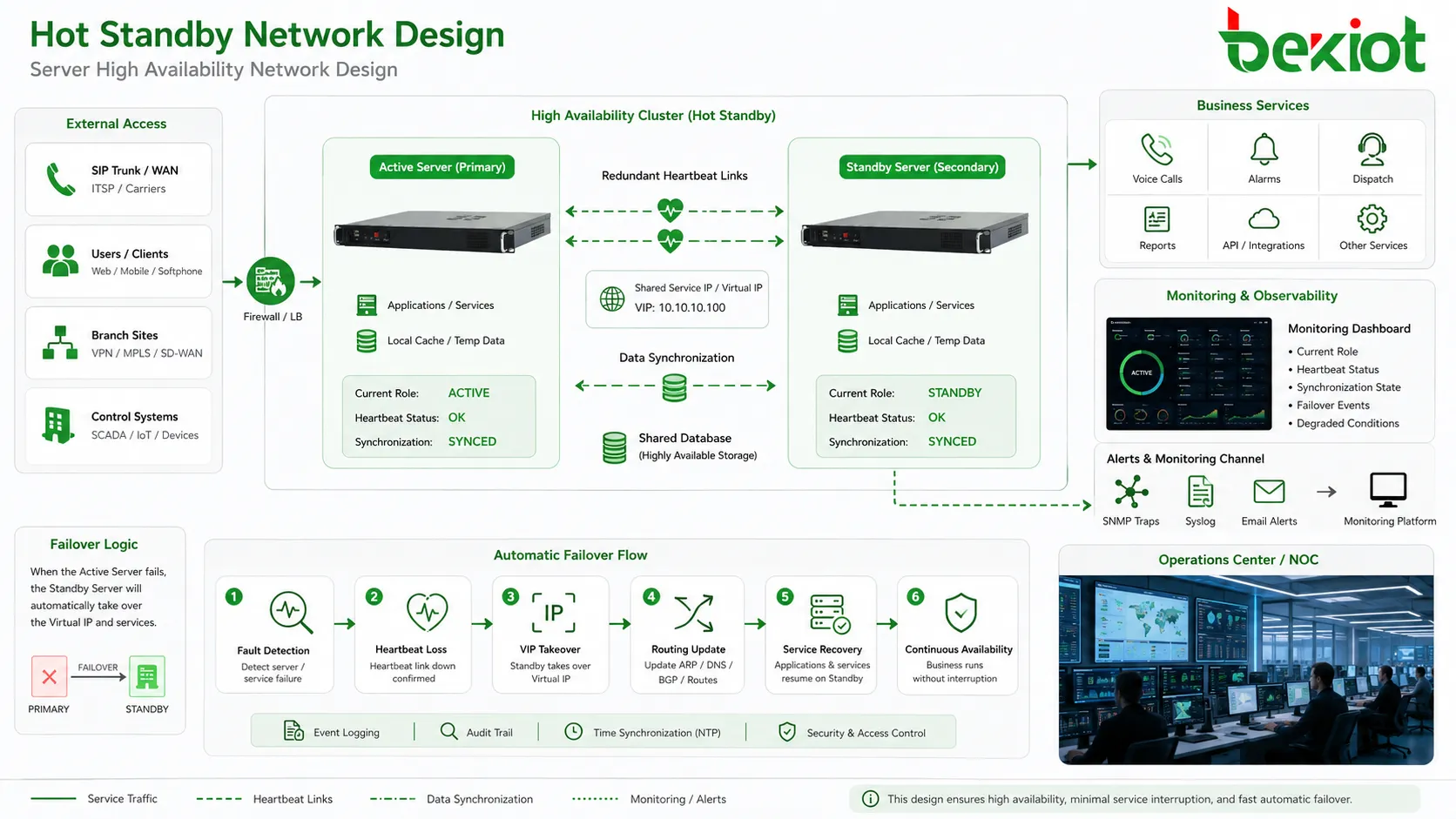
Como funciona o processo de tomada de controle
Detecção por heartbeat
Os nós ativo e em espera normalmente trocam sinais de heartbeat. Esses sinais confirmam que cada lado está vivo e que o nó primário ainda é responsável pelo serviço. O tráfego de heartbeat pode passar por cabo dedicado, rede de gerenciamento, VLAN privada ou caminho de rede redundante.
Se o nó em espera deixar de receber mensagens heartbeat válidas dentro de uma janela definida, ele pode suspeitar que o nó ativo falhou. O sistema inicia então a lógica de failover. Essa lógica deve ser bem projetada, pois reagir rápido demais a um atraso temporário de rede pode gerar failover falso.
Sincronização de estado
Para uma transição suave, o lado em espera precisa de informações atuais, como arquivos de configuração, dados de usuários, tabelas de roteamento, registros de sessão, estados de chamadas, alarmes, entradas de banco de dados, licenças, registros de dispositivos ou lógica de controle.
Alguns sistemas sincronizam apenas configuração, enquanto outros sincronizam o estado de serviço em tempo real. Quanto mais profunda a sincronização, mais suave pode ser o failover. Porém, a sincronização em tempo real também aumenta a complexidade e a dependência da rede.
Decisão de falha
Depois de detectar uma possível falha, o sistema deve decidir se o nó ativo está realmente indisponível. Isso pode envolver perda de heartbeat, estado dos processos, disco, interfaces, resposta do banco de dados, carga de CPU, alarmes de energia ou entrada de monitoramento externo.
Um bom projeto evita decisões baseadas em uma única condição. Por exemplo, perder um link de heartbeat não deve disparar automaticamente a tomada se outro caminho de gerenciamento ainda confirma que o nó ativo está saudável.
Troca de função
Quando o failover é confirmado, o nó em espera muda de papel e se torna ativo. Ele pode assumir um IP virtual, iniciar processos, anunciar rotas, registrar-se em sistemas pares, ativar troncos, assumir o papel mestre do banco de dados ou começar a processar chamadas e alarmes.
O antigo nó ativo pode ser isolado, reiniciado, reparado ou mais tarde retornar como nó em espera. O comportamento de retorno deve ser controlado para evitar conflito de serviço.
Modelos principais de arquitetura
Par ativo-em espera
O modelo mais comum usa um nó ativo e um nó em espera. O lado ativo executa o serviço de produção, enquanto o lado em espera aguarda e se sincroniza. Quando o lado ativo falha, o lado em espera assume.
Esse modelo é relativamente fácil de entender e é muito usado em PBX, firewalls, roteadores, controladores, bancos de dados, appliances de armazenamento e plataformas industriais. Sua limitação é que o recurso em espera pode ficar subutilizado durante a operação normal.
Duplo ativo com lógica de reserva
Alguns ambientes usam os dois nós de forma ativa, mas ainda mantêm failover entre eles. Cada lado pode processar parte da carga em condições normais, e um lado pode absorver mais tráfego quando o outro falha.
Esse desenho melhora a utilização dos recursos, mas exige balanceamento de carga, sincronização, tratamento de sessões e planejamento de capacidade mais cuidadosos. Se cada nó trabalha normalmente perto do limite, pode faltar capacidade de reserva durante a falha.
Redundância baseada em cluster
Sistemas grandes podem usar um cluster em vez de um par simples de dois nós. Vários nós compartilham serviços, monitoram uns aos outros e redistribuem cargas quando um membro falha.
Arquiteturas em cluster oferecem melhor escalabilidade e resiliência, mas são mais complexas para implantar e manter. Elas exigem coordenação mais forte, controle de quórum, verificações de saúde e gerenciamento de configuração consistente.
Proteção geograficamente separada
Alguns sistemas críticos colocam recursos de standby em outro prédio, campus, data center ou região. Isso protege contra perda local de energia, incêndio, inundação, falha da sala de rede ou interrupção em nível de site.
A proteção geográfica melhora a recuperação de desastres, mas introduz desafios de latência, consistência de dados, roteamento de rede e coordenação operacional. Nem todo serviço consegue fazer failover suavemente a longas distâncias.
| Modelo | Melhor aplicação | Principal preocupação de projeto |
|---|---|---|
| Ativo-em espera | Pares simples de alta disponibilidade para servidores, gateways, PBX e controladores. | Uso do recurso em espera e tempo de failover. |
| Duplo ativo | Sistemas que precisam de compartilhamento de carga e redundância ao mesmo tempo. | Reserva de capacidade, distribuição de sessões e controle de retorno. |
| Cluster | Plataformas grandes com vários nós de serviço e cargas escaláveis. | Quorum, sincronização, prevenção de split-brain e complexidade operacional. |
| Proteção remota | Recuperação de desastre e resiliência em nível de site. | Latência, consistência de dados, roteamento de rede e procedimento de recuperação. |
Elementos de rede que determinam a confiabilidade
Caminho de heartbeat
O link de heartbeat deve ser confiável e, de preferência, redundante. Se ele usar a mesma rede instável do tráfego comum de serviço, o nó em espera pode interpretar mal o estado durante congestionamento ou falha de switch.
Em implantações críticas, os projetistas costumam usar dois caminhos de heartbeat, enlaces físicos separados ou caminhos de switches diferentes. Isso reduz a chance de uma única falha de rede causar uma tomada incorreta.
Endereço virtual de serviço
Muitos sistemas usam um endereço IP virtual ou endereço de serviço flutuante. Usuários e sistemas pares conectam-se a esse endereço estável, e não ao endereço físico de um nó. Durante o failover, o endereço migra para o lado em espera.
Esse método simplifica a configuração dos clientes, mas os dispositivos de rede devem atualizar ARP, roteamento, DNS ou tabelas de sessão rapidamente. Uma atualização lenta pode fazer o failover parecer atrasado mesmo depois que o nó em espera já está ativo.
Dados compartilhados ou replicados
Alguns sistemas dependem de armazenamento compartilhado; outros replicam dados entre nós. O armazenamento compartilhado simplifica a consistência, mas pode virar ponto único de falha se não for protegido. A replicação aumenta a independência, porém exige cuidado com atraso, conflito e escritas incompletas.
O método correto depende de o sistema precisar de continuidade de configuração, consistência transacional, integridade de gravações, preservação de sessões ou apenas reinício simples do serviço.
Comportamento de rotas e troncos
Sistemas de comunicação podem conectar-se a troncos SIP, gateways de rádio, gateways PSTN, consoles de despacho, APIs externas, plataformas de monitoramento e endpoints remotos. Esses sistemas externos precisam saber para onde enviar o tráfego depois do failover.
Se o nó em espera se torna ativo, mas troncos, rotas ou registros de pares não são atualizados, os usuários ainda podem perceber interrupção. Os testes devem incluir sistemas a montante e a jusante, não apenas os dois nós locais.
Camada de gestão e monitoramento
A alta disponibilidade deve ser visível aos administradores. Dashboards, logs, alarmes, traps SNMP, syslog, alertas por e-mail ou plataformas de monitoramento devem mostrar papel atual, estado de heartbeat, sincronização, eventos de failover e condições degradadas.
Sem monitoramento, um sistema pode rodar silenciosamente no lado em espera por semanas. Se ocorrer outra falha depois disso, talvez não exista mais proteção restante.
Recursos técnicos importantes
Failover automático
O failover automático permite que o lado em espera se torne ativo sem intervenção manual. Isso é essencial quando o sistema sustenta comunicação em tempo real, alarmes de segurança, operações de controle ou serviço voltado ao cliente.
O limite de failover deve ser ajustado com cuidado. Se for sensível demais, pode ocorrer failover falso; se for lento demais, os usuários podem sofrer indisponibilidade desnecessária.
Comutação manual
A comutação manual permite que administradores movam o serviço de um nó para outro durante manutenção, atualização, teste ou reparo planejado. Ela ajuda na troca de hardware, aplicação de patches ou validação da prontidão do standby.
Uma comutação controlada é mais segura do que esperar uma falha inesperada, porque a equipe pode programar a ação, monitorar o resultado e retornar se necessário.
Controle de retorno
Após reparar o nó ativo original, o sistema deve decidir se o serviço volta automaticamente ou permanece no nó atual até uma janela planejada. O failback automático pode restaurar rapidamente o desenho original, mas também pode gerar nova interrupção.
Muitos sistemas críticos preferem failback manual para que os operadores verifiquem saúde, sincronização e tráfego antes de mover o serviço novamente.
Prevenção de split-brain
Split-brain ocorre quando os dois nós acreditam estar ativos ao mesmo tempo. Isso pode causar serviços duplicados, conflito de banco de dados, erros de roteamento de chamadas, conflito de IP ou corrupção de dados.
Métodos de prevenção incluem quórum, nó testemunha, fencing, regras de prioridade, links de heartbeat redundantes e controle rigoroso de papéis. A proteção contra split-brain é uma das partes mais importantes de qualquer projeto de alta disponibilidade.
Proteção da integridade dos dados
Durante o failover, o sistema deve proteger dados de configuração e operação, incluindo transações de banco de dados, registros de chamadas, logs de alarmes, estado de registro de dispositivos, gravações e histórico de eventos.
A integridade dos dados é especialmente importante quando o sistema oferece suporte a conformidade, faturamento, registros de emergência, logs de despacho ou trilhas de auditoria.
Onde esse desenho é utilizado
Plataformas de comunicação empresarial
Servidores PBX, plataformas SIP, correio de voz, servidores de gravação, contact centers e plataformas de comunicações unificadas podem usar proteção standby para manter chamadas empresariais. Se o servidor ativo falhar, o lado reserva pode continuar processando registros, chamadas, regras de roteamento e lógica de serviço.
Em projetos de comunicação crítica, a Becke Telcom aplica o pensamento de alta disponibilidade ao planejamento de sistemas de comunicação, ajudando clientes a considerar redundância de servidores, continuidade de gateways, disponibilidade de despacho e caminhos de failover no desenho geral.
Controle industrial e SCADA
Sistemas industriais costumam usar controladores em standby, servidores SCADA redundantes, gateways de comunicação duplos e estações de operador reserva. Esses sistemas apoiam produção, segurança, energia, utilidades e monitoramento de processos.
O failover deve ser testado em condições reais de processo. Um sistema de controle que alterna papéis corretamente em laboratório pode se comportar de forma diferente quando conectado a dispositivos de campo, PLCs, historiadores, alarmes e consoles de operação.
Sistemas de segurança e vigilância
Servidores de vídeo, plataformas de controle de acesso, servidores de alarme, nós de armazenamento e sistemas de sala de controle podem exigir proteção standby para evitar pontos cegos ou atrasos na resposta de segurança.
Nesses ambientes, o desenho de failover deve considerar vídeo ao vivo, continuidade de gravação, controle de portas, reconhecimento de alarmes, logs de eventos e permissões dos operadores.
Data centers e serviços em nuvem
Servidores, bancos de dados, firewalls, balanceadores, storages, roteadores e plataformas de aplicação frequentemente usam arquitetura de alta disponibilidade. A proteção standby pode existir na camada de hardware, virtualização, contêiner, banco de dados ou aplicação.
Quanto mais camadas envolvidas, mais importante é definir qual delas é responsável pelo failover. Múltiplos mecanismos independentes podem entrar em conflito se não forem planejados cuidadosamente.

Segurança pública e transporte
Centros de resposta a emergências, ferrovias, salas de controle de túneis, operações aeroportuárias, centros portuários e plataformas de tráfego exigem alta disponibilidade. Falhas de comunicação podem atrasar resposta, reduzir consciência situacional ou interromper coordenação.
Nesses sistemas, a redundância deve cobrir não só servidores, mas também energia, switches, troncos, endpoints, estações de operador e interfaces externas.
Benefícios além da redução de indisponibilidade
O benefício mais evidente é a continuidade do serviço. Quando o nó primário falha, os usuários continuam trabalhando com menos interrupção, algo importante para voz, alarmes, monitoramento, acesso a dados e funções de controle.
Outro benefício é a flexibilidade de manutenção planejada. Administradores podem mover o serviço para o standby, manter o nó original e restaurar o papel normal após verificação, reduzindo janelas longas de parada.
O desenho standby também aumenta a confiança em atualizações. Se uma atualização causar problema em um lado, a organização pode ter um caminho controlado para recuperar o serviço, desde que a arquitetura e o plano de rollback estejam corretos.
Para equipes de gestão, a alta disponibilidade apoia o controle de risco. Ela transforma a falha de um único dispositivo de uma interrupção total em um evento gerenciado que pode ser investigado e reparado com menor impacto.
Cenários práticos de falha
Falha de hardware
Um servidor, fonte de alimentação, disco, placa de interface, gateway ou controlador pode falhar. O nó em espera deve detectar que o serviço ativo não está saudável e assumir conforme a política configurada.
Falha de hardware é geralmente o cenário mais fácil de entender, mas nem sempre é a causa mais comum de interrupção de serviço.
Queda do processo de aplicação
A máquina pode continuar ligada enquanto a aplicação de serviço parou de responder. Uma boa verificação de saúde deve detectar não apenas se o servidor está vivo, mas se o serviço realmente funciona.
Verificar apenas resposta a ping normalmente não basta. O sistema pode responder ao ping enquanto o motor de chamadas, banco de dados, processo de alarmes ou serviço web falhou.
Isolamento de rede
Um nó pode ficar isolado dos usuários e ainda acreditar que está saudável. Isso é perigoso porque o sistema pode não saber qual lado deve ficar ativo.
Caminhos de rede redundantes e lógica de quórum ajudam a evitar decisões incorretas durante eventos de isolamento.
Corrupção de banco de dados
Se dados forem corrompidos no lado ativo e a corrupção for replicada imediatamente para o standby, a redundância sozinha pode não resolver. Backup e recuperação por versões continuam necessários.
Alta disponibilidade não é o mesmo que backup. Um nó standby protege a continuidade do serviço, enquanto o backup protege a recuperação histórica.
Erro do operador
Configuração incorreta, exclusão acidental, roteamento errado ou atualização mal-sucedida podem afetar os dois nós quando a configuração é sincronizada automaticamente.
Controle de mudanças, fluxo de aprovação, exportação de configuração e planos de rollback são essenciais para reduzir o impacto de erro humano.
Alta disponibilidade reduz paradas por falha de componentes, mas não substitui backup, cibersegurança, controle de mudanças, monitoramento ou manutenção disciplinada.
Estratégia de teste e aceitação
O failover deve ser testado antes da entrega em produção. O teste deve confirmar que o standby detecta a falha, assume o serviço, atualiza caminhos de rede, restaura conexões externas, preserva dados necessários e gera alarmes adequados.
Os testes devem incluir comutação planejada, desligamento do nó ativo, falha de processo, falha de link, queda de energia quando seguro e recuperação após reparo. Cada teste deve definir o comportamento esperado e a interrupção máxima aceitável.
Os registros de aceitação devem incluir tempo de failover, resultado de consistência dos dados, disponibilidade do serviço, alarmes, evidências de logs, confirmação do operador e pendências. Sem registros, o sistema pode parecer redundante sem estar comprovado.
Diretrizes de operação e manutenção
Monitore continuamente o estado standby. Um nó em espera ligado, mas fora de sincronização, não está pronto. Administradores devem observar heartbeat, atraso de replicação, recursos, serviços, licenças, armazenamento e consistência de versões.
Mantenha os dois lados atualizados com cuidado. Diferença de versão pode causar falha de failover ou comportamento inesperado; por isso, atualizações devem ser escalonadas e testadas para não quebrar os dois nós ao mesmo tempo.
Realize exercícios periódicos de comutação. Um sistema nunca testado em condições controladas pode não funcionar durante uma falha real, e os exercícios ajudam operadores a entender procedimento e tempo de resposta.
Revise logs após cada failover. Mesmo que o serviço pareça normal, a causa deve ser investigada; eventos repetidos podem indicar instabilidade de rede, sobrecarga, degradação de hardware ou limiares de saúde mal definidos.
FAQ
Hot standby é o mesmo que backup?
Não. Um nó standby é usado para continuidade do serviço, enquanto backup é usado para recuperação de dados. Um sistema normalmente precisa dos dois, porque o failover não recupera versões antigas de dados corrompidos ou apagados.
Quão rápido deve ser o failover?
O tempo aceitável depende da aplicação. Voz, controle, alarmes e segurança pública geralmente exigem recuperação mais rápida que relatórios ou sistemas de arquivo comuns.
Um sistema em espera protege contra bugs de software?
Apenas em alguns casos. Se o mesmo bug existir nos dois nós, o failover pode não resolver. Controle de versão, testes, rollback e backup continuam importantes.
O que causa split-brain?
Split-brain costuma ser causado por perda de heartbeat, isolamento de rede, quórum fraco ou regras de failover incorretas. Ele acontece quando mais de um nó acredita que deve estar ativo.
O que verificar depois de um failover?
Depois de um failover, verifique papel ativo, saúde do standby, sincronização, logs de serviço, impacto nos usuários, integridade dos dados, estado de trunks ou interfaces externas, alarmes e causa raiz.